この投稿は、2部構成となっているシリーズの第1部です。
私たちのチームは、2019年に、Kubernetes、Docker、Mesos など、ハードリミットが設定されたほぼすべてのコンテナオーケストレータに影響する CPU スロットリングの問題を解決しました。この過程で、応答遅延で大きな問題があった Indeed のあるアプリケーションでは、遅延が2秒から30ミリ秒に短縮されました。この2部構成のシリーズでは、根本的な原因を見つけ、最終的にソリューションへとたどり着いた取り組みについて説明します。

Photo by twinsfisch on Unsplash
この問題が発生したのは昨年、Linux カーネルの v4.18 がリリースされてから間もなくのことでした。Indeed のある Web アプリケーションで応答時間が長くなっていることを把握したのですが、CPU の使用量を確認しても問題はありませんでした。さらに調査した結果、この現象は、CPU スロットリングが高い期間と直接関係があることが明らかになりました。何かが正常に動作していなかったのです。通常の CPU 使用量でスロットリングが高くなることはあり得ません。最終的には犯人が見つかったのですが、まずは問題のメカニズムについて確認する必要がありました。
背景: コンテナの CPU の制約の仕組み
ほぼすべてのコンテナオーケストレータは、kernel control group (cgroup) メカニズムによってリソースの制限を管理しています。コンテナオーケストレータで CPU のハードリミットが設定されている場合、カーネルは Completely Fair Scheduler (CFS) Cgroup の帯域幅制御を使用して、ハードリミットを適用しています。 この CFS-Cgroup の帯域幅制御のメカニズムは、クォータと期間の2つの設定を使用して CPU の割り当てを制御しています。アプリケーションで、割り当てられた CPU クォータが一定の期間使用された場合、そのアプリケーションは次の期間までスロットリングの対象となります。
cgroup に関する CPU のすべての指標は /sys/fs/cgroup/cpu,cpuacct/<container> にあります。クォータおよび期間の設定は、cpu.cfs_quota_us および cpu.cfs_period_us にあります。

また、スロットリングの指標は cpu.stat で確認できます。cpu.stat には以下が記載されています。
nr_periods– cgroup 内のいずれかのスレッドが実行可能だった期間の数nr_throttled– アプリケーションがクォータ全体を使用し、スロットリングの対象となった実行期間の数throttled_time– cgroup 内の個々のスレッドがスロットリングの対象だった期間の合計
応答時間の悪化を調査していたとき、あるエンジニアが、応答時間が長いアプリケーションではスロットリング期間 (nr_throttled) が非常に長いことに気づきました。私たちは nr_throttled を nr_periods で除算し、スロットリング期間が非常に長いアプリケーションを特定するための重要な指標を見つけました。この指標は「スロットリング率」と呼ばれています。throttled_time は、スレッドの使用程度に応じてアプリケーション間で開きがある可能性があるため、使用しませんでした。
CPU 制限の概念モデル
CPU 制限の仕組みを理解するために、ある例を見てみましょう。シングルスレッドのアプリケーションが、cgroup の制限が設定された CPU で実行されているとします。このアプリケーションが要求を処理するには 200 ミリ秒が必要です。制限がない状態では、応答は次のグラフのようになります。
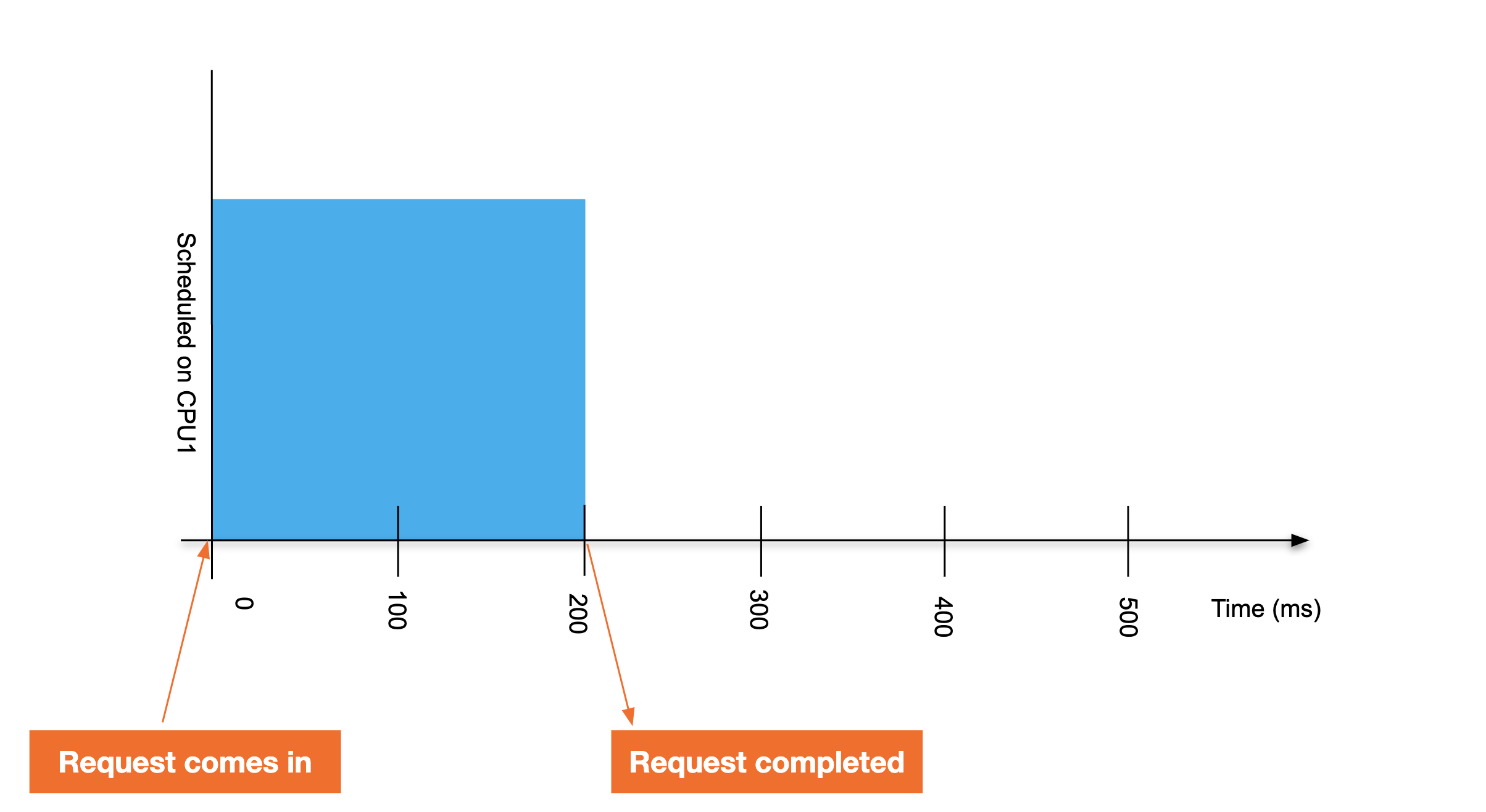
ここで、アプリケーションに0.4 CPU の CPU 制限を割り当てます。アプリケーションに対して100ミリ秒の期間ごとに 40ミリ秒の実行時間が付与されるということを意味します。CPU に他のタスクがない場合も含まれます。これで200ミリ秒の要求は完了まで440ミリ秒かかるようになりました。
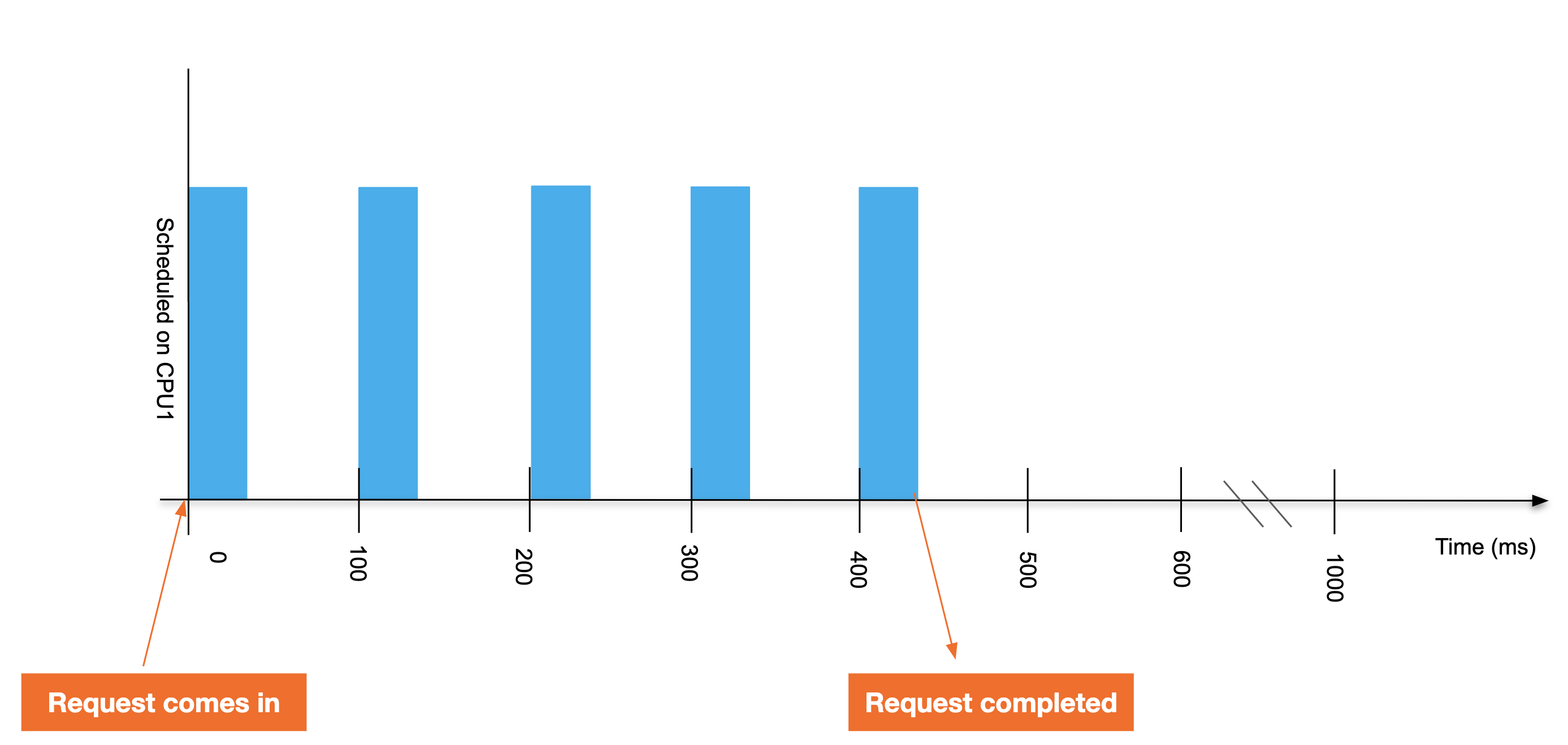
1,000ミリ秒間の指標を収集すると、この例の統計は次のようになります。
| 指標 | 値 | 理由 |
nr_periods |
5 | 440ミリ秒~1000ミリ秒まで、アプリケーションは何もしなかったので実行できなかった |
nr_throttled |
4 | アプリケーションは実行可能ではなくなったため、5つ目の期間にはスロットリングが適用されなかった |
throttled_time |
240ミリ秒 | アプリケーションは100ミリ秒ごとに40ミリ秒しか実行できず、60ミリ秒の間スロットリングの対象だった。4つの期間がスロットリングの対象だったため、スロットリングの合計期間は4に60を乗算した240ミリ秒になる。 |
throttled percentage |
80% | 4つの nr_throttled を5つの nr_periods で除算 |
しかし、この統計は概念上のものであり、現実のものではありません。この概念モデルにはいくつかの問題があります。まず、私たちが生きているのはマルチコア、マルチスレッドアプリケーションの世界です。次に、この統計が完全に正しかったとしても、問題が発生しているアプリケーションでは CPU クォータが枯渇するまでスロットリングは開始されません。
問題の再現
私たちは、問題が実際に存在し、修正の必要があるとカーネルのコミュニティを説得するには、簡明な再現のためのテストケースが役に立つということを理解していました。そこで多数のストレステストと Bash スクリプトを試行しましたが、動作の確実な再現は難航しました。
この状況を打破できたのは、多くの Web アプリケーションでは非同期のワーカースレッドが使用されていることに気づいたからでした。このスレッドモデルでは、各ワーカーに対して完了すべき小規模のタスクが付与されます。たとえば、こうしたワーカーは IO などの少量の作業を処理します。こうしたワークロードを再現するために、私たちは C で Fibtest という小規模な再現のためのテストを作成しました。予測できない IO を使用するのではなく、フィボナッチシーケンスと休止期間を組み合わせて使用することで、こうしたワーカースレッドの動作を再現し、高速なスレッドと低速なワーカースレッドを区別しました。高速スレッドはフィボナッチシーケンスを可能な限り反復処理しますが、低速スレッドは100 の反復を処理した後に、10ミリ秒休止します。
スケジューラに対して、これらの低速なスレッドは、小規模な作業を実行した後休止するという、非同期ワーカースレッドにより近い形で動作しました。確認ですが、最終的な目標はフィボナッチの反復処理を最大にすることでなく、低い CPU 使用量と同時に高いスロットリングが実施される状況を確実に再現するテストケースを作成することです。こうした高速スレッドと低速スレッドをそれぞれの CPU に固定することにより、ついに、問題となっている CPU スロットリング動作を再現するテストケースを作成することができました。
最初のスロットリングの修正と不具合
次のステップは、カーネルで git bisect を実行するために Fibtest を条件として使用することでした。このテクニックを利用することで、過剰なスロットリングの原因となっているコミットである512ac999d275 “sched/fair: Fix bandwidth timer clock drift condition” を素早く検出することができました。この変更は、4.18 カーネルで導入されたものです。このコミットを削除した後にカーネルをテストすると、低い CPU 使用量で高いスロットリングが実行されるという問題が修正されました。しかし、このコミットと関連するソースを分析したところ、この修正は完全に有効なようでした。さらに混乱することに、このコミットは不慮のスロットリングを修正するために導入されていたのです。
このコミットが修正した問題は、たとえば実際の CPU 使用量とは関係がないように見えるスロットリングでした。原因はコア間のクロックのずれであり、これにより、ある期間のクォータをカーネルが早めに有効期限切れにしていたのです。
幸い、この問題が発生するのは非常にまれでした。ノードの大半がすでに修正が適用されたカーネルを実行されていたためです。しかし運悪く、1つのアプリケーションでこの問題が発生してしまいました。このアプリケーションはほとんどアイドル状態で、4.1 CPU が割り当てられていました。その結果、CPU の使用量とスロットリング率のグラフは次のようになりました。
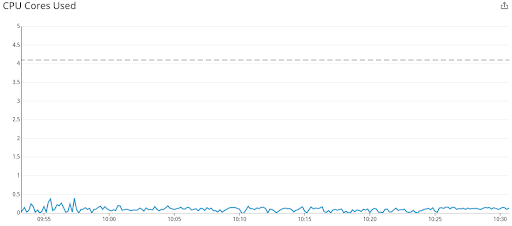
4 CPU が割り当てられ、使用量が 0.5 CPU を超えていない CPU 使用量のグラフ
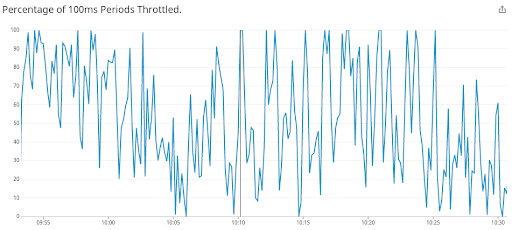
過剰なスロットリングを示すスロットリング率
コミット512ac999d275 ではこの問題を修正し、多数の Linux-stable ツリーにバックポートされました。このコミットは RHEL、CentOS、Ubuntu など、大半の主要なディストリビューションカーネルに適用されました。その結果、一部のユーザーは、おそらくスロットリングの改善を確認しているはずですが、その他のユーザーの多くは、この調査を開始することになった問題を目にしている可能性があります。
取り組みのこの時点では、大きな問題を確認し、再現のためのテストを作成し、問題となっているコミットを特定しました。このコミットにはまったく問題がないように見えますが、悪影響をもたらす副次的効果がありました。このシリーズの第2部では、根本原因についてさらに説明し、概念モデルを更新して CFS-Cgroup CPU 制約の実際の仕組みを説明し、カーネルに対して最終的にプッシュされたソリューションについて説明します。