的確な職種名を選ぶことの大切さ
職種名は多くの場合、求職者が採用企業に興味を持つきっかけとなります。求職者は検索を行う中で、職務内容欄から求人について詳しく調べる前に、関連性のある職種をクリックします。求人を「ソフトウェアエンジニア」と呼ぶのと、「プログラマー」と呼ぶのでは、応募者数や最低要件を満たしている人材の割合に差が出ることが考えられますが、実際どう違うのでしょうか?驚くことに、ほとんど同じような職種名でも、一つの単語を変えただけで、応募要件を満たしている応募者数と応募者総数が増えることが分かりました。本記事では、初期のリサーチと、これを将来どう改善していけるかについて書いていきたいと思います。
Indeed におけるデータサイエンスとプロダクトサイエンス
Indeed におけるデータサイエンスの組織には主に二つの職種が存在します。データサイエンティストとプロダクトサイエンティストです。Indeed のデータ/プロダクトサイエンティストは、現在 オースティン、サンフランシスコ、シアトル、シンガポール、東京、の5 つのオフィスに配属されており、幅広い種類のプロダクトやエンジニアリングチームと一緒に働いています。
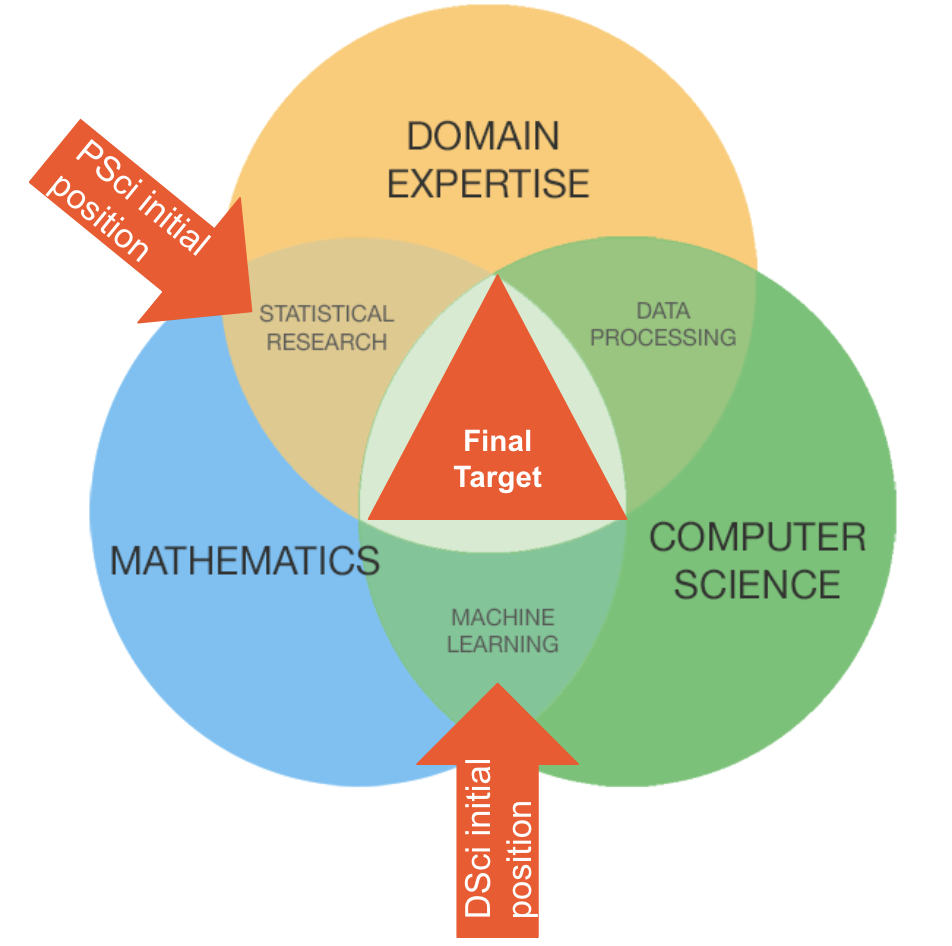
どちらの職種も、人々の職探しに役立てるように、高度な統計や機械学習の手法を用いています。データサイエンスは、機械学習とソフトウェアエンジニアリングにより重きを置いているのに対し、プロダクトサイエンスは実験、分析、そしてプロダクトを改善できるような、さらにシンプルなモデル作成に注力しています。つまり、データサイエンティストはプロダクトマネジメントよりもソフトウェアエンジニアリングに近く、プロダクトサイエンティストは、その逆となっています。
職務内容の違いはこちらからご覧いただけます ( プロダクトサイエンティスト/データサイエンティスト )。これらの違いにも関わらず、最終的に両ポジションで必要とされる条件は基本的には同じです。それは、数学とコンピューターサイエンス、そして専門領域の知識への深い理解と経験を持っている、ということです。
逐次検定: 職種名の変更
職種名がどのように採用プロセスに影響するかを調査するため、実験を行い、3月15日に「プロダクトサイエンティスト」という職種名を、シアトルでは「データサイエンティスト: プロダクト」に、またサンフランシスコでは「プロダクトサイエンティスト: データサイエンス」に、変更しました。その間、オースティンでは元の職種名をそのまま使用していました。また、3 都市ともに職務内容は同じまま残しました。
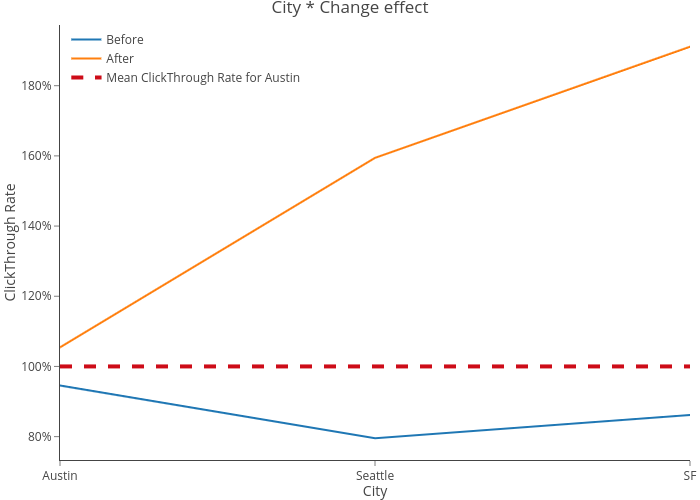
A/B テストにはエンジニアリングの仕事を必要としてしまうので、私たちはこれらを逐次確認していくことを選びました。統計的な検定力分析を行い、サンプルサイズを事前に決定しました。私たちはまず、クリックスルー率(以下 CTR。 クリック数/インプレッション数と定義)と3月15日前後の 3 つの都市での応募者数を比較しました。以下の 2 つの表からも応募者数と CTR が3月15日を境にシアトルとサンフランシスコ(以下 SF )で跳ね上がっているのがわかります。また、3月15 日以降のシアトルと SF の応募者数と CTR が、オースティンよりも有意に高くなっていることを示す t 検定を行いました。
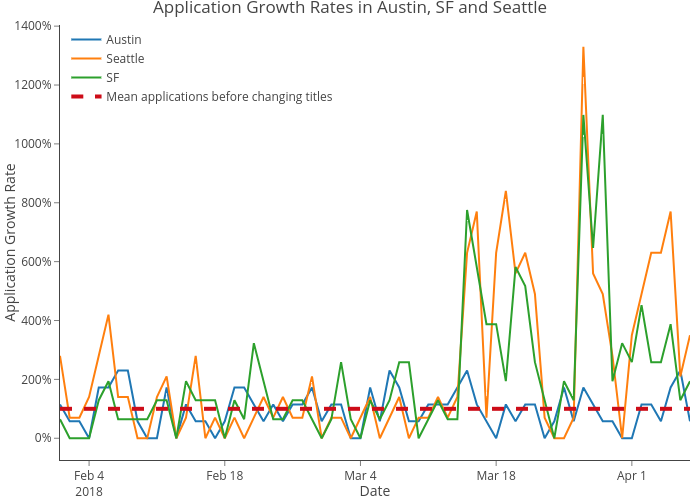
オースティン、SF、シアトルにおける CTR 増加率
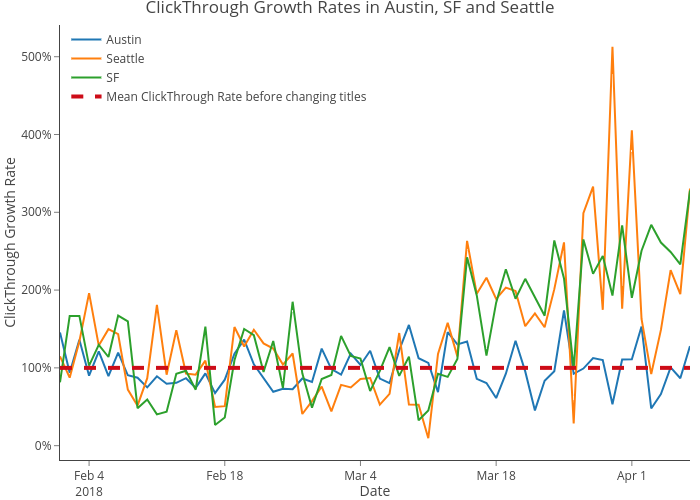
しかし、職種名の変更は求人検索の順位に影響を与える可能性があり、ページ上で上位と下位の求人はクリックされる確率が通常では高いことを私たちは知っていました。この表示位置のバイアスを考慮するために、ページ上のクリック数、検索結果 (SERP) での表示位置、都市 (オースティン、シアトル、SF)、そして私たちが職種名を変更したかどうかを基に、クリックを予測するロジスティック回帰分析を行いました。また 、「職種名を変更する前より後の方で、様々な都市での対数オッズ比が異なる」という仮定を検証するために、都市と職種名を変更したかとの相互作用項を含みました。
回帰方程式は以下のように推定されました。¹
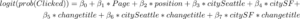
以下の交互作用プロット内の平行ではない線は、有意である交互作用効果があることを示唆しています。これは、交互作用項の関連する有意のp値が裏付けています。
職種名を変更する前は、等式は単純に次のようなものでした。
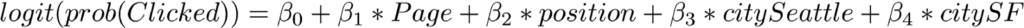
オースティンからシアトルに切り替えると、対数オッズに -0.18 という変化が生まれ、 オースティンから SF に切り替えると対数オッズに -0.09 という変化が生まれました。
職種名を変更した後の等式は以下のようになります。
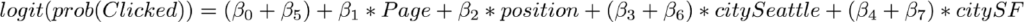
オースティンからシアトルに切り替えると、対数オッズに -0.18+0.6 = 0.42 という変化が生まれ、 オースティンから SF に切り替えると対数オッズに -0.09+0.71 = 0.62 という変化が生まれました。
次のグラフはまた、シアトルと SF の対数オッズ比が、職種名を変更する前よりも後の方が、ずっと高いことを裏付けています。まとめると、職種名を変更した都市では著しく応募者が多くなったことがわかりました。
要件を満たした応募のモデル
職種名を変更したのち、応募者が増えたことはわかりましたが、この応募者の集まりは、このポジションにより適しているのでしょうか?Indeed のあるチームが、履歴書が職務内容に記載されたスキルや経験の要件を満たしている尤度を計測するモデルを作成しました。
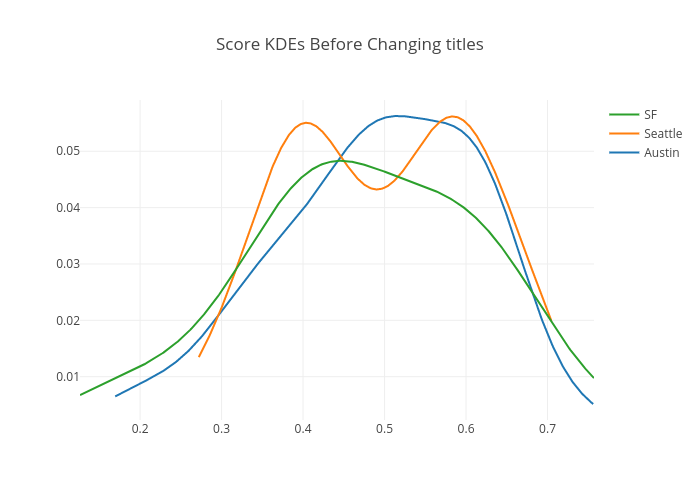
2月1日から3月14日までの間に、(職種名を変更する前の)プロダクトサイエンティストの求人に応募した全候補者に対してこのモデルを適用し、各候補者に対するスコアを取得しました。オースティン、シアトル、SF の平均スコアはそれぞれ順に 0.489、0.498、0.471 となりました。以下のプロットは、オースティン、シアトル、SF のカーネル密度推定を表しており、表は t 検定とコルモゴロフ–スミルノフ (KS) 検定の p 値 ( 有意ではない ) を示しています。KS 検定は、2 つの標本が同じ分布から掲示されているか判定しようと試みるものです。この検定はノンパラメトリックであり、データ分布に対しての仮定は行いません。いずれの検定も、職種名変更前は、3 都市の間で、応募者が要件を満たしている率が同じレベルであることを示しています。
職種名変更後の全応募者にモデルが適用された際、オースティン、シアトル、SF の平均スコアはそれぞれ順に 0.466、0.516、0.528 となりました。オースティンの平均スコアが小さく減少し、シアトルと SF のスコアが上昇しているのを観測しました。以下のプロットはオースティン、シアトル、SF のスコア分布を示しています。p 値を調整するために False Discovery Rate を制御した後、いずれの検定も、職種名変更後(シアトルおよび SF)の応募者が要件を満たしている率は、元の職種名(オースティン)のそれよりも、有意に高くなっていました。一方、変更した職種名(「データサイエンティスト: プロダクト」と「プロダクトサイエンティスト: データサイエンス」)自体に対しては、はっきりとした違いはありませんでした。
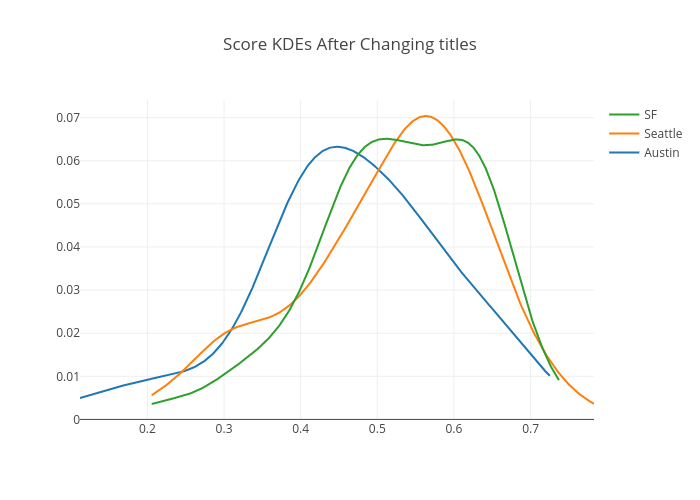
これらの発見に驚きましたか?私たちの試験的なリサーチにより、職種名に単純に小さな変更を加えることで、より適性の高い多くの候補者が集まることがわかりました。あなたが考えるよりもずっと、職種名は重要です。興味を引くきっかけとなるため、職務内容と同じくらい注力されるべき事柄です。こうしたことから、職種名も気にかけ、求職者に見つけてもらいやすく、また目に止まりやすい職種名を選ぶべきでしょう。
さらに詳しく読んでみたいという方に、因果効果を確立するためのより厳格なアプローチとして以下を紹介します。
- ランダム化実験計画。これは、一つまたは複数の応答変数に対する因子の効果を観測するために、恣意的に一つまたは複数の因子を変更し ます。
- 構造方程式モデリング³ やルービンの因果モデル⁴ などの因果推論モデル。利用することで、観測研究や、実験研究における因果効果を統計学的に分析することできます。
ももしあなたが科学的手法を利用したプロダクトの改善や開発、そして人々の職探しに役立つことに興味がある場合、Indeed で募集中のプロダクトサイエンティストとデータサイエンティストの求人をぜひご覧ください!
本記事は、現在連載中の Indeed におけるデータサイエンスについて特集しているシリーズの第二回となります。同僚のClint Chegin による第一回の投稿 「データサイエンティストなんてものはない」もぜひご覧ください。
脚注:
1. Z 値の仮説テストの p 値はテストの検定統計量です。もし帰無仮説は真である(係数がゼロである)場合、少なくとも、取得したうちの一つと同じくらいまれな検定統計量の確率を示しています。この確率が低い場合に、係数が本当にゼロであれば、このようなまれな結果を得ることはなかなかないことを示しています。Signif. code は各見積もりと関連しており、有意性のレベルにフラグを立てることだけを目的としています。アスタリスクが多ければ多いほど、p 値がより有意となります。例えば、3 つのアスタリスクは高い有意の p 値を表しています( p 値が0.001 以下の場合)。
2. これらのモデルのスコアは標準ではなく、また確率ではありません。応募のスコア 0.8 というのは、0.4 のスコアを持つ応募と相対して、さらに高い尤度を表しています(もっともらしさが 2 倍という意味ではありません)。
3. Bollen, K.A.; Pearl, J. (2013). “Eight Myths about Causality and Structural Equation Models”. In Morgan, S.L. Handbook of Causal Analysis for Social Research. Dordrecht: Springer. pp. 301–328.
4. Sekhon, Jasjeet (2007). “The Neyman–Rubin Model of Causal Inference and Estimation via Matching Methods” (PDF). The Oxford Handbook of Political Methodology.