
膨大なデータを抱えるアプリケーションをスケールする際に、どのようなストレージを導入するべきなのでしょうか?どうしたら大量のデータセットを安全に保存し、効率的に読み書きを行えるのでしょうか?こうした疑問は、よく SQL か NoSQL のどちらを使うべきかという議論になりがちですが、どちらもそれぞれメリットとデメリットがあります。
ですが、もしデータデースにまつわる問題を全て回避できる三番目の選択肢があるとしたらどうでしょうか?
コンシューマは数分おきにしか更新を必要としていないかもしれません。この場合、データセットをメモリ内に読み込めると、劇的にアクセス速度があがり、大規模のスケールが可能になります。このことから、 Indeed では多くのプロジェクトで、必要なデータの完全なコピーを、各コンシューマに渡しているので、 SQL 対 NoSQL の議論をする必要がありません。これを実現するにあたり、私たちは最小完全ハッシュ関数に基づく新しいキー・バリューストアを作り、データサイズを管理しています。私たちは、 Indeed MPH と呼ばれる Java ライブラリとして、このストアを実装しました。
データ配布の課題
一般的に、データの全コピーをコンシューマに渡すのは実現が難しいのですが、それには理由が二つあります。一つは、データがほぼ読み取り専用(read-only)である必要があること、もう一つは、配布や処理を防いでしまうほどデータが大きくてはいけない、ということが課題にあげられます。
一つ目の課題は、バッチの更新を実装すれば解決できます。毎日、毎時間、もしくはもっと頻繁にデータを再配布させれば、データの有用性を保ちつつ 読み込み専用として維持できるでしょう。けれど、サイズを小さく留めておくにはどうすればいいのでしょうか。分かったことは、二つ目のサイズの課題に対しても同じようにバッチ更新の方法で対処できる、ということでした。
最小完全ハッシュ関数(Minimal perfect hash functions, MPH)
読み込み専用のデータセットを生成するということは、事前に自分のデータセットのキーを全て把握しているということです。これは、データセットのサイズを削減する最適化を可能にします。ハッシュテーブルの場合は、完全ハッシュ関数の計算が出来るようになります。
完全ハッシュ関数は、すべての要素を相異なる整数に衝突なくマッピングします。数学用語では単射と呼ばれます。 最小完全ハッシュ関数 は n 個のキーを 0 から n-1 までの n 個の連続した整数にマッピングします 。こうした構造は、テーブルを 100% 活用している状態を維持しながら、一回のディスクシークで参照できるようにします。他にもまだメリットはあるので、後ほど述べたいと思います。
こうしたハッシュ関数を見つけるのは難しく、事実、誕生日のパラドックスは、ハッシュの範囲がキーの個数の何倍も大きい場合でも全くキーが衝突しないというのはありえにくいとしています。けれど、最近の研究の成果のおかげで、効率的なテクニックや質の高いライブラリを使用して、最小完全ハッシュ関数を生成できるようになりました。これらのテクニックは、小さな不都合はあったものの、私たちのメソッドを成功させました。結果として生成されたハッシュ関数自体が、キーごとに ~2.2 ビット の探索テーブルを必要とするので、定数サイズにはならないのですが、この探索テーブルはブルームフィルタのサイズの一部くらいしかないため、 100 万件のエントリに対し 26MB 程度を必要とするだけなのです。実用上では、この探索テーブルのサイズは保存されたデータのサイズに比べれば、取るに足らないものと言えます。
実用性
MPH は、キーから 0 から n-1 の整数へのマッピングを提供しますが、やはり実際のテーブルを実装する必要があります。メモリ内にテーブルを保存する場合は、通常配列の形でデータを保存します。これをオフラインのストレージに変換するためには、プログラミング言語の配列が暗黙のうちに設定しているメモリーオフセットを明示的に作らなければいけません。私たちの表現は 3 つのファイルを持つディレクトリでした。
- data.bin: raw のシリアライズされた key/value のペア
- offsets.bin: data.bin 内のデータの(一定サイズの)オフセット配列。i 番目の値がハッシュ値が i であるエントリのオフセットに対応する。
- meta.bin: シリアライズされたハッシュ関数そのものとその他の必要なメタデータ
以下の図は、色から動物へのマップを持つ場合の、このデータ表現を表しています。
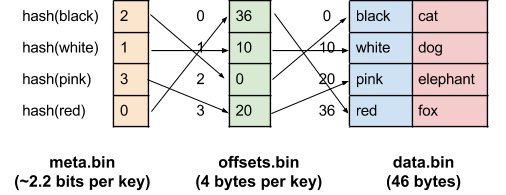
この表現の便利な部分は、 data.bin が、ハッシュ関数に依存することなく、そのままイテレートできる生データであるということです。加えて、キーがユニークでさえあれば、同じ data.bin を異なるキーでインデックス化するような複数のハッシュ関数を構成することも出来ます。
この表現のデメリットは小さなエントリが沢山存在するときに顕著になります。この場合は、オフセットのサイズはデータ自体と同じ位かさらに大きくなります。極端な例をあげると、データに 4 ビット整数から半精度浮動小数点数(half-precision float)への 7 億 5000 万個のマッピングが含まれる場合、 data.bin は 7.5e8 * 6 = ~4.2G になりますが、 offsets.bin にはなんと 7.5e8 * 8 = ~5.6G も必要になるのです。この例では、全てのエントリが一定のサイズである点を活かすことができ、オフセットを保存することなく、 data.bin に直接インデックス化できるのです。けれど、サイズが可変の場合も最適化したいと考えました。
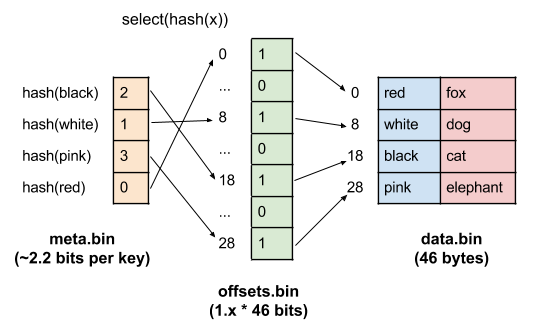
こうした高いコストは、小さなエントリを扱う際に特に発生するものです。もしエントリが大きい場合、オフセットのサイズは、それに比べれば取るに足らないものでしょう。合計サイズが小さいので、1 エントリにつきバイトではなくビットのオーダーで rank 辞書 として表現することが可能です。もう少しオーバーヘッドを大きくして良い場合は、同一のデータ構造上での定数時間で、 select と呼ばれる rank の逆関数を計算することができます。何故これが便利なのでしょうか?もし、この辞書で data.bin の中の全エントリの開始バイトの集合を表すことにするならば、 i 番目のエントリのオフセットを見つけるには、 select(i) を計算すれば良いのです。
この構造は以下のようになります。この場合は、ハッシュ値で data.bin をソートする必要があります。
更に最適化するためのヒントは、データ内のまさに通常の構造の中にしばしば存在します。例えば、 long を long のリストへ(1つのバイトをカウントに使用して)マッピングする場合、 ( key と valueを含む) 個々全てのエントリiのサイズは、リストの長さが xi だと仮定すると 8xi + 9 として表すことができます。k 番目のエントリのオフセットは ∑(8xi + 9) = 9k + ∑8xi = 9k + 8x となります。言い換えると、保存しなければいけないのは、 x だけなのです。これは実際のオフセットよりもずっと小さいので、 select を使ったアプローチを利用すると大きな削減となります。この場合は、リスト内に平均 2 つの要素を持つ 1000 万件のエントリがある場合、その data.bin のサイズは 10000000 * (9 + 16) = ~250Mになり、圧縮された select の手法は ~2.5M に収まります。
私たちの実装はオフセットの配列と select の手法両方のサイズがどうなるか計算し、適した方を選択するようになっています。
さらなる最適化
キーを捨てよう!
衝突する値もなく、私たちの探しているキーはテーブルの中にあると分かっていれば、キーの存在を検証する必要はありません。かわりに、値そのものや、値を元にして他のソースからキーを検証できるかもしれません。そして最後に、低い確率で誤検出をしてもよいならば、キーがテーブル内にあるかどうかをブルームフィルタを使用して、確率論的に検証することが可能になります。
もう一つこれよりも良い選択肢に、元のキーの集合の中では衝突しないような固有のハッシュを既に計算したので、キーの k ビットの署名(どんな一般的なハッシュの下位ビットでも可)を保存する方法があります。同じハッシュ値になるような元の集合にないキーは、2^(-k) の確率でしか署名が一致しません。これはブルームフィルタを使用するときよりも、ずっとマシなエラー率です。
これら全ての場合において、テーブルからキーを削除することができます。値が小さければ、キーはテーブルの大きな割合もしくは過半数を占めている可能性があります。
キーでなくハッシュでリンクさせる
あるテーブルの値が他のテーブルの外部キーになっている、または外部キーを含んでいるなど、複数のテーブルを一緒にリンクさせたい状況はよくあると思います。
MPH 関数を使用するもう一つの利点は、小さな整数の範囲にキーを圧縮してくれるところです。ハッシュ値をキーの代わりに保存できるので、殆どの実践的な用途では、4 バイトの整数におさまります。それに対して、その他の外部キーの多くは 8 バイトの long やそれ以上の大きさ になります。これは、より小さいというだけでなく、二回目の参照の際にハッシュを再計算する必要がないため、読み込みもさらに早くなります。
コードとベンチマーク
わたしたちは、自社開発した MPH のコードをオープンソース化しました。ベンチマークとして、別のオープンソースの選択肢といくつか比較してみます。
- SQLite3: 1 つのファイルでできている複製に適した RDBMS
- LevelDB: Google の LSM ツリー構造のキー・バリューストア
- lsm: Indeedの LSM ツリー構造のキー・バリューストア
- discodb: MPH に基づいたイミュータブルなキー・バリューストア
- TinyCDB: 完全でないハッシュを使用したイミュータブルなキー・バリューストア
これらの選択肢は、同じような機能セットを持っていない点をご注意ください。SQLite は関係演算を全て提供し、 lsm や LevelDB は範囲のクエリを提供します。そして、これら 3 つのストアはミュータブルです。ここではこれらのソフトウェアに共通した一機能だけを見ていきます。
本番環境のデータにもとづいた、概念上リンクした 2 つのテーブルの結果を見ていきますが、こうすることで、上記に説明したハッシュでリンクする最適化の効果を示すことができるほか、さらに自然な表現が SQLite でできるようになります。この最初のテーブルは 5000 万件の 64 ビットのハッシュを項目の小さなクラスタにマッピングしたものです。これらの項目は 80 ビットの整数で 16 桁の Base32 文字列として表されます。二番目のテーブルは、クラスタ内の各項目に対応するハッシュにリバースマッピングしたものです。
Indeed のキー・バリューストアの特筆すべき点は、任意のシリアライズ手法を様々なプラグインの中から選んで使用することができる点です。公平に比較するために、LSM ツリーと MPH については、単なる文字列から文字列のマッピングの場合と、 2 つの最適化を適用した場合のテーブルサイズの両方を含めました。固定長の 8 バイトの long の値としてキーをエンコードし、 80 ビットの整数の短いリストとして値をエンコードしました。 SQLite に関しては、整数としてキーをエンコードしました。
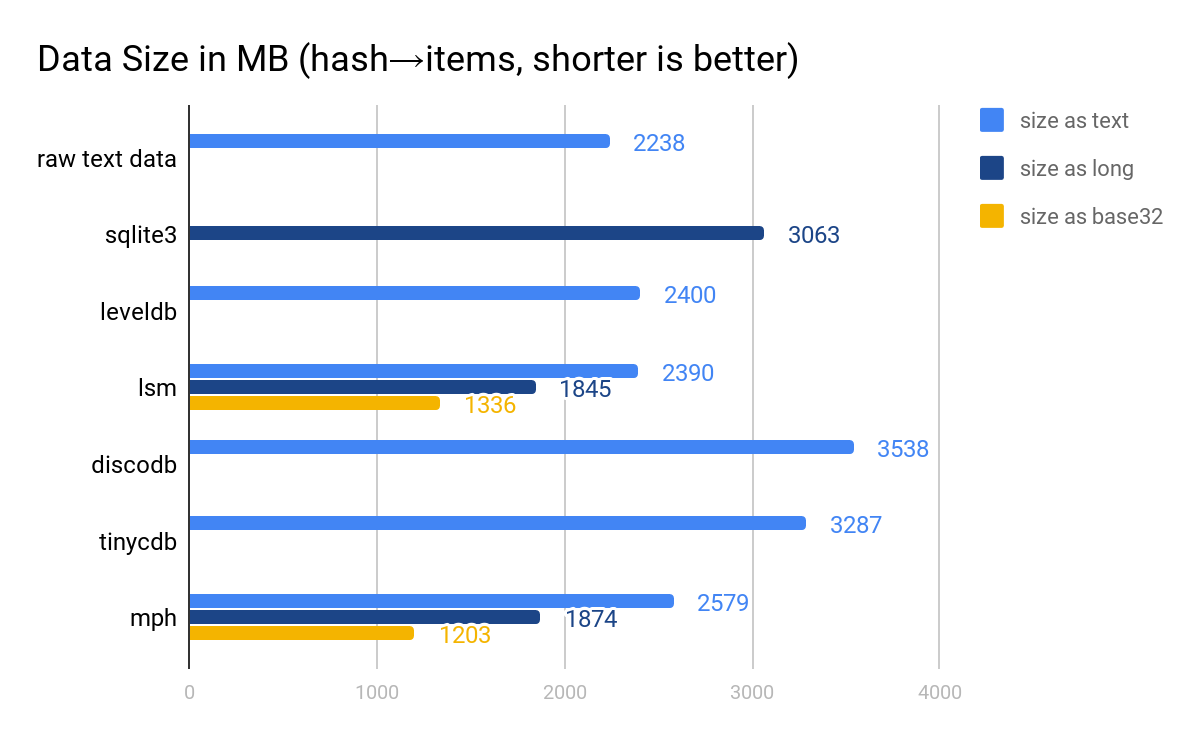
文字列のマッピングの通常のケースでは、 LevelDB 、 lsm 、MPH は全て同等のサイズで、他のソリューションにくらべて格段に小さいものとなります。より効率的なシリアライゼーションを適用すると、 lsm と MPH はさらに小さくなり、MPH はこれによりさらに、データサイズの規則性を活かし、一番サイズの小さい選択肢になります。
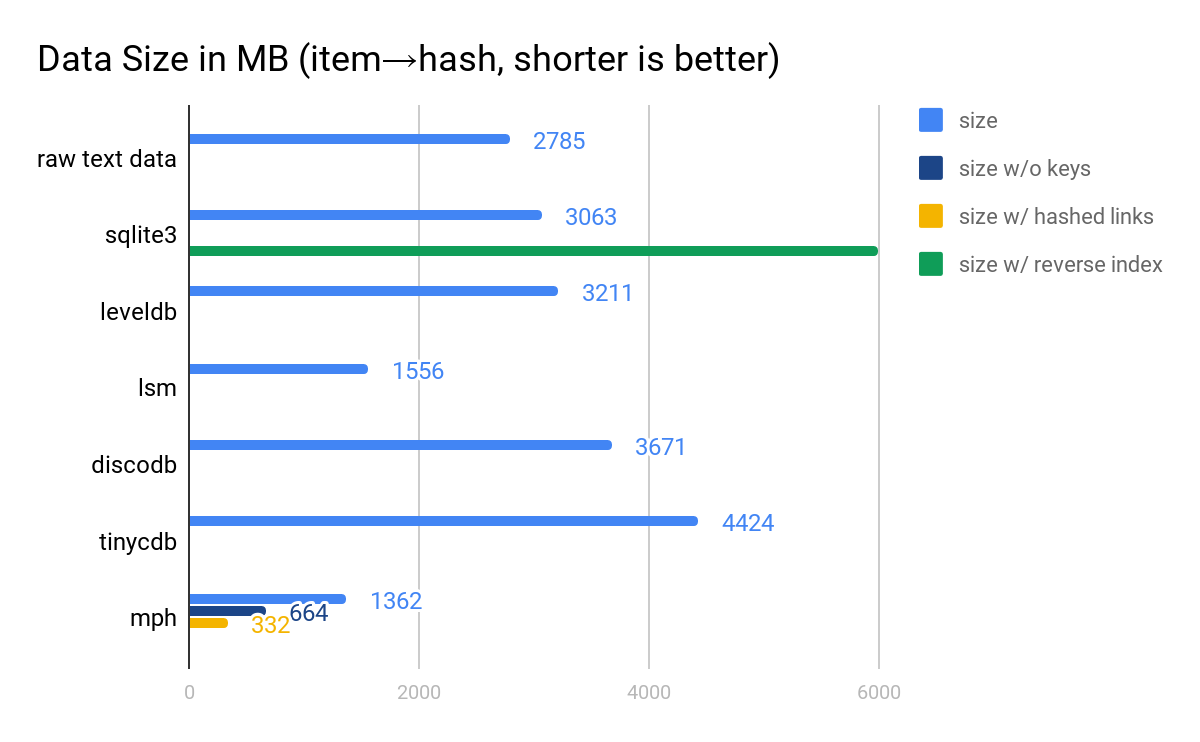
ここでは、 lsm と MPH の最も良いシリアライゼーションだけを考えます。 MPH は、上記で説明した、キーを保存せず、その後で上記のテーブルを完全ハッシュ値経由でリンクする最適化を利用した場合のサイズも示しています。 SQLite は、両方の列をインデックス化した際のサイズを併記しています。このようなインデックスを作ると、前述の実験で作ったようなテーブルは不要になります。この場合は、 SQLite のインデックスは discodb と TinyCDB に関しては、前述の実験のテーブルを合わせたサイズよりも小さくなり、LevelDBでは同じ位になります。しかし、 MPH は最後まで他のものより小さく、事実、全ての最適化が適用された理想的なケースでは一桁分小さくなります。
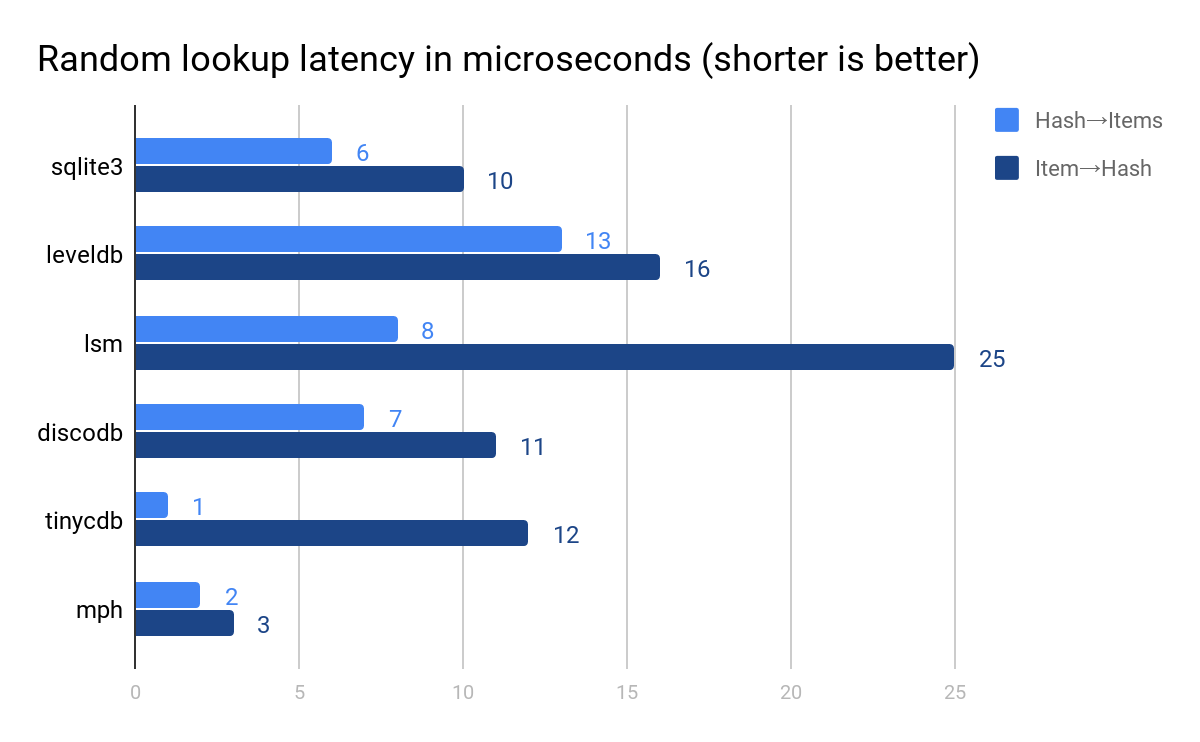
ハッシュに基づくソリューションは、少ないシーク回数で済むので、より早くなる傾向があります。MPH は全体の中でも最も速く、抜きん出ています。

書き込みのパフォーマンスは lsm と MPHが最も高いパフォーマンスを見せています。 TinyCDB はこの時点ではデータの破損により、除外されています。 4GB と決められた保存容量がデザインされているのですが、 3GB の時点で、キーの 30% を取得することができなくなりました。
お試し下さい
IndeedのMPHは、Gitでオープンソース化し、利用可能となりました。
もし、既にキー・バリューストアをサーバーに移している場合、 Indeed の MPHテーブルはサイズを小さくし、読み込みを早くできるかもしれません。コンパクトな表現を使用して、より多くのデータを同じ容量内に保存し、以前には大きすぎると考えていたデータサイズも削減することが可能になります。集中型データベースの代替案をまだ決定していない場合、是非ご検討下さい。