これまでの投稿でお伝えしてきたように、Indeed では大規模な時系列データセットの高速な調査と分析を可能にする Imhotep というデータ分析のプラットフォームを開発しました。前回の投稿では、Atlassian 社の Jira に基づく Imhotep データセットが 開発工程の改善にどのように活用されているか説明しました。
私たちは、指標を収集する新しい方法を常に模索しています。Jira でのアクションを調査し、開発工程を観察するのに使用しているこのツールは、工程に関する洞察を得るのに、最適なように思われました。多くのプロジェクトの Jira の課題の履歴を、時系列に整理されたアクションとして Imhotep のデータセットに変換する方法を探すことに決めました。
オープンソースである Jira Actions Imhotep Builder はJira インスタンスの中の課題の動向を、Imhotep データセットに変換するものです。そこで作成されたデータセット内に存在する各ドキュメントは、作成、編集、移行、コメントなど、Jira の課題の中の各アクションに対応しています。
ビルダは、JIRA REST API に対して、指定された範囲の期間に存在する各 Jira 課題のクエリを送り、課題を一連のアクションに分解します。アクションは TSV ファイル(tab-separated valuesの略。項目をタブで区切る形式)に記録され、このファイルは Imhotep にアップロードされます。
私たちは、ビルダを使用し、 Apache ソフトウェア財団 (ASF) の Jira インスタンスから、彼らのプロジェクト内におけるアクティビティのデータセットを作成しました。Apache のプロジェクトが、データセットを活用して、デベロッパーとユーザーコミュニティのために、工程改善のための洞察を得られることを期待しました。

ASF の Jira データを読み解く
2016 年 1 月 1 日から現在までの ASF の Jira データの Imhotep データセットを作成しました。2018 年 10 日 17 日の時点で、apachejira というデータセットの様子は以下のようになっています。
- 23 万 298 件の課題の作成、180 万件の編集、130 万件のコメントを含む、340 万件近い Jira のアクションが存在。
- アクションごとには 81 バイトを必要とし、全体でディスク上の 274MB を必要とする。
apachejira データセットを使用して、ASF のプロジェクト内で起きている事に対し、様々な問いを立てることができます。
たとえば、 「7 月から 9 月の間に、ASF プロジェクトでバグを報告した回数が最も多いのは誰か?」という質問に対して、1 位は Beam JIRA Bot、2 位はおそらく実際の人物である Sebb という結果が表示されました。
from apachejira 2018-07-01 2018-10-01
where action="create" issuetype="Bug"
group by actor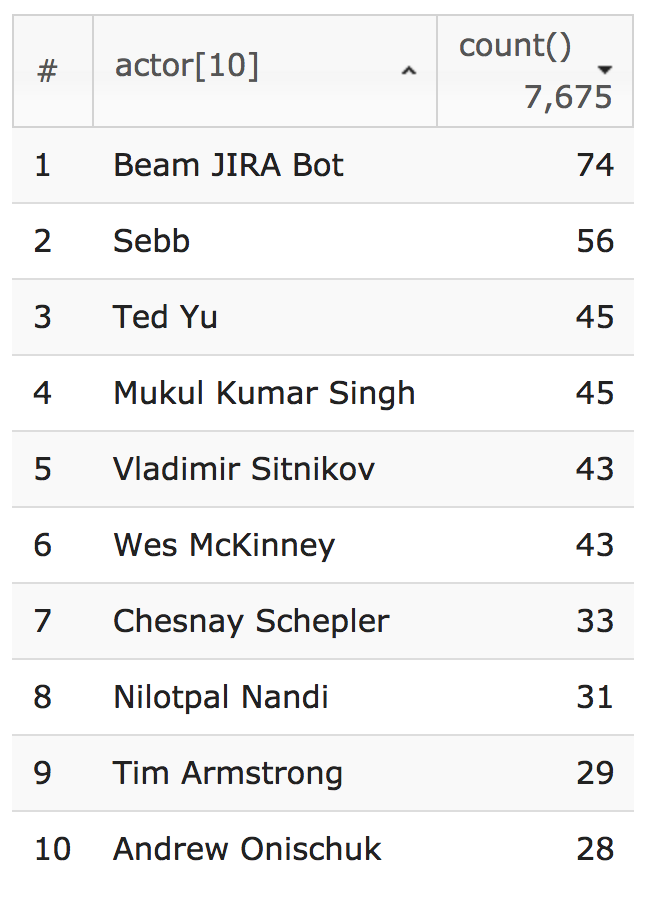
「7 月から 9 月の間で、最もバグの報告回数が多かったプロジェクトはどれか?」という問いには、401 件のバグの報告があった Ignite が Ambari を抜いて1位となりました。
from apachejira 2018-07-01 2018-10-01
where action="create" issuetype="Bug"
group by project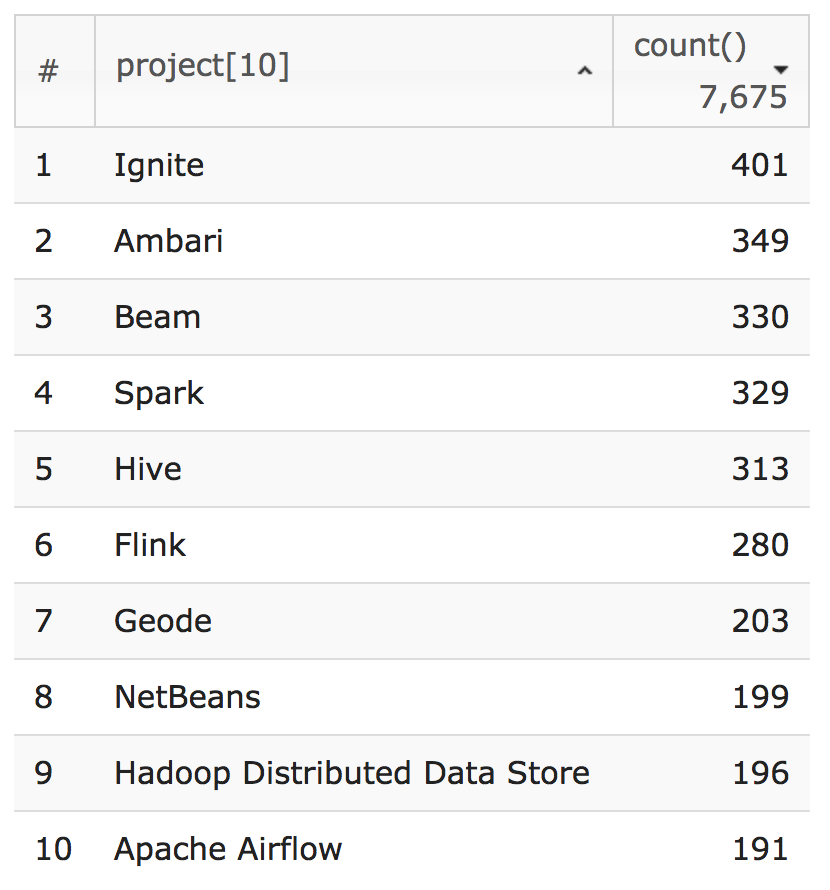
次の二つの質問では、プロジェクトのワークフローに関する相違点を調べました。
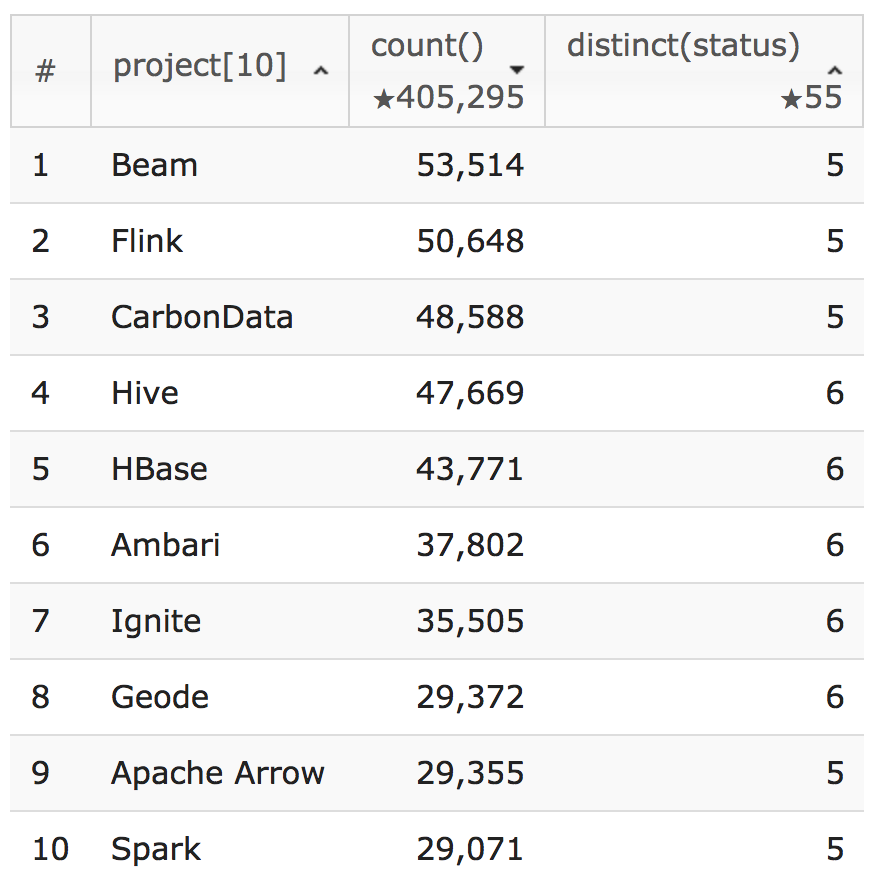
「最も活発なプロジェクトには、明確なステータスはいくつ存在するのか?」
from apachejira 2018-01-01 today
group by project[10]
select count(), distinct(status)上位 10 件のプロジェクトのうち、5 件のプロジェクトは 6 つのステータスを使用しており、その他 5 件のプロジェクトは 5 つのステータスを使用しています。例えば、Apache Beam は 5 つのステータス、Apache Hive は 6 つのステータスを採用しています。
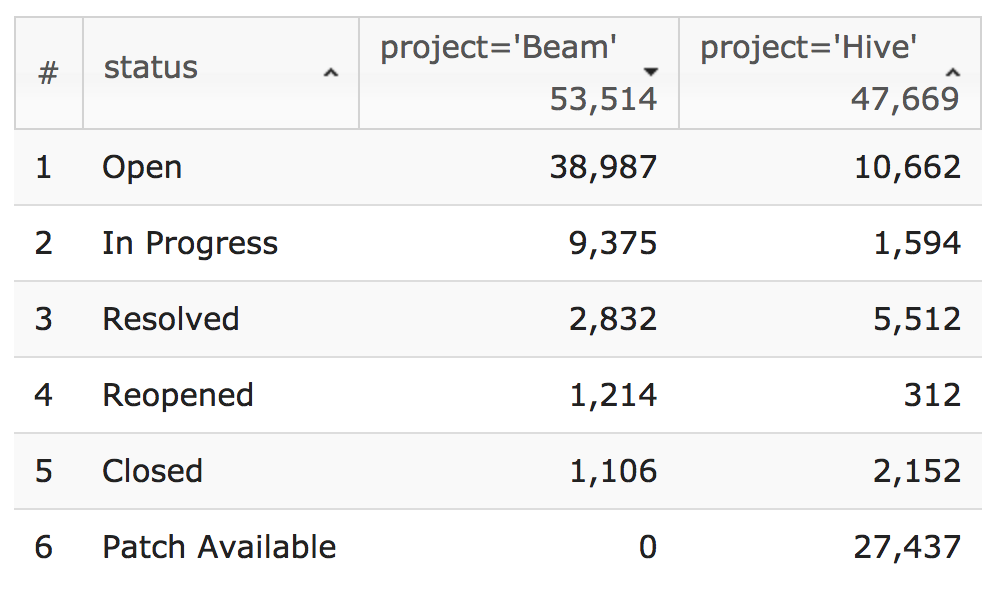
「Apache Beam と Apache Hive で使用されているステータスはどのような違いかがあるか?」
from apachejira 2018-01-01 today
where project in (Beam, Hive)
group by status
select project='Beam',project='Hive'Hive は Patch Available (利用可能なパッチあり) のステータスも採用している一方で、Beam ではこのステータスを使用していません。また、Apache JIRA プロジェクトの 11% がこのステータスを活用していることが解りました。
「2018年に、最も多くのコントリビューターによって Patch Available にステータスを変更された課題はどのプロジェクトか?」
from apachejira 2018-01-01 2019-01-01
where fieldschangedtok='status'
status='Patch Available'
group by project[10]
select distinct(actor)Hive、HDFS、Hadoop Common、YARN、 HBase、そして Hadoop 分散データストアなどの Hadoop のエコシステムプロジェクト 6件がトップ10に入っていました。
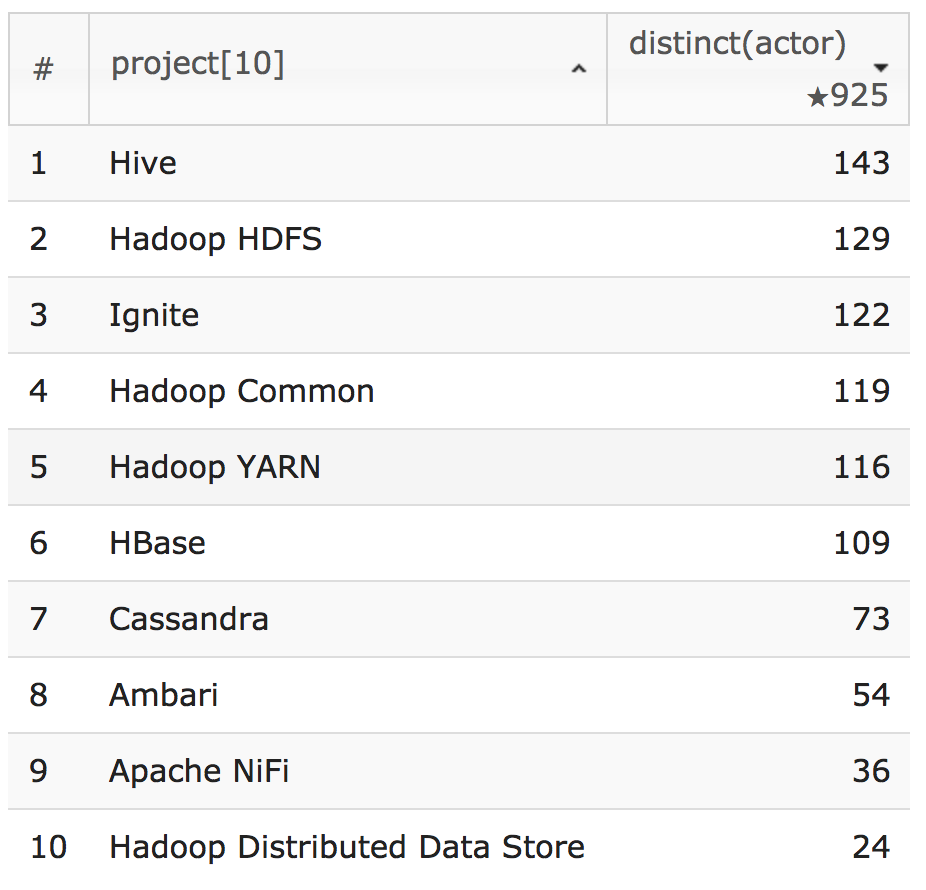
「2018年に、最も Apache Hive に貢献した(Patch Available にステータスを変更した)のは誰か?」
from apachejira 2018-01-01 2019-01-01
where fieldschangedtok='status'
status='Patch Available' project = 'Hive'
group by actor[10]
select count(), distinct(issuekey)上位 10 名のコントリビューターは、2018 年に 578 件の課題に貢献していました。
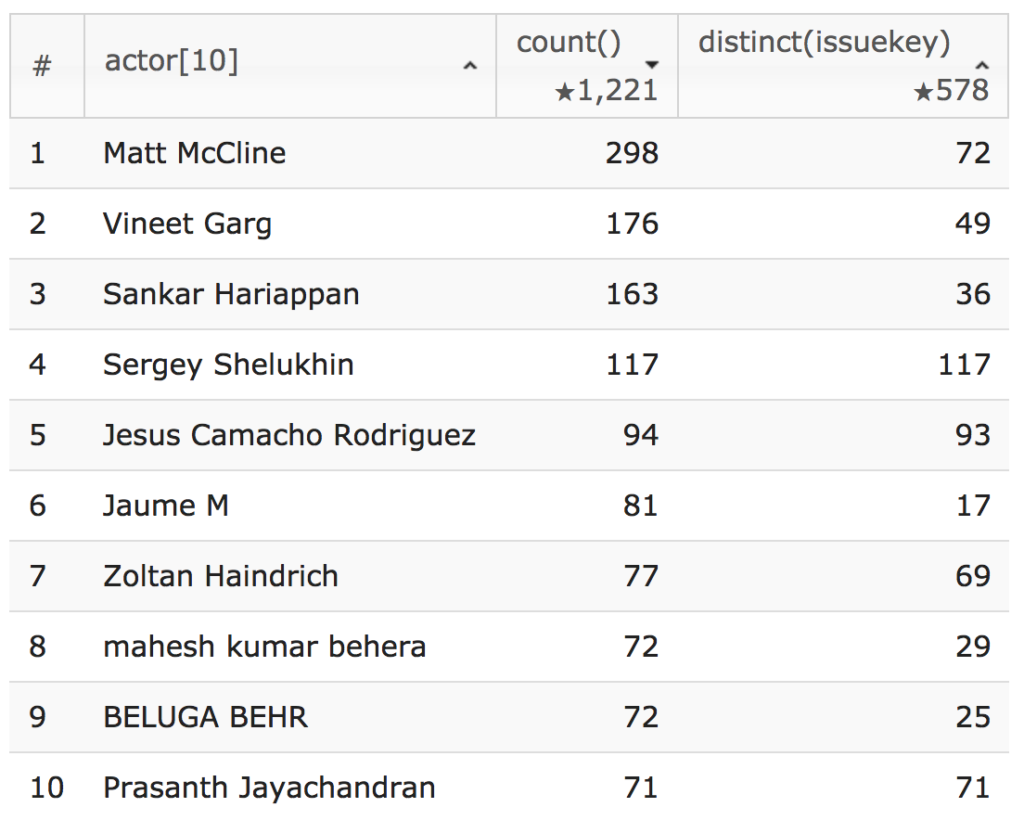
「最も活発なプロジェクト 20 件において、パッチが承認されるまでにどれくらいの時間がかかっているか?」
from apachejira 2018-01-01 2019-01-01
where prevstatus="Patch Available"
status="Resolved"
fieldschangedtok="status"
group by project[10]
select count(), timeinstate\3600/count()
/* hours in state */Hadoop 分散データストアが最も速く、Patch Available から Resolved のステータスへの変更までかかる時間が平均 102 時間という結果が出ました。
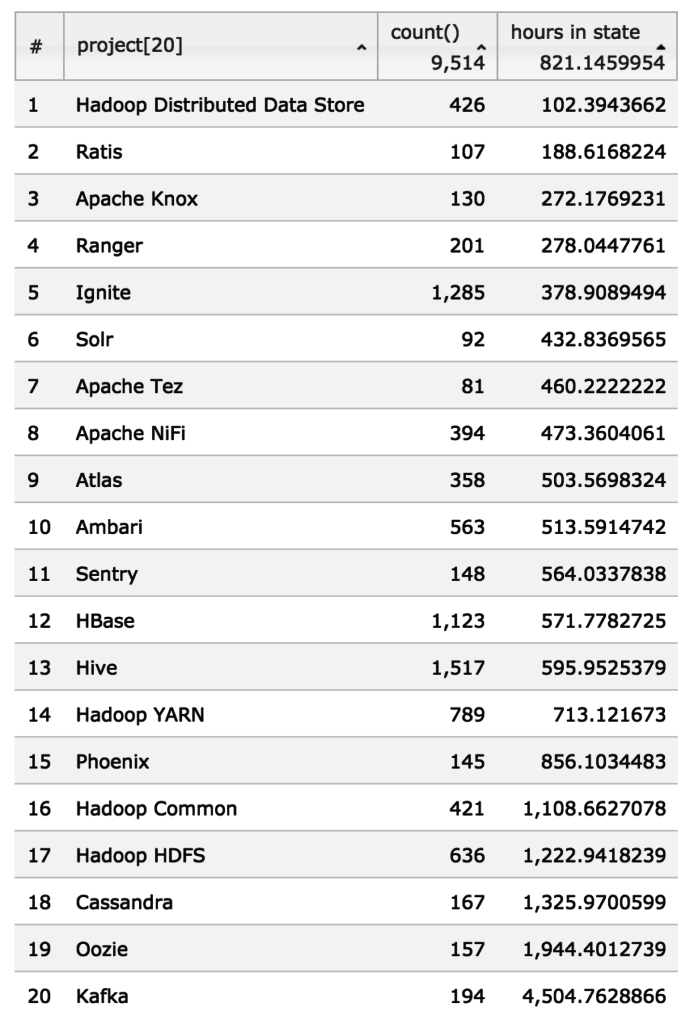
Kafka の平均もとても高いのですが、、Not A Problem (問題なし)、 Auto Closed(自動完了)、Duplicate(重複)、Won’t Fix(修復予定なし)、Won’t Do(実行不可)など、resolution で完了した約28 個の外れ値によって、平均値が上げられていました。
from apachejira 2018-01-01 2019-01-01
where prevstatus="Patch Available"
status="Resolved"
fieldschangedtok="status" project = Kafka
group by resolution
select count(), timeinstate\3600/count()
/* hours in state */
これは、コミュニティにとって悪いことでもあるかもしれませんし、問題ではないかもしれません。いずれにせよ、これらのような数字を深く読み込むことで、興味深い問いが浮かび上がってくることがあります。
ここであげたものは、このデータセットに対する問いのほんの一部の例です。
自社の Jira データセットを作成し分析
Jira Actions Imhotep Builder はオープンソース化されています。自社で Jira に基づくImhotepデータセットを作成する際、ぜひご活用ください。このビルダは、私たちが公開した最初のものであり、新しい Imhotep ビルダディレクトリにも記載されています。
新しいビルダのアイデアや、Imhotep 導入に関するご質問は、GitHubリポジトリにissueを作成いただくか、Twitter 上でご連絡をいただければ嬉しいです。
次回の投稿では、社内コントリビューターの作業を視覚化し、コーチングする上での洞察を得られる、Hindsight という内製ツールについてお伝えしたいと思います。
本シリーズのその他の記事のリンク
- スケーラブル、効率的、そして高速 —— Imhotepとは
- 開発工程の改善(とコーチング)に指標を活用する方法
- 指標に基づく工程改善の事例
- Imhotepを活用しプロジェクトの動向を理解する- ASFの事例
- Hindsight のメリット: 指標に基づくコーチング方法