
毎月 2 億人のユニークビジターの職探しをお手伝いする中で、私たちは、沢山のデータを手にします。集めたデータからユーザーの動向について多くの情報を得ることができますが、殆どの場合、この動向には予測可能なパターンが見受けられます。しかし、予期せぬ変化はシステムの不具合の兆候や、ユーザーの動向が実際に変化してきている事を表している可能性があります。データが何か変わったことを示していたら、私たちはその原因の解明に努めます。
そんな、ユーザー動向の異常を発見し対応する、というのは入り組んだ問題です。これらの異常が検知しやすくなるように、私たちは複数のオープンソース・ソフトウェアを活用しています。その中で最も重要なものは、 Twitter のAnomalyDetection ライブラリです。
ユーザー動向の異常を観察
大量のデータの中で異常を検知するというのは、時系列に沿って一定の予測可能なパターンがみられるデータの場合には、簡単な話です。図1の例のように、掲載された求人情報のPV 件数が一定の範囲に収まっていたならば、外れ値を見つけるのは簡単です。
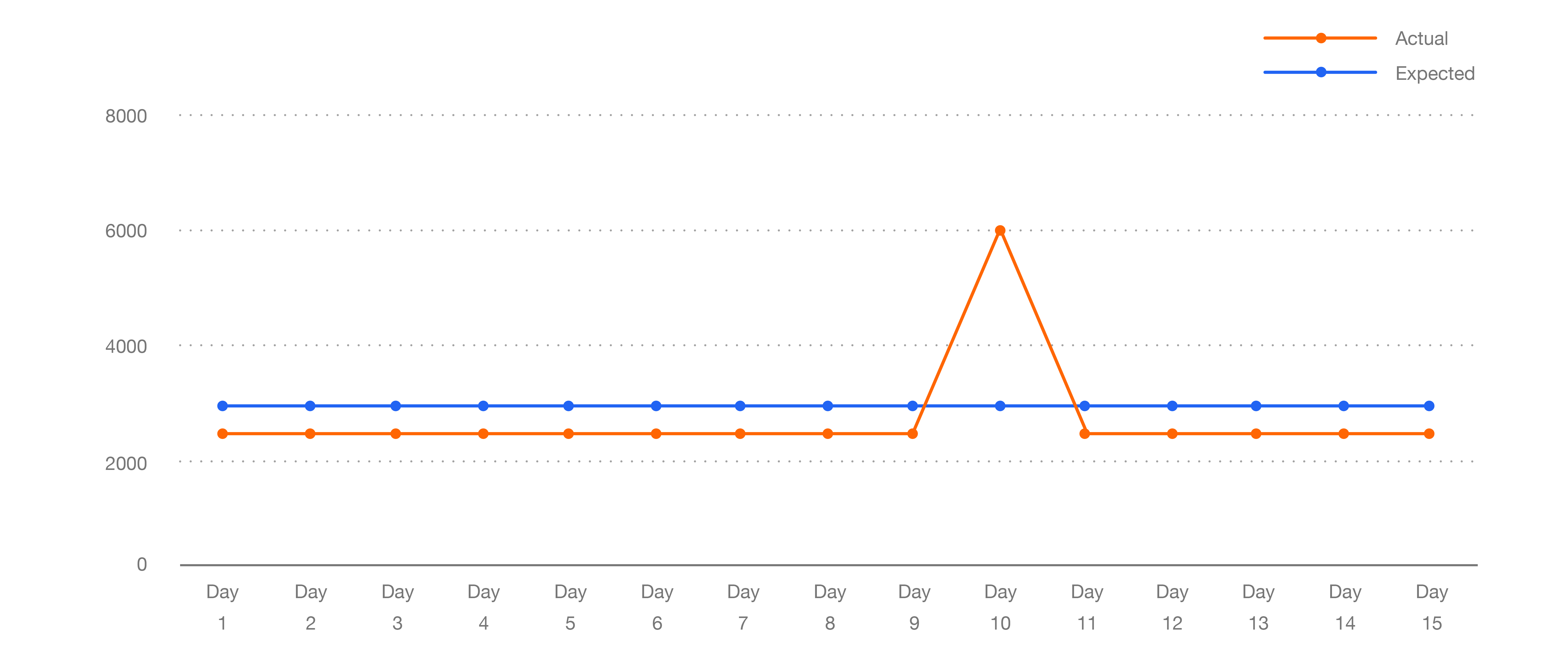
図 1 単一の外れ値
集めるデータのほとんどはユーザー動向によって決定されますが、そのデータのパターンは私たちが簡単に観測できるようなものではありません。様々な要因がユーザー動向に影響を与えているのです。例えば、以下に示す各要因は、ユーザーの所在地によっては、私たちが「通常」範囲と考える PV 件数に影響する可能性があります。
- 何曜日か
- 何時か
- 祝日かどうか
私たちは、いくつかの要因に関しては事前に理解できているかもしれません。または、データ分析後に理解するかもしれません。もしくはよく理解できないまま終わるものもあるでしょう。
私たちの異常検知アルゴリズムは可能な限り多くの変化を把握しなければいけませんが、統計的に有意な外れ値を検出できるくらい、正確であるべきなのです。単純に、「月曜の朝のトラフィックはだいたい他よりも高め」と言うのでは曖昧すぎます。どれくらい他より高いのでしょうか。そして、どれくらいの時間それが続くのでしょうか。
図 2 は、予想されるデータの変動範囲を示し、図 3 は実際のデータの範囲を示しています。実際のデータ内の異常値は、すぐには目に見えません。
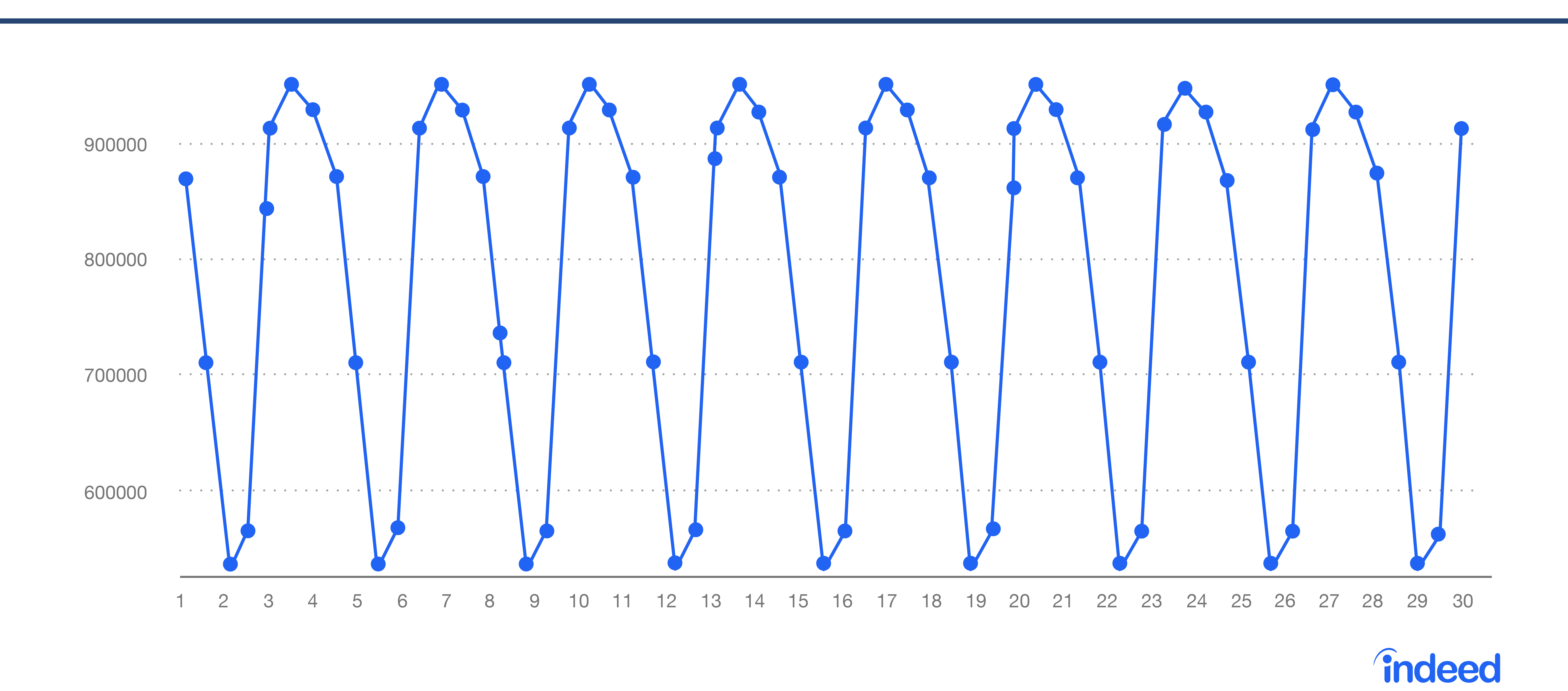
図 2 予想されるデータ
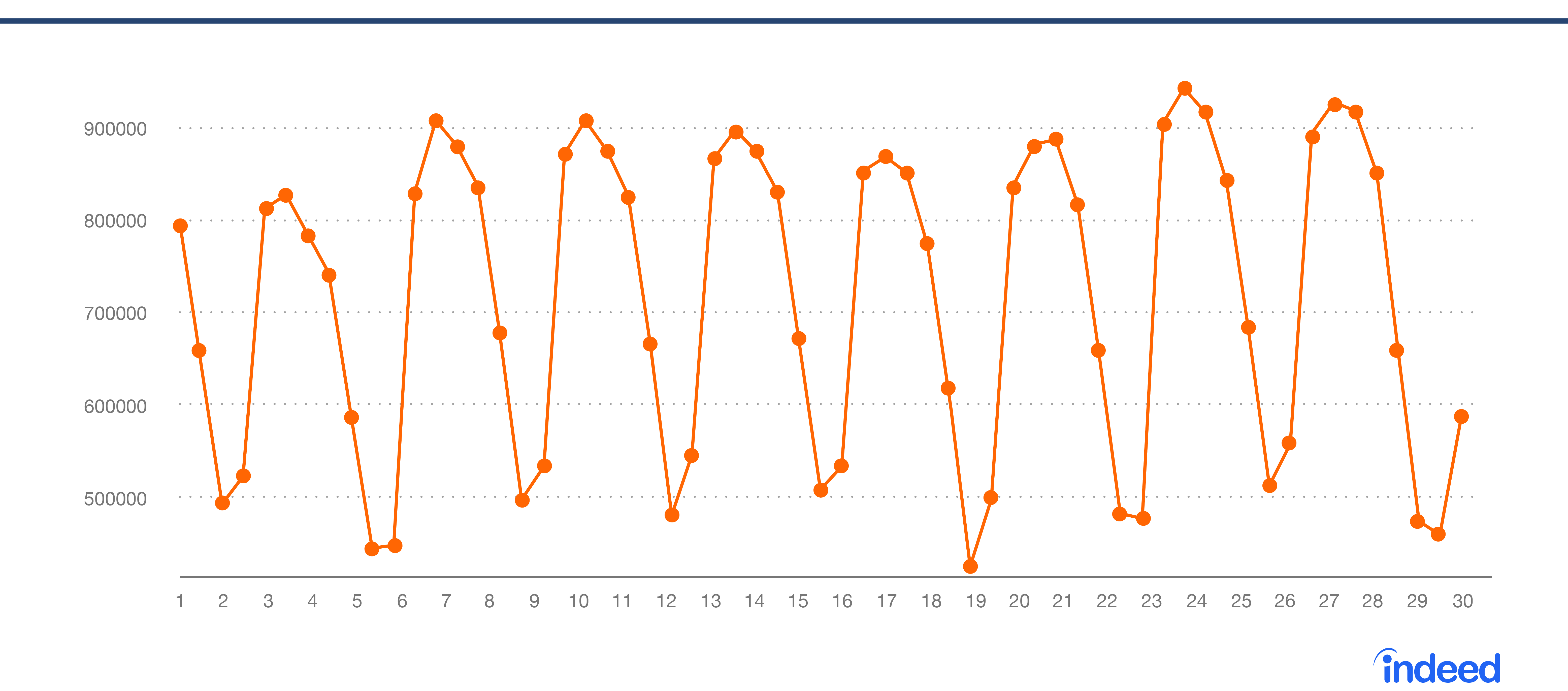
図 3 実際のデータ
図 4 は、実際のデータと予想データを重ねて示したものです。図 5 は、二つの時系列データの差異です。こうやってデータを見ることで、この一連のデータの最後のデータ点が、著しく異なっていることが目立ってくるのです。
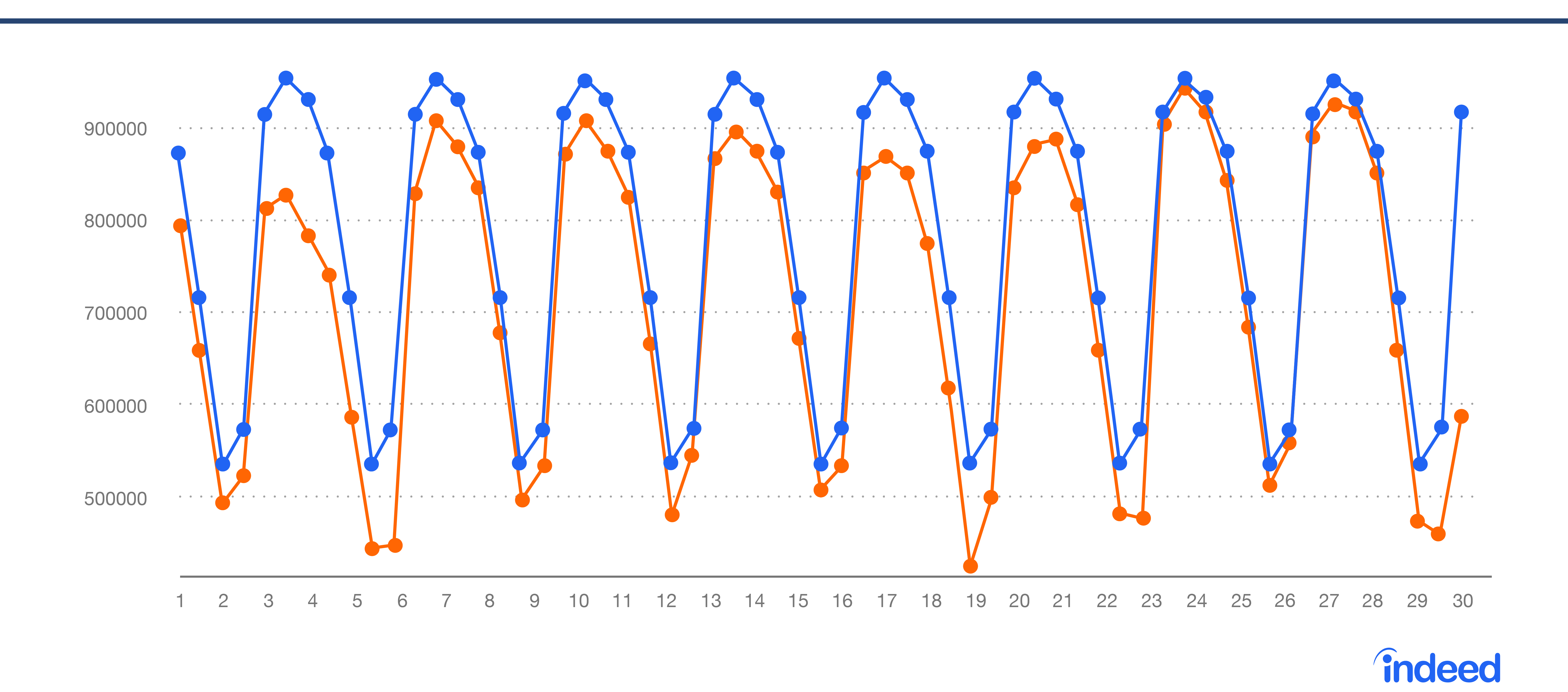
図 4 実際のデータと予想データ
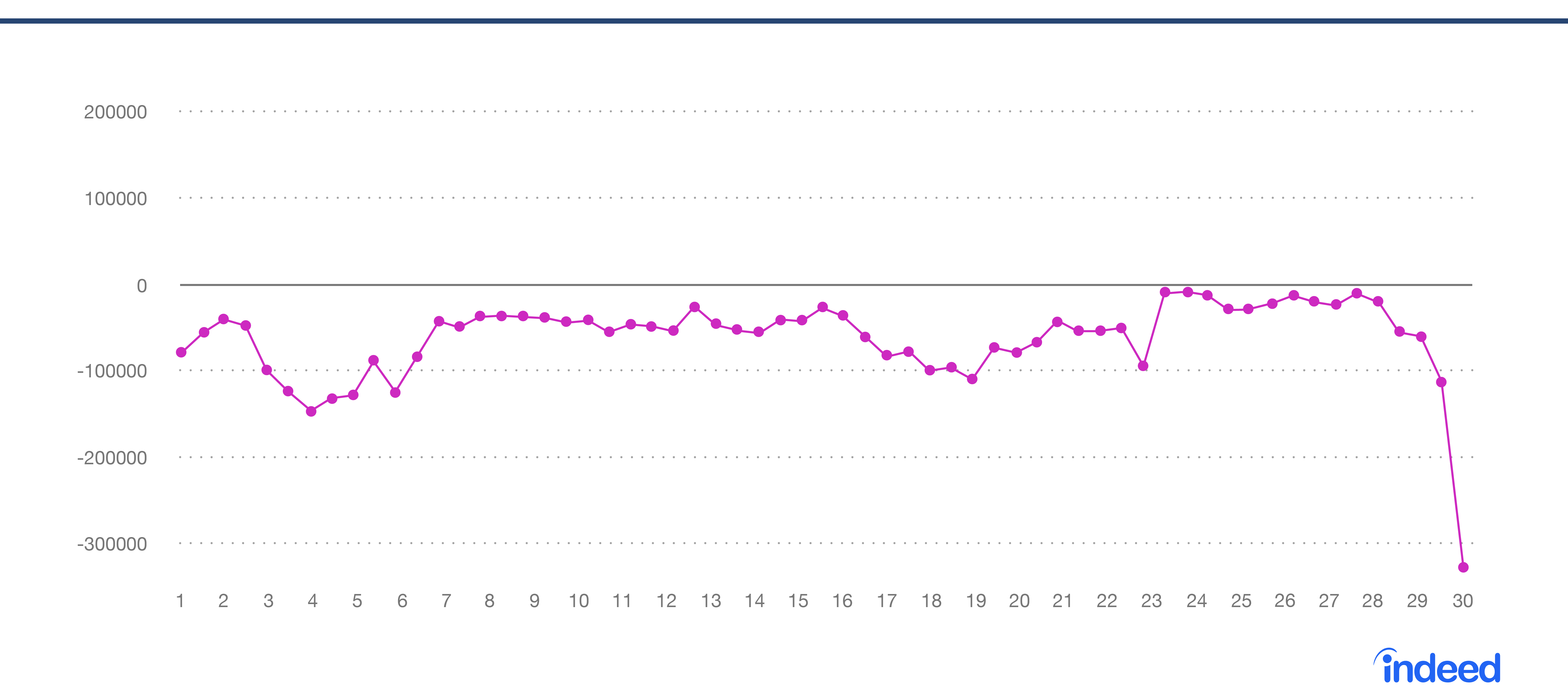
図 5 実際のデータと予想データの差異
こうした異常値を素早く識別し報告できるような洗練された方法を、私たちは必要としていました。その方法は、未来のデータを予測するために、既存のデータを分析できるものである必要がありました。そして、対応しなければいけない異常を見落とさないように、正確である必要もありました。
ステップ 1 :統計的な問題を解決
難しい数学的な部分は、実際には簡単でした。なぜなら Twitter が既に問題を解いてくれており、彼らの AnomalyDetection library をオープンソース化してくれていたからです。
以下はプロジェクトの説明からの引用です。
「AnomalyDetection は異常検出のためのオープンソース R パッケージです。このパッケージは、統計的な観点から見て、季節性やトレンドなどが存在するデータに対しても頑健性があります。AnomalyDetection のパッケージは様々な種類の文脈で使用が可能です。例えば、新しいソフトウェアをリリースした後のシステム指標や、A/B テスト後のユーザーエンゲージメントにおける異常値の検出の他、計量経済学、金融工学、政治学、社会学などの分野の問題に利用できます。」
このライブラリを作成するために Twitter は、Grubbs 検定としても知られている、ESD( extreme studentized deviateの頭文字)検定をベースにして、改良を加え、ユーザー動向のデータを処理できるようにしたのです。本来は、このテストは外れ値を識別するために、データセットの平均値を使用していました。Twitter の開発者達は、中央値を使用する方が、Webで使用する場合にはより正確だと気づいたのです。なぜならユーザー動向は、時間の流れと共に変動する可能性があるからです。
結果的に、トレンドが変動するような時系列データにおける異常値を、素早く検出することのできるツールを作ることができました。Twitter のデータサイエンティスト達は、このデータを使用して、内部分析とリポートを行っています。例えば、毎秒のツイートと内部サーバーの CPU 使用量について、彼らはリポートするのです。
Twitter のライブラリは、私たちが、過去のデータを使用し、様々な非常に複雑なユーザー動向を推測し、素早く異常な動向を見つけ出せるようにしてくれました。ただ、そこには一つ問題がありました。Twitter は R でライブラリを作成していたのですが、私たちの内部のアラートシステムは、Python で実装されているのです。
私たちは、Twitter のライブラリが自分たちのコードで直接動作するように Python に移植することを決めました。
ステップ 2 :ライブラリの移植
もちろん、一つのプログラミング言語から、別言語へコードを移植することは、常にリファクタリングと問題の解決を伴います。AnomalyDetection ライブラリを移植する作業の殆どで、R と Python で提供されている数学関数の違いに対して取り組みました。
Twitter のコードは Python では元々対応していない複数の数学関数に依存しています。
最も重要なものはSTL(Seasonal and trend decomposition using loess の頭文字。)と呼ばれるアルゴリズムで、これは時系列データを季節変動、長期変動(トレンド)、不規則変動に分解します。
私たちは、オープンソースの pyloess ライブラリ からSTL を組み込むことができました。Twitter のコードに使用されている数学関数の多くは、 numpy や scipy といったライブラリに用意されていました。このおかげで、未対応の数学関数はわずかになったため、R で書かれたコードを読んで、Python でその機能を再現することで、直接私たちのライブラリに移植しました。
オープンソースのコミュニティの仲間達が貢献してくれた、優秀な仕事を活用することで、コードの移植に必要とされる労力をぐっと抑えることができました。pyloess や numpy、scipy などのライブラリを使用して、Twitter で使用している R の数学関数を再現することで、この殆どの作業を、一人の開発者が約一週間で終えることができました。
Python 用 AnomalyDetection
オープンソース化
私たちがオープンソースのコミュニティに参加するのは、エンジニアとして、第三者の仕事から学び応用していく価値を理解しているからです。なので、 Python 用 AnomalyDetection をオープンソースとして公開できて本当に嬉しいです。是非ダウンロードして、試していただければと思います。ご質問、ご不明な点は GitHub や Twitter 上にてご連絡ください。