
Indeed は、求職者の仕事探しのお手伝いをする方法を探しながら成長し、さまざまな形で求職者に求人情報を提供してきました。Indeed.com での求人検索、おすすめの求人情報の送信、求人の有料掲載やターゲット広告、スカウトなどはその一例です。それぞれ求人の提供方法は少しずつ異なりますが、「求職者に最適な求人情報を届ける」という同じゴールを目指しています。
求職者の希望に沿わない求人を表示すれば、Indeed を利用してもいい仕事は見つからないと思われて、信頼を失うかもしれません。Indeed のミッションは「We help people get jobs (人々の仕事探しのお手伝い)」であり、時間を浪費させることではありません。
Indeed では、次のような求人は求職者が求めている求人ではないと考えています。
- 給与の額が希望より低い
- 求職者が持っていない資格を必要とする
- 希望する勤務地ではない
- 希望する分野と関連性はあるがミスマッチである (看護師と医師に同じ求人がオファーされる、など)
こうした問題を減らすため、求職者にとって明らかにミスマッチな仕事を除外するジョブフィルターを作成しました。Indeed では、ヒューリスティックルールと機械学習の技術を組み合わせたソリューションを使用しており、分析結果からこの手法は非常に効果的であることが分かっています。
システム構成
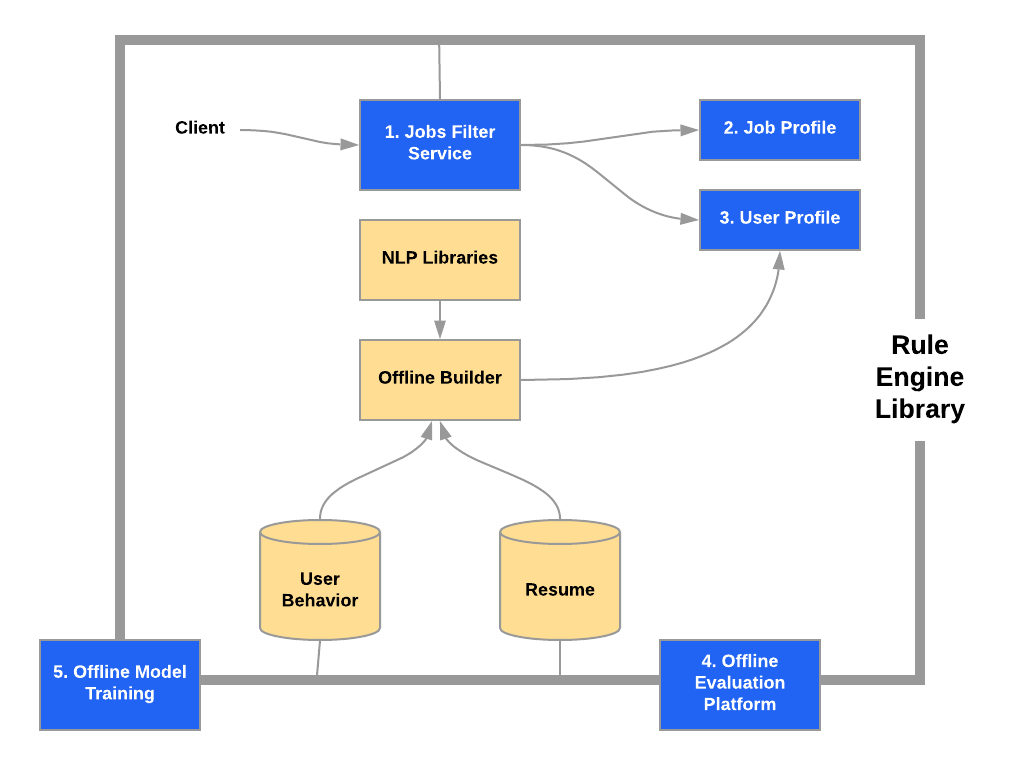
上の図からもお分りいただけると思いますが、ジョブフィルターは次のコンポーネントで構成されています。
- ジョブフィルターサービス: ユーザーを ID で特定し、ユーザーごとに求人のマッチ度を評価する、高スループット、ローレイテンシーのサービスです。このサービスは、求人がユーザーIDに対して適切だと判断すれば ALLOW を、不適切だと判断すれば VETO を返します。水平スケーラビリティの高いサービスであるため、Indeed の多くのリアルタイムアプリケーションで使用されています。
- ジョブプロフィール: 高スループット、ローレイテンシーのパフォーマンスを提供するデータストレージサービスです。給与の予測、職種、勤務地など、求人の属性を読み出します。Indeed NLP ライブラリと機械学習技術を使用して、ユーザー属性の抽出や集約を行うことができます。
- ユーザープロフィール: ジョブプロフィールと似ていますが、求人ではなく求職者の属性を提示します。ジョブプロフィールと同様、高スループット、ローレイテンシーのパフォーマンスを実現するデータストレージサービスです。希望する給与、現在の職種、希望する勤務地など、求職者の属性を読み出します。ジョブプロフィールと同様、Indeed NLP ライブラリと機械学習技術を使用し、ユーザー属性の抽出や集約を行うことができます。
- オフライン評価プラットフォーム: 履歴データを利用し、上流工程のアプリケーションと統合させずに、ルールの有効性を評価します。既存のルールの調整や新しいルールの特定、新しいモデルの検証にも多用されています。
- オフラインモデルトレーニング: Indeed のオフライントレーニングアルゴリズムを構成するコンポーネントです。評価時の、ジョブフィルターのルールで使用できるモデルのトレーニングに使用します。
求人のマッチングを改善するフィルタールール
ジョブフィルターは、ルールを使用して求職者に表示される求人の質を改善しています。ルールは非常にシンプルです。「専門的な資格が必要な求人は資格を持っていない求職者に表示しない」や「大幅な減給となるような求人は表示しない」などがその一例です。一方、「求職者が興味を持たないと確信できる職種の求人は表示しない」、「複雑な予測モデルが、この求職者は興味を持たないだろうと示唆した求人は表示しない」など、複雑なルールもあります。
ルールはすべて、意思決定エンジンライブラリに蓄積されます。Indeed ではこのライブラリを、オンラインサービスとオフライン評価プラットフォームで共有しています。
ジョブフィルターのルール構築の基礎となるデータの収集は複雑かもしれませんが、大半のヒューリスティックルールの設計や実装方法はシンプルです。たとえば、ユーザーの反応予測モデルを使用して、求職者が興味を持ちそうにない仕事を除外するというルールがあります。Indeed 独自の評価指標では、求職者と表示される求人のマッチングの質を測定し、パフォーマンスを評価しています。
広告ランキングとリコメンダシステムは、通常、クリック予測やコンバージョン予測といったユーザーの反応予測モデルを基にスコアを生成し、スコアが低いものを除外するための閾値を設定します。モデルでユーザーのポジティブな反応を予測し、低いスコアでマッチングの質の低さが分かるので、求人を絞り込むことができます。
Indeed のジョブフィルターにもこのような技術を採用していましたが、機械学習に基づくルールを作成したときは、ネガティブキーワードモデルを使用しました。ユーザーからのネガティブな反応を予測するモデルを構築し、Tensorflow を使用して、ワイド&ディープモデルを構築します。これらのモデルは、Factorization Machines やニューラルネットワークといったより複雑なモデルの今後の実験に役立ちます。Indeed で使用している機能は、主なユーザー属性や求人データを網羅しています。
パフォーマンスの良いモデルをトレーニングしてから、Tensorflow SimpleSave API を使用してエクスポートします。エクスポートしたモデルをオンラインシステムに読み込み、Tensorflow Java API を使用してリクエストに対応します。AUC、Precision、Recall といった従来の分類指標に加え、Indeed のモデルもオフライン評価プラットフォームに読み込んでパフォーマンスを評価します。
ジョブフィルターの適用例
Indeed では、ジョブフィルターを複数のアプリケーションに適用しています。その一つが Job2Job で、求職者がクリックした求人や応募した求人に基づいて、関連性の高い求人を推薦するアプリケーションです。Job2Job のサービスを使用することで、求人のマッチング率を20%以上向上させることができました。このサービスを他のアプリケーションに適用したときも、上回るとまではいかなくても同程度の改善が見られました。
ルールベースのエンジンは、滅多に発生しないケースを解決するのに役立ちますが、ルールの数が多くなりすぎると手に負えなくなってしまいます。ルールの階層構造の作成方法や機械学習技術により、こうした課題を効率よく解決し、システムの可用性を維持できています。今後は、より効果的なモデルとなるよう、さらに多くの機能を追加していこうと思っています。