
プロダクトの成長を加速できるABテストを予言してくれたり、目標指標の向上につながるUIを映し出してくれる魔法の水晶玉が欲しい、と思ったことがある方もいらっしゃるのではないでしょうか。
統計モデルとSHAP決定プロットを使えば、インパクトが大きなABテストのアイデアをまとめて出すことができます。Indeed Interviewチームは、この方法論を活用して最適なABテストを作成し、主要なビジネス指標の5~10%向上を実現しています。
ケーススタディ:面接への招待数を増やす
Indeed Web面接は、求職者と採用企業にとって面接をできる限りシームレスなものにすることを目指しています。Indeed Interviewチームが掲げる目標は、このプラットフォームで実施する面接数を増やすことです。このケーススタディでは、採用企業が送信する面接の招待数を増加することにつながるUIテストのアイデアを探していました。そのためには、採用企業ダッシュボードでユーザーである採用企業の行動を分析して、面接の招待がどのように行われるかを予測する必要がありました。
UI要素を特徴量に変換する
採用企業の行動を理解するための第一歩は、データセットを作成することです。採用企業のダッシュボードでのクリック数に基づいて、面接への招待が送信される確率を予測する必要がありました。
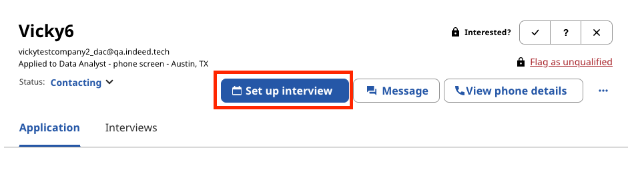
データセットは、採用企業が特定のUI要素をクリックした回数が各セルに表示されるように構成しました。ここでターゲットとなる操作は[Set up interview(面接を設定する)]ボタンですが、このボタンのクリック回数を特徴量として使い、そのボタンがクリックされるか、またはされないかを予測しました。
ターゲット変数に基づくモデルのトレーニング
次のステップは、データセットに基づいて予測を行うようにモデルをトレーニングすることでした。全般的なパフォーマンスが優れていて、特徴量の間の相互作用を検出できることから、ツリーベースのモデルCatBoostを選択しました。また、ほかのモデルと同様に、このモデルは解釈ツールのSHAPプロットと効果的に連携します。
相関係数やロジスティック回帰係数を使うこともできましたが、SHAPプロットとツリーベースのモデルの組み合わせを選択したのは、モデル解釈タスクを行う上でそれぞれのメリットを活用できるからです。特徴量の重要度を考慮に入れるSHAPプロットでは、同じような相関係数を持つ2つの特徴量から、大幅に異なる解釈が得られることがあります。また、一般にツリーベースのモデルはロジスティック回帰よりもパフォーマンスに優れているため、モデルの精度が高くなります。SHAPプロットをツリーベースのモデルを併用することで、パフォーマンスと解釈可能性の両方のメリットが得られます。
SHAPの結果を正の予測値および負の予測値として解釈する
データセットとトレーニング済みモデルが得られたら、モデルから生成されたSHAPプロットを解釈できます。SHAPによって、特定の特徴量が予測値をどれだけ変化させることができるかが分かります。以下のSHAPプロットでは、それぞれの行が特徴量で、特徴量は重要度の順に降順で並んでいます。つまり、一番上のものが最も重要であり、[Set up interview]のクリックというターゲットアクションに対して(正または負の)最大の影響を及ぼします。
それぞれの特徴量のデータは色付きで表示され、色は特徴量のスケールを表しています。プロットの赤いドットは、採用企業がそのUI要素をクリックした回数が多いことを示し、青いドットは採用企業がその要素を数回しかクリックしなかったことを示します。また、それぞれのドットのSHAP値がX軸に示されており、その特徴量がターゲットに与える影響の種類(正または負)と、影響の強さを表しています。ドットが中央から遠いほど、強い影響があります。

正の予測値を表す赤いドットと、負の予測値を表す青いドットで特徴量の概要を示すSHAPプロット
ドットの色と位置に基づいて、特徴量を正または負の予測値として分類しました。
- 正の予測値 – 赤いドットが中央よりも右にある特徴量
- SHAP値は正です。つまり、この特徴量を使用して、採用企業が面接の招待を送信することを予測できます。
- 上記のSHAPプロットでは、特徴量Bが良い例です。
- 負の予測値 – 赤いドットが中央よりも左にある特徴量
- SHAP値は負です。つまり、この特徴量を使用して、採用企業が面接の招待を送信しないことを予測できます。
- 特徴量Gがこれを示す良い例です。
中央の両側に赤いドットがある場合はもっと複雑で、依存関係プロット(これもSHAPパッケージに付属)などのツールを使用してさらに詳しく調査する必要があります。
この特徴量とターゲットの関係は、因果関係があるとはまだ言えないことに注意してください。モデルが因果関係を断定できるのは、すべての交絡変数が含まれていると仮定する場合のみで、これは強い仮定です。因果関係が成り立つ可能性はありますが、ABテストで検証されるまで確実には分かりません。
テストのアイデアを生み出す
このSHAPプロットには9つの正の予測値と4つの負の予測値が含まれ、それぞれの予測値がUI要素とターゲットの関係に関するABテストの仮説になる可能性があります。正の予測値はターゲットの使用を促進し、負の予測値はターゲットの使用を妨げるという仮説を立てます。
これらの仮説を検証するために、正の予測値をより目立たせて、採用企業の目に留まりやすくする方法をテストできます。特徴量をクリックされた後、採用企業の注意がターゲットに向くようにして、ターゲットの使用を促すことができます。もう1つのオプションは、採用企業の注意を負の予測値からそらす方法をテストすることです。アクセスしづらくなるように適宜調整し、ターゲットの使用率が増加するかどうか確認します。
正の予測値を増加させる
SHAPプロットからの正の予測値に、UIでより目立つようにする変更を加えてテストしました。ダッシュボードで特徴量Bを目立たせて、ユーザーである採用企業の注意が向くようにしました。採用企業が特徴量Bをクリックした後、[Set up interview]ボタンの魅力が高まるようにビジュアルをデザインし直して改良したUIを表示しました。
その結果、面接を設定するボタンのクリック率が6%増加しました。
負の予測値から注意をそらす
さらに、ターゲットの使用率が向上するようにSHAPプロットからの負の予測値に変更を加えるテストも行いました。ダッシュボードで[Set up interview]ボタンのそばに特徴量Gを配置することで、特徴量Gから採用企業の注意をそらすテストを実施しました。こうすることで、採用企業が面接の設定を選択しやすくなりました。
このテストの結果、面接の招待を送信するボタンのクリック率が5%増加しました。
水晶玉を覗き込むと見えるもの
SHAPプロットは水晶玉のように予言はできませんが、統計モデルと併用することでUIのABテストのアイデアをまとめて生み出すことができ、多くのプロダクトのターゲット指標を向上することができます。ユーザーダッシュボードのように、複雑で非線形のUIを持つプロダクトには特に適しています。さらにこの方法論によって、ターゲット指標を最も大きく向上させるUI要素を見極めるための手掛かりが得られるので、インパクトを最大化する特徴量のテストに集中できます。この方法を活用すれば、あなたにもきっと幸せが訪れるでしょう。

