Indeed では Java 7 から Java 8 へ移行しています。 (現段階では、移行は完了しております。)段階にわけて移行しており、まず Java 7でコンパイルされたバイナリを JRE 8 (Java 8 の実行環境)で実行するところから始めました。一度に全てを切り替えてしまうのではなく、いくつかのカナリアテストアプリを使用して、どんな問題が見つかりそうか様子を見ました。
私たちは、求人検索のウェブアプリを一つ目のカナリアテストとして選びました。昨年の 5 月に、私たちは本番環境にある 1 件の求人検索サーバーを JRE 8 に切り替えました。何も問題なく、 QA 環境で JRE 8 を数週間使用していましたが、本番環境をJRE 8 に切り替えたところ、システム負荷は 5 (通常のレベル) から 20 (異常なレベル)まであがりました。進める前に、まず修正が必要なくらいはっきりと増えていたのです。この問題の解決は、変わった方法を必要としました。
Datadog 内の本番環境の指標
まず、 Datadog を確認するところから始めました。 Datadog は、様々な指標やイベント・コリレーション(event correlation)をリアルタイムで監視するために、私たちが使用しているクラウドベースの外部サービスです。以下の Datadog のグラフは、 Indeed のあるデータセンターにおける、求人検索サーバーのホストごとにかかるシステム負荷を示しています。外れ値(青い線)は JRE8 を実行しているサーバーです。
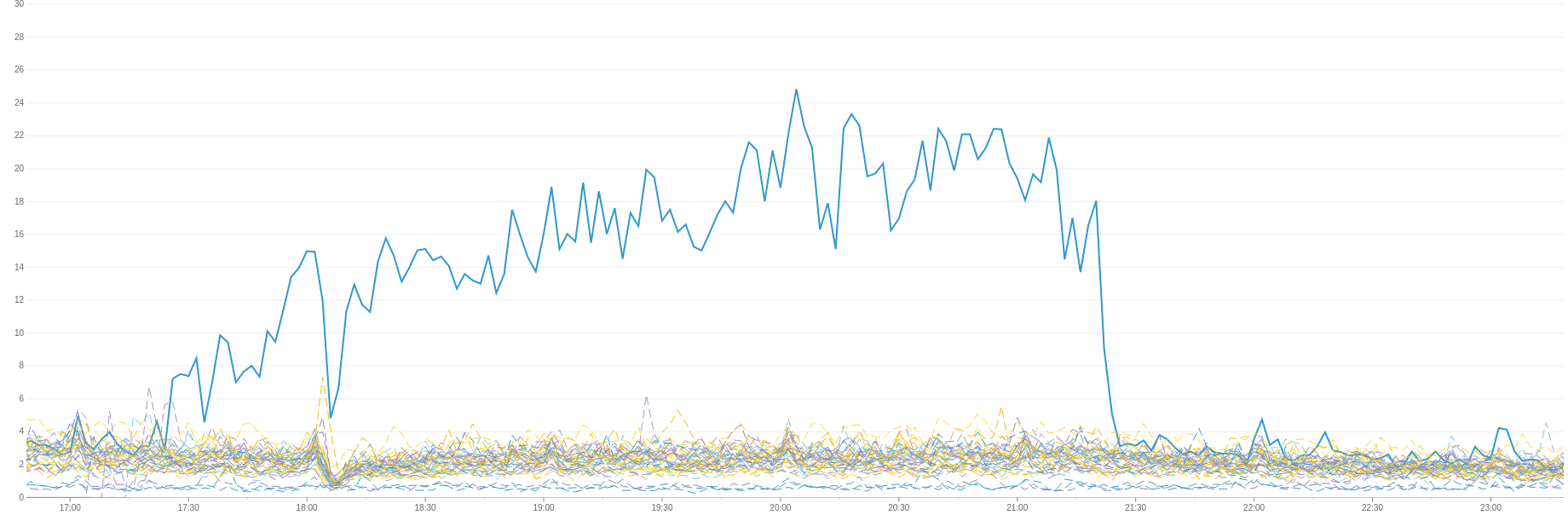
図1 あるデータセンター内における求人検索サーバーのシステム負荷
こちらは、ホストごとにかかる応答時間の中央値を示しています。これも、 JRE8 を実行するサーバーが外れ値になっています。

図2 ホストごとにかかる応答時間の中央値
まだ JRE7 を使用している求人検索サーバーは、通常のシステム負荷と、通常の応答時間の中央値を示したので、問題は、 JRE8 のサーバー特有のものでした。
Java の処理が、ガベージコレクション(GC)のせいで、遅くなるというのは、珍しいことではありません。 そこでGC の指標を Datadog に送ってみましたが、 JRE8 のインスタンスのための GC のグラフは普通に見えました。
本番環境のログファイル
次に、 Web アプリケーションのログファイルを確認しました。 JRE 8 を使用した 4 時間に発生した全ログメッセージと、その 24 時間前から発生したログメッセージを取得しました。手作業で読むには量が多すぎたので、代わりにエラーの分布の仕方の違いに集中しました。各エラーに関連する Java クラスの名前を抽出し、異なる時点でのヒストグラムを生成しました。
ヒストグラムは、 JRE 8 を使用していた間に memcached のクライアント側のタイムアウトがわずかな増加を見せた事や、もうメンテナンスされていないオープンソースの memcached のクライアントライブラリが自社のアプリケーションで使用されている事を示しました。しかし、Google 検索では、そのライブラリに関して、 JRE 8 特有の問題があるとは出てきませんでした。ソースコードも見てみましたが、問題はありませんでした。タイムアウトの増加は、どうやら単にシステム負荷の増えたことの副作用らしい、と判断しました。
QA 環境で問題を再現
本番環境のエビデンスが、問題をはっきりと示してくれないので、次のステップはQA 環境でそれを再現してみせることでした。先ほど触れたように、 Web アプリは QA 環境の JRE 8 では、正常に実行されていたからです。パフォーマンスの問題は、システムに充分な負荷が与えられるまで姿を現さないかも知れないですし、 QA のサーバーも本番環境のサーバーほど、トラフィック量は多くないので、これは別に驚くようなことではありませんでした。通常の QA レベル以上にトラフィックを増やしたら、同じような症状が見つかるのでは、と期待しました。
Imhotep という Indeed 独自のシステムにクエリをかけて、最も典型的な受信リクエストの比率を見つけました。そして、 JMeter を使用してこういったトラフィックの比率をシミュレーションし、システム負荷を監視しながら JRE 7 と JRE 8 のインスタンスの各自で、二回実行しました。両方のケースにおいて、 Web アプリは、毎秒 50 件程度のリクエストを処理していました。システム負荷も、どちらも大体同じくらいでした。
毎秒 50 件のリクエストというトラフィックの負荷は、 QA 環境で通常シミュレーションするよりも高いですが、本番で受け取る量に比べるとまだまだです。この問題に取り組んでいた頃、本番環境の求人検索のインスタンスは各自、毎秒およそ 350 件のリクエストを処理していました。 QA で問題を再現するためには、このトラフィックの量にもっと近づける必要がありました。
ボトルネックとしての JMeter の除外
何故、アプリケーションの処理は毎秒50件のリクエストに抑えられていたのでしょう? QA 環境のせいにする前に、ボトルネックとしての JMeter を取り除く必要がありました。2番目のサーバーに JMeter をインストールして、 1 番目の JMeter インスタンスと同じように設定し、それから両方を同時に実行しました。もしこの 2 つのインスタンスが毎秒に 50 件以上処理できるようなら、 JMeter がボトルネックになっているのが分かります。その場合には、次のステップとして、 Web アプリが飽和するか、システム負荷が 20 に上がるまで、もっと JMeter のインスタンスを追加するはずでした。
ところが、 JMeter はボトルネックではありませんでした。両方のインスタンスを同時に実行してみたところ、まとめたスループットは、毎秒 50 件のリクエストのままでした。
遅いサービスの削除
求人検索のアプリは 22 個のサービスに依存しています。それらの一部が遅くなると、 Web アプリも遅くなってしまいます。 QA 環境内のとあるサービスは、本番環境内にある対応したサービスより遅いかも知れません。パフォーマンスを分析するために依存したアプリを隔離する際、私たちは、時として遅いサービスをダミーの速いバージョンに置き換えます。こうしたことから、私たちは Indeed のアプリケーションが最もよく使う 5 件のサービスのダミーバージョンを作ることに決めたのです。
新しいダミーのサービスを使用して、 JMeter は Web アプリを、毎秒あたり 100 件のリクエストのペースで動かしました。 JRE 8 は JRE 7 に比べて 15% 程度遅くなりましたが、システム負荷はそこまで高くありませんでしたし、 JRE 7 と JRE 8 の差はそれぞれの実行で異なりました。しかし、数字がまだ不揃いだったので、両方の設定のパフォーマンスを、 YourKit を使用して分析しました。
YourKit
YourKit は、 Java プロセスにアタッチして、実行時の統計を収集し分析する Java のプロファイラです。アタッチしたらすぐに、パフォーマンスのスナップショットを作成することが出来ます。これは、複数の時点での Java の各スレッドにおけるスタックトレースをまとめたものです。 YourKit は、パフォーマンス・スナップショットを複数の方法で可視化してくれますが、これには、どのメソッドが最も時間を費やしたか示すホットスポット・ビューも含まれています。 JRE 8 上の Web アプリは JRE 7 に比べて非常に沢山の CPU を使用していたので、これらに関連するホットスポット・ビューも異なっているはず、と私たちは予想しました。
しかし、両方のビューは、だいたい同じでした。おそらく 、QA 環境でシステムにかけた負荷が、まだ足りなかったのが原因でした。
パフォーマンス・プロファイルを本番環境に
ここで、 QA 環境内で問題を再現する試みにもっと時間を割いても良かったのですが、代わりに、本番環境で YourKit を使用することに決めました。JRE 7 と JRE 8 両方の、本番環境のパフォーマンス・スナップショットを取得しました。この二つの、唯一のはっきりとした違いは JRE 8 の設定は、より多くの CPU を使用しているように見えた点でした。事実、パフォーマンス・スナップショットの結果だけでは説明できないくらいに CPU を使用していました。それは、まるでアプリケーションが YourKit に計測できない何かをバックグラウンドで実行しており、ビジー状態になっているようでした。なので、私たちは、 perf コマンドを使用して、分析を試みることにしました。
perf コマンドの使用
Java のプロセスは、単なる Java コードの集まりというだけではなく、マルチスレッドの C++ からなる JVM でもあります。 Java のプロファイラは、 C++ のコードが何を行っているか測定できません。そのような測定を行うためには、 Linux perf コマンド のような異なる種類のプロファイラが必要になります。
perf コマンドは Linux のプロセスからコールスタックを記録することが出来ます。これは、プロセスのデバッグ・シンボルテーブルを使用して、呼び出しスタックのアドレスを仮想アドレスから関数やメソッドのシンボルの名前へマッピングしてくれます。JVM のバイナリは Java コードのデバッグ・シンボルテーブルを含んでいませんが、 Java のデバッグ・シンボルテーブル用に Java のプロセスをクエリにかける方法があります。
本番環境では、 30 秒間 10 ms ごとに全ての Web アプリのスレッドの呼び出しスタックをキャプチャするように perf を設定しました。これは、およそ 11,000 件のコールスタックを記録しました。そのデータを集約し、 Flame Graph(フレーム・グラフ)にしました (図3)。
Flame Graph では y 軸がスタックの深さを表します。一番上にあるボックスはいずれも、サンプルを取ったとき CPU 上にあったコードを表しています。その下のボックスは呼び出し元、というように続いていきます。図 3 は非常に高く伸びているのは、コールスタックが深いからです。 x 軸は、ただのアルファベット順です。ボックスの幅が広ければ広いほど、より多くのコールスタックが現れたようです。緑のボックスは Java コード、黄色は JVM 内の C++ コード、赤は JVM 内の C コードです。明度や彩度は、対比しやすいように選んでおり、特に意味はありません
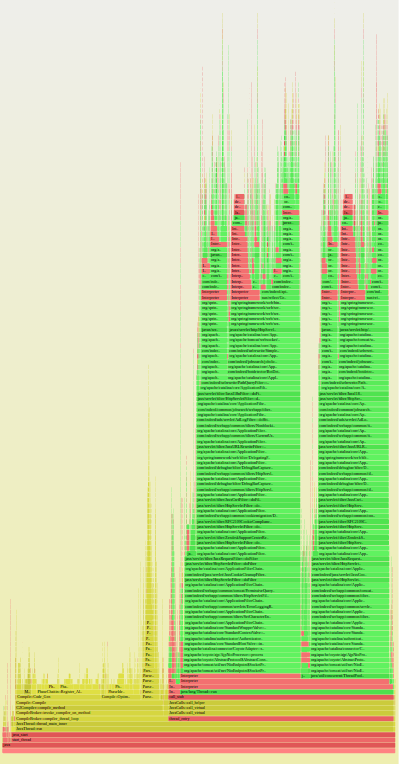
図 3 求人検索のコールスタックを表示する Flame Graph
図 4 は Flame Graph の最下部を示しています。

図 4 拡大した Flame Graph
CompileBroker::compiler_thread_loop (左側の黄色いエリアにあります)はコールスタックの 39% に出現します。これはバイトコードのコンパイラで、頻繁に使われるバイトコードを機械語命令に変換を行う JVM の一部です。 39% という値は多そうでしたし、 YourKit では測定できないバックグラウンドの何かを表していました。
なぜそんなに時間がかかっていたのでしょうか。バイトコードのコンパイラは、設定可能なサイズを持つ codecache とよばれるメモリの特定の領域に対し、機械語を書き込みます。 Codecache がいっぱいになった際何が起きるか設定できる JVM の設定がありますが、デフォルトでは JVM は古いエントリをフラッシュして空き容量を増やすように設定されています。 YourKit が示すには、私たちの codecache の空き容量がほぼ無くなっていたので、最大サイズを増やしてみる価値はありそうでした。
Codecache を倍の容量へ
私たちは、本番環境にある codecache のサイズを、 64MB から 128MB と二倍に増やし、 Webアプリを再起動し、週末のあいだ実行したままにしました。アプリケーションは、正常に動作し、システムの負荷も通常レベルに維持されていました。perf コマンドを実行し、結果を Flame Graph 化しました。( 図5 )
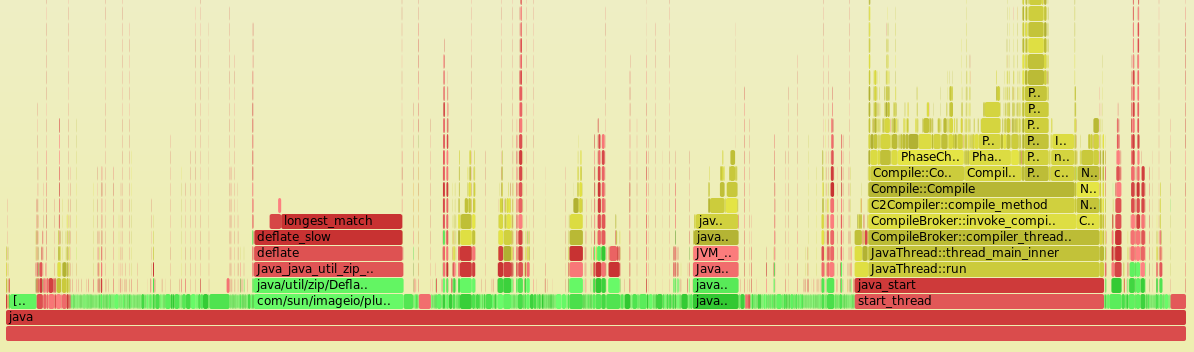
図 5 codecache のサイズを二倍に増やした後の Flame Graph の拡大図
CompileBroker::compiler_thread_loop のボックス(右)の幅は、ホットスポットのコンパイラが以前ほどのビジー状態になかったことを表しています。以前 40% だったコールスタックは 20% になりました。
Codecache の変動
128MB の codecache があっても、私たちはじきに問題にぶつかりました。
図 6 は何が起きたのかを表しています。平坦な青い線が codecache の最大サイズで、その下の紫の曲線は使用した codecache の量を示しています。午前 8 時に、容量の曲線は変動し始め、翌朝 3 時まで安定しませんでした。
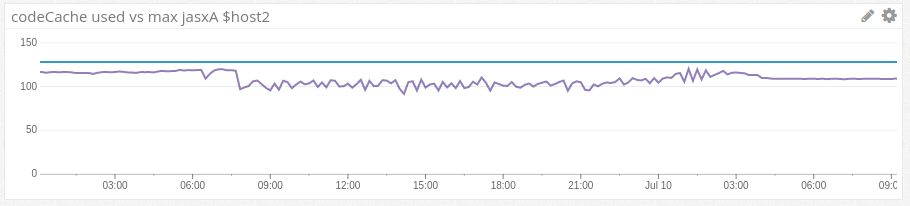
図6 変動を示す Datadog からの Codecache グラフ
コードキャッシュの揺れ動きは、応答時間を遅くさせました。図 7 は、このデータセンター内の全ての求人検索サーバーの応答時間の中央値を示しています。オレンジ色の外れ値が JRE 8 です。その他のものに比べて 50% 程度遅くなっていました。
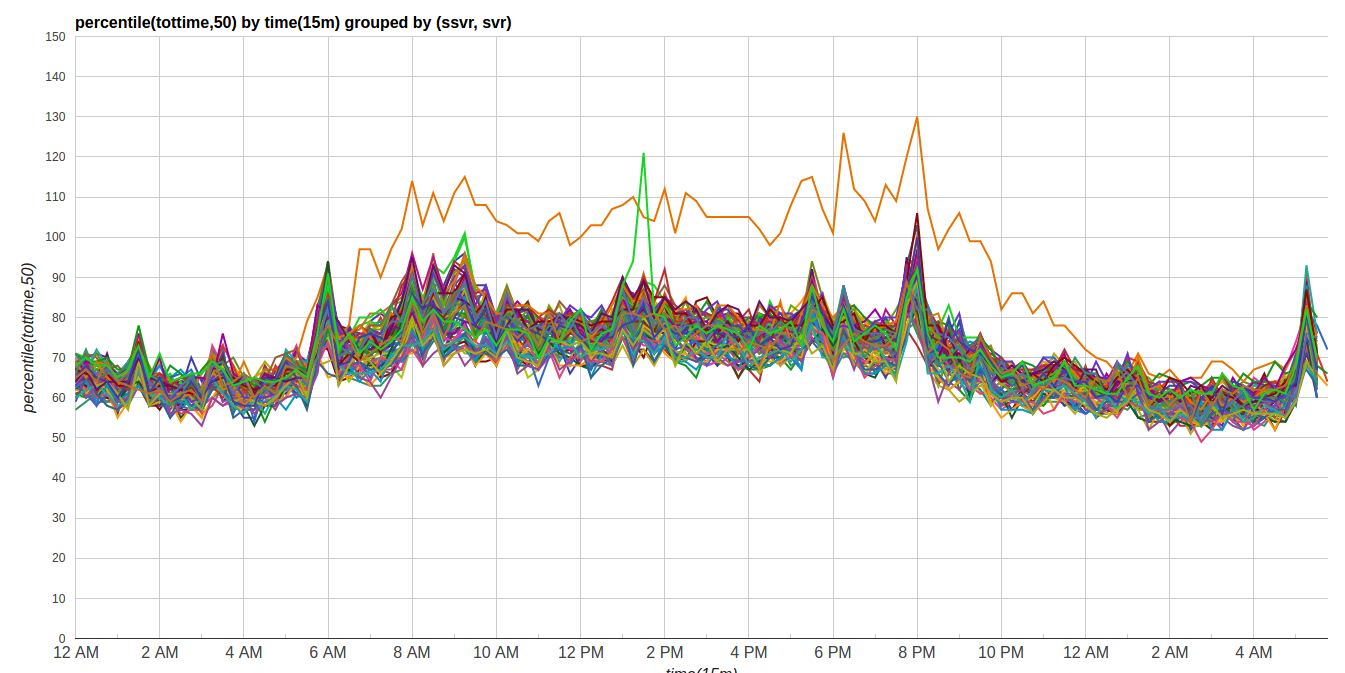
図 7 求人検索の Webアプリの応答時間の中央値
Indeed の Web アプリにとって適正なサイズ
新しい codecache の容量である 128MB は、それでもまだ Java 8 のデフォルト値の半分でしかありませんでした。パフォーマンスの問題を解決するために、私たちは再び容量を 2 倍の 256MB にしました。 Codecache の使用量がこの容量の下で安定してくれることを願いました。もし 256MB でも足りないようなら、もう一度二倍にすることも出来ました。それでもうまく行かない場合には、 codecache の使用量を減らすために JVM の最適化の設定で実験しようと考えました。
ここで、私たちに有利に働いた点が一つありました。それは Indeed の開発サイクルでした。通常では、最低週に一度もしくは週に複数回、私たちはこの Web アプリを再度デプロイするのです。クリスマス休暇を除き、再デプロイせずに2週間あけるということは絶対ありません。合計 8 件の 256 MB の codecache をもつインスタンスを設定し、少なくとも一週間は実行することに決めました。問題は何も検知されず、これをもって成功としました。
何故 Codecache の容量を増やすのか?
JRE 8 向けのデフォルトの codecache の容量はおよそ 250 MB です。これは48MB がデフォルトの JRE 7 に比べると 5 倍ほど大きい値です。私たちが経験で学んだことは、 JRE 8 がこの増えた分の codecache を必要とする、と言うことです。今のところ 10 個のサービスを JRE 8 に切り替えましたが、それら全てが、以前に比べると約 4 倍の codecache を使用しています。
この 4 倍になった原因は、階層型コンパイルでした。JVM には 2 種類のバイトコード・コンパイラがあります。その一つは C1 と呼ばれ、素早い起動のために最適化してくれます。もう一つは、 C2 と呼ばれ、長期で実行するプロセスのスループットを最適化してくれます。初期の Java バージョンでは、 C1 と C2 は相互に排他的なものでしたので、 C1 を -client スイッチで選択するか、 C2 を -server スイッチで選択するか、のどちらかでした。そして、 Java 7 から階層型コンパイルが導入されました。これは C1 を起動時に実行し、そして、残りの処理を C2 に切り替えてくれます。階層型コンパイルは、長期で実行するサーバー処理のために起動時間をブーストする目的で作られ、 Oracle 社によると、より良い長期間のスループットを生み出せるとのことです。これは、 Java 7 では明示して有効化する必要がありますが、 Java 8 ではデフォルトで有効化されています。QA 環境で JRE 8 上で階層型コンパイルを無効にした際には、 codecache の量は 50% も減少しました。
また、 Java 8 がより多くの codecache を使うのは、 Java 7 よりもアグレッシブに最適化を行うからです。例えば、 InlineSmallCode オプションは、インライン化するには、一つ前のコンパイル・メソッドがどれくらい短くなければいけないかを管理しますが、 Java 8 では、このデフォルトを 1000 から 2000 に引き上げています。つまり、 Java 8 のオプティマイザーは、より長いメソッドのインライン化を行えるのです。より多くのメソッドをインライン化し、そしてそのインライン化のメソッドもさらに大きくなるようでしたら、より多くの codecache が必要となります。
Java 8 に移行する開発者は、心配すべき?
もし、デフォルトの codecache の容量をオーバーライドしてしまうけれど、メモリに空きがある場合、おそらくオーバーライドを削除するので事足りるでしょう。
万一のために、 codecache の容量を監視することを推奨します。こちらの Github プロジェクトは Datadog に JMX codecache の統計をアップロードする方法の例を載せています。
もしメモリに既に空きがあまりない場合、階層型コンパイルを無効にして、起動時間、長時間のパフォーマンス、そしてメモリ使用量にどう影響があるか測定して見るのが良いかもしれません。
謝辞
このプロジェクトを支援してくれた Indeed の Ops チームの Connor Kelly とMike Salsone は沢山の変わったリクエストにも忍耐強く対応してくれました。
Indeed のソフトウェアエンジニアである David Wahler と Chen Yang も YourKit プロファイルを解析するのを助けてくれました。 David はまた、 perf コマンドを使用することを薦めてくれ、 Flame Graph を読み解くのを助けてくれました。
参考文献
Brendan Gregg は Netflix のエンジニアで、パフォーマンス測定のスペシャリストです。彼のウェブサイトで、沢山のパフォーマンス関連の記事を読むことができます。また、 YouTube 上にある彼のテックトークは視聴する価値があります。Brendanはパフォーマンス・データを視覚化する際の Flame Graphの使用を普及させました。また、彼はperf データ内でJavaのシンボルを閲覧可能にした JVM の変更に貢献しています。
最初に codecache について調べた際には、概念の資料と関連する JVM の設定に関して、 Oracle 社のドキュメンテーションを確認しました。
- codecacheに関連するJVMの設定の概要 (ただし 組み込み用Java の資料なので、デフォルト値の一部はサーバー JVM とは異なります。)
- codecache 設定に関するサーバー JVM のデフォルト (上記の記事ほど詳細は書かれていません。)
- Java 8 で修正された codecache バグ