Originally published on InfoQ.
カスタマー向けソフトウェアを納品し続けている企業で働いているところを想像してみてください。あなたの組織は不可能なはずのことをやってのけ、重大なインシデントがまったく発生しなくなりました。つまり、100%の信頼性を実現したのです。そのプロダクトは高速で、便利さ、使いやすさ、信頼性に優れ、素晴らしいものでした。導入が拡大し、ユーザーは新しい機能を要望し、この成功は、次第に当たり前のものとして定着していきました。それに伴い、機能をもっと迅速にリリースしてほしい、もっと収益や費用対効果を上げてほしいなど、あなたの組織に次から次へとさまざまなプレッシャーがかかりはじめました。一方、ワークライフバランスが企業の優先事項に定められているので、従業員に長時間労働を強いることはできないなど、制約はほかにもあります。この短期的な成功と同時に、こうした制約が重なると、やがてどんなことが起こるでしょうか?

このような高い信頼性が実現された環境では、インシデントに対応したり、レトロスペクティブに取り組んだり、アクションアイテムを実行することに従業員が時間を使うのではなく、効率化に対するビジネス面でのプレッシャーを解決するためにより多くの時間をかけられます。
インシデントが起きなくなることのトレードオフは、本番環境でインシデントに対応したり、プロダクトを理解するために従業員同士が協力して成果を上げる実務的な機会がなくなることです(運用負荷の不足を状態を表すOperational underloadと呼ばれます)。作業のスピードやペース、複雑さは増大し続けます。新しい従業員は業務量の増加に対処するために採用され、育成されます。予測しなかった脅威がシステムに影響を及ぼすでしょう。
結果として、インシデントの数が増えます。
インシデントは、急激すぎる変化が起きている場合や、人間が考えるシステムのモデルと、実際のシステムの間に食い違いがあるというシステムからのシグナルです。インシデントは、変化のペースを安定させるバッファーです。the Law of Stretched Systems(拡張されるシステムの法則)によれば、システムが正常に稼働している限りインシデントは必ず起きるため、完璧に防ぐことはできません。この必然性を受け入れることが、複雑さと相互関連性がますます高まっていく環境で成功を継続するための鍵になります。
ソフトウェア業界で私が目の当たりにしているのは、最善ではない近視眼的な対策を取り、そこから抜け出せない状況です。安全性へのアプローチは頭打ちになっており、複雑さとスケールの増大への対処法を改善しなければ、そのうち非常に厄介なことになるでしょう。
Indeed では、これまでの成功を維持しつつ、変化する複雑性やスケールの拡大に対応していくために、組織の変革を推進する必要性を認識してきました。過去16年間にわたって Indeed は急速な成長を遂げ、変化のペースは加速しています。Indeed はこの状況に適切に対処することの重要性を認識しており、私の所属するResilience Engineering部門では、Learn & Adapt(学習と適応)という安全策へ方針をシフトしています。
この記事では、ソフトウェア業界が押しやられつつある方向に対抗するために、このような方針転換が必要であることを提言し、このシフトを実現するために必要な取り組みについて説明します。最後に、継続してこの安全策の方針転換を行う体制が整った組織の特徴を考察します。このシフトにより、組織の安全性が高まるだけでなく、Allspaw氏(2020年)が指摘したように「最も重視する点を修正から学習に移すことで、大きな競争上の優位性が獲得できる」ことになります。
安全性へのさまざまなアプローチ
複雑さやスケールの増大に立ち向かうには、局所的な対策を取る姿勢から脱却し、業務への取り組み方を変える必要があります。この方針転換とは、今日のソフトウェア業界で一般的な、Prevent & Fix(防止して修正する)という従来の方針から離れることを指します。防止して修正する安全策の特徴は、アクシデントの回避、厳格な管理、障害箇所に対処することを重視している点にあります。
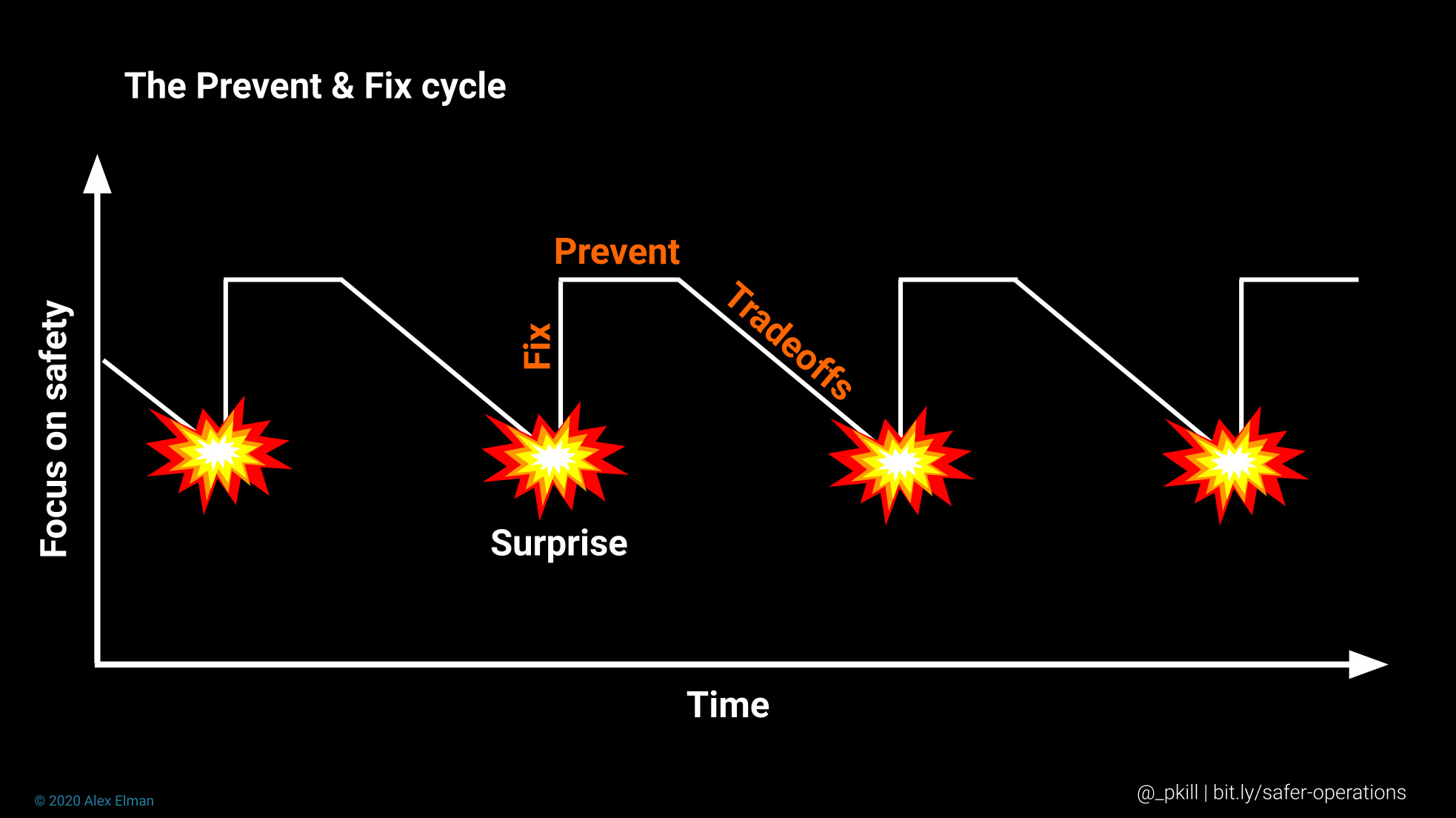
Prevent & Fix (防止と修正)のサイクル
このタイプの安全策に固執する組織は、予期せぬ出来事にどうやって対処するか、じっくり集中して考えることをしません。さらにこうした組織は、それほど重要でないものの修正に多大な時間をかけてしまう可能性があります。ときには、防止作業が適応する機会を阻害することもあります。たとえば、WHERE節のないUPDATE文を禁止するMySQLセーフモードを本番環境でオンにすると、この種の間違いの再発を防止できるかもしれませんが、インシデント発生時にDBAが急いでMySQLコマンドラインを起動して重要な修正を行おうとしたときに、セーフモードが邪魔になることもあります。
一方で、Learn & Adaptというアプローチの安全策を実践すれば、インシデントに対応することを通じて、普段の日常的な作業がどのように安全性を生み出しているのか、よりよく理解できるようになります。防止と修正よりも学習と適応を優先すれば、防止と修正の能力を高めることにもつながります。このことが運用の安全性向上にもたらす効果については、SREcon20 Americasで私が行ったセッションでさらに詳しく説明しています。
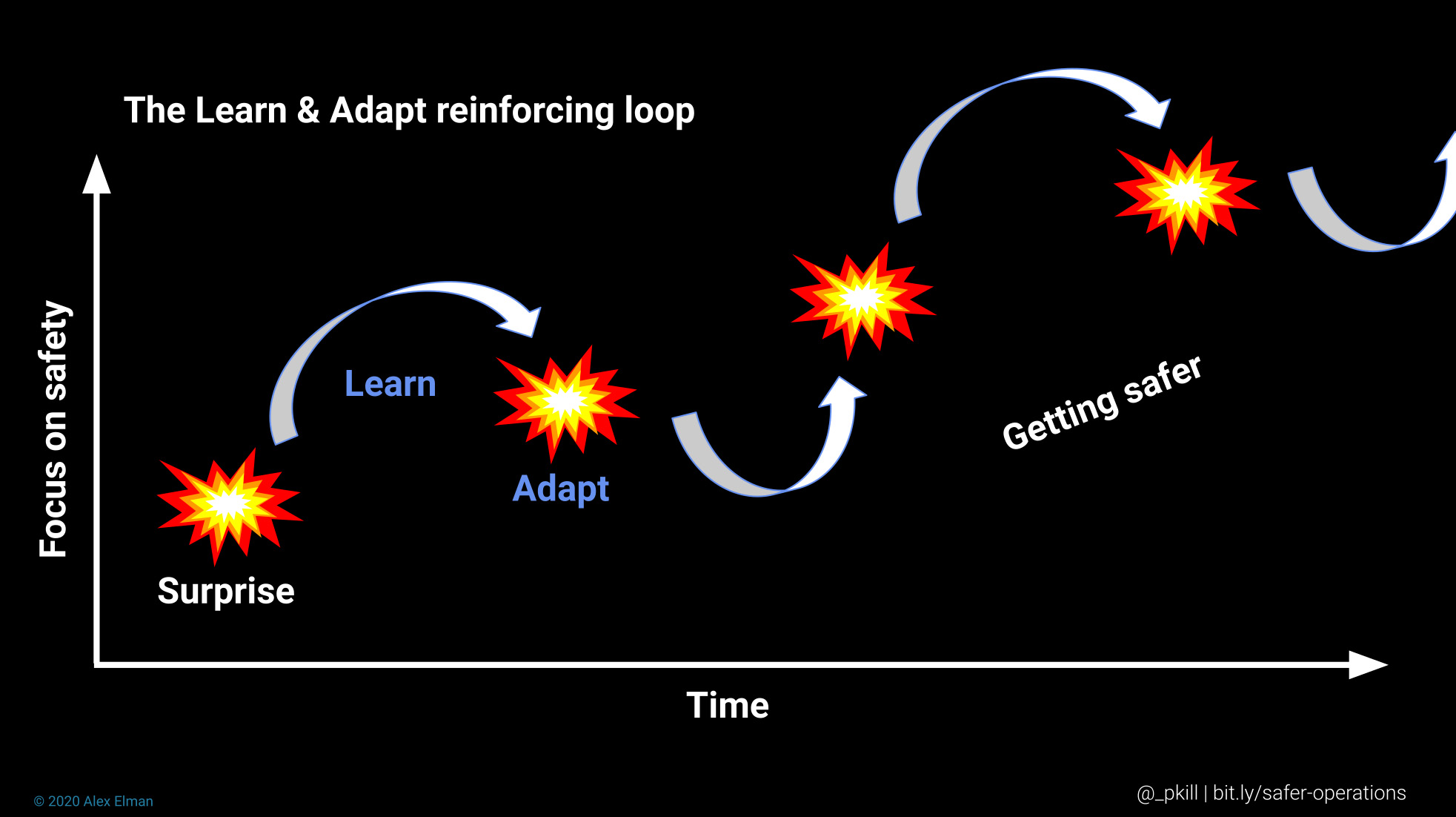
Learn & Adaptの強化ループ
Learn & Adaptのアプローチが、アクシデント回避と限定的な修正を主眼とするアプローチよりも優れていることについては、Resilience Engineeringの研究論文ではおおむね意見が一致しているようです。このアプローチをほかの組織よりうまく実践している組織には、いくつかの特性があります。InfoQシリーズの第1項で述べられているように、新型コロナウイルス感染症の世界的大流行について、組織の誰かが予測するべきだと期待するのは不条理ですが、不測の事態が起きることを見込んで準備をしておくことは、まったく理にかなっています。時間をかけて重点的な取り組みと投資を続けることで、組織は不測の事態にうまく対応できるようになっていきます。
この方針の転換を実現する例の1つは、組織のインシデントへの対応の仕方にあります。防止と修正の安全策では、インシデントは、チームのパフォーマンスやプロダクトの品質が悪い証拠、あるいは避けられた損失と見なされ、1つの主原因が「The Five Whys」などの原因分析手法によって解明されます。たいてい、分析はそこで終わります。一方、Learn & Adaptという方針では、インシデントをレンズとして使うことが奨励されます。組織はそのレンズを通して、プロセスや意思決定、コラボレーション、仕事の進め方を見ていきます。このために、人的要因の50%以上に焦点を当てるインシデント分析ループが使用されます。
方針の転換は、新しいチームの結成や役職の変更、適材の採用、適切なベンダープロダクトの購入によって起きるのではなく、すぐに実現できることでもありません。
この方針の転換を実現するには、組織が内部から変化する必要があります。始まりは、組織に変化の種をまくところからです。種が苗に育ったら、組織は継続的な学習と適応の強化サイクルを完成させる作業に着手できます。この強化ループを育成するには、繊細な植物を世話するときと同じように、養分を絶やさず、よく観察する必要があります。注意したいのは、苗は土壌からでなければ生え出ることができず、適切な配合の栄養素と正しい環境条件が揃わなければ育たないことです。このような栄養素と条件の多くは、企業文化に関連しています。
組織的な変化を促す
私がこの分野に真剣に注目するようになったきっかけは、数年前、1時間のレトロスペクティブに数回続けて参加したときの経験でした。これらのミーティングに招かれた理由は、私がSREだったことと、インシデントの要因の一部ともなっていたRabbitMQ分野のエキスパートとして認識されていたからです。そこで見たのは、せっかくの機会を無駄にしているとしか思えない状況でした。
ミーティングでは毎回、会議室に十数人以上が集まり、時には立見の参加者がでることもありました。ファシリテーターがアジェンダにそって話を進め、スケジュールやアクションアイテムの確認、要因を検討するなど、時間がもったいない会議でした。テンプレートに沿って進め、インシデントの発生状況を延々と再現するだけのプレゼンテーションでした。すべてのアジェンダを話し合って質疑応答が終わっても、25~30分程度でミーティングが終わり、早めにお開きとなることもありました。熱意のあるたくさんの人たちが部屋に集まってインシデントについて議論する機会だったのに、起きた問題について何の改善も理解の深まりもないままミーティングは終わりました。
ファシリテーターはプロセスに忠実に従っていたので、問題はプロセス自体にあることが明らかでした。このプロセスをもっと効果的にする方法を知りたいと思いました。この調査を進める中で、最初に思っていたよりもずっと大きなことがインシデント自体から学べることに気付きました。
プロセスの変更が必要だと認識したので、Indeed がレトロスペクティブを行う理由を同僚に聞いて回りました。集まった主な意見は次のとおりで、ソフトウェア開発に携わる人たちには馴染みのあるものだと思います。
- 障害発生の原因を解明するため
- 影響の大きさを測定するため
- 障害発生の再発防止を徹底するため
- 改善項目をリストアップし、担当者を決めるため
これらの意見には、Indeed 従業員の強い当事者意識が表れていますが、重要なのは、Indeed のシステム(人とテクノロジーの両方)と、システムに対する人間の思い込みをより詳しく分析する方向に労力を注ぐためにレトロスペクティブを活用することです。あるサービスがインシデントに関係していた場合、そのチームは、自分たちが思っていた以上に障害発生が近かったのかもしれないという懸念を持ちます。優先順位を一時的に変更し、チームのメンバーはプロセスや設計の選択肢をより注意深く検討するようになります。
これまでとは異なる Indeed 社内での企業文化へのこのようなアプローチはまだ比較的新しく、広がりを見せ始めている段階ですが、最初の反応を見ると前途は有望のようです。最近の学習レビューでインシデント報告書について話し合った後、以下のようなフィードバックを受けました。
報告書の内容は興味深く多岐にわたり、Indeed 独自のコンテキストが効果的に要約されていたことから、意義のある議論をするための土台として役立つものだった。参加者の振り返りも熟考されており、彼らの考え方についての新たな情報も率直に共有されていた。これらは、メンタルモデルの改善や結束力の強化につながったほか、素晴らしい学びの機会となった。
前進はしていますが、まだまだやることがあります。Indeed での経験や、何百というインシデントに立ち会った経験、研究論文との関わりなどが自分の取り組みに役立ったほか、組織面では以下の3つの要素がこれまでの前進に貢献してきたと思っています。
- 社内で賛同者を見つける
- 幅広いコミュニケーションを図る
- いくつかの重要な行動を常態化する
賛同者を見つける
賛同者とは、目標達成への方向性が一致し、改善点を認識し、どうあるべきかというビジョンが共有できるような同僚を指し、彼らの存在は、組織の変革を推進するための助けになります。新しい行動の規範となる同僚が数名いることで、全社的な変化が促進され、ムーブメントが生まれます。この変革を1人で起こすのはとても困難なことです。私はこうした賛同者を見つけることができましたし、皆さんの企業にも必ずいるはずです。広い心を持ち、さまざまな視点を受け入れる好奇心を持っている同僚が、あなたの賛同者です。
こうした賛同者の1人を見つけたのは、2020年に起きたインシデントを分析していたときでした。インシデントの周辺に関わっただけの人物と1対1の報告面接をした際に、なぜグループ改善セッションに参加したのか、その面接相手に尋ねました。その人の答えから、賛同者は作られるのではなく、必然的に見つかるのだということが実証されました。
自分が直接関係していなくても、ほとんどすべてのインシデント(に関するSlack)チャンネルになるべく参加するようにしています。こういうことが、自分たちのインフラストラクチャがどうなっているのか、物事がどう動いているのか、緊急事態が起きたときには誰に連絡するべきか、誰が解決してくれるのか、といったことを知るのに一番役に立つのです。たくさんのことをここから学びました。先ほど言ったように、不具合が自分と直接関係なくてもです。
賛同者が見つかる場はインシデント報告面接だけではありません。社内のリーダーや関係者と何度も1対1で話し合いましたし、ミーティングでもこのようなトピックを話し合う機会を探しました。各国の Indeed のエンジニアリングオフィスを訪問するたびに、社内テックトークを行って賛同者になってくれそうな人たちに発信してきました。社内テックトークには、関心の一致する人や共有したいストーリーを持つ人々を引き寄せる効果があります。たとえばトークの後に話しかけてくるなどして、自己紹介をしてくれるのです。その人たちが、組織内でムーブメントを定着させるために一役買う賛同者になるかもしれません。Indeed のオフィスは世界中にあり、さまざまなタイムゾーンにまたがっています。これらのオフィスそれぞれに賛同者がいれば、キャンペーンに一貫性が生まれます。
幅広いコミュニケーションを図る
組織の変革を推進するために重要な2つ目の要素は、1つのチームや部門の中だけでなく、組織全体にわたってメッセージを発信することです。幅広いコミュニケーションを図る際には、組織の規模が大きな影響を及ぼします。10,000人規模の組織で発信する際には、1,000人や100人の組織とは異なる課題が生じるものです。
新しいプログラムの詳細について十分にコミュニケーションを取っているといくら思っていても、たいていは不十分です。私は、コミュニケーションは過剰と感じるくらい発信しなければいけないのだということを学びました。さまざまなチャンネルを活用して過剰にコミュニケーションを取っていると、私のメッセージに近い位置にいる人にはくどいと思われるかもしれませんが、こうしなければ声が聞こえないような組織の隅々にまでメッセージを届けるには、この手段しかありません。
インシデントの発生後、チームが修正措置を特定して適用する際にも、同じようなコミュニケーションの課題が表面化します。これらの措置は、そのインシデントを経験した部署にしかメリットをもたらさない「ローカルのみ」の修正、介入、教訓であることが多く、グローバル組織は時として高い代償を払いながら、この教訓を学ばずに終わります。
組織行動論の研究者であるRon Westrum氏は、「A typology of organisational cultures」の中で以下のように述べています。
意識的探求の文化における最も重要な特徴の1つは、システムの一部分で知られていることが残りの部分に伝達されることです。このコミュニケーションはグローバルな修正に必要なもので、システムの安全性のためにきわめて重要な、経験からの学習を促進します。このコミュニケーションが発生する理由は、システムの構成員が、潜在的な危険や可能な改善について他者に伝えることを自らの責務と考えているからです。
技術面での重要な修正や学んだ教訓をレトロスペクティブ資料に記録して対処するだけでは、チームにとって十分ではありません。Allspaw氏(2020年)がソフトウェア組織のインシデントへの取り組み方を2年かけて観察した結果、「実務的な技術者は一般に、インシデント後の報告書を自分のローカルチーム外の読み手に向けて記録しない」こと、さらに「他のチームが作成したインシデント後のレビュー報告書を読むこともない」ことがわかりました。
インシデントからの学びが組織全体に浸透しない限り、組織は真の利益を得られません。役に立つ報告書は、読み手に新しい情報を与え、インシデントの複雑さを明確に伝えるものでなければなりません。
新しい行動を常態化する
組織の変化に伴って、新しい方針と行動が生まれます。その中には、従来のやり方と対立するものがあるかもしれません。あるいは、単に直観的に理解しがたい場合もあります。この違和感は、こうした望ましい行動を組織に定着させる妨げになります。手始めとしては、自分自身が変革の手本となり、実践するのが良いでしょう。こうした方針や行動を常態化することで、まず受け入れの早い人たちに変化が広まっていき、やがて全社的なムーブメントが生まれます。Learn & Adaptの安全性の方針を普及させるためには、重点領域が4つあることがわかりました。
1. 前提を最大限はっきりと述べることを常態化する
前提とは、自分自身にとってはあまりにも明白だったり、自明の理であることから、明確に述べる必要がないように考えがちです。このような、当たり前だと思っていたことが、他者にとっては驚くような話になることは非常によくあります。
たとえば、MySQLプライマリを別のデータセンターに自動的に安全にフェールオーバーすることはできない、という事実が、あなたにとってはあまりにも明白で、いちいち説明する価値もないと考えているとしましょう。しかし現実には、あなたの同僚はその正反対の考えを持っているかもしれません。
前提をはっきりと述べることで、相手と自分が異なる視点を持っている場合に、お互いの考え方を見直す機会になります。人々が集まって、めいめいのシステムに対する考え方を、互いに再検討する話し合いは、私が経験した話し合いの中で最も洞察に満ちたものです。前提をはっきりと述べるのに適した場は、設計レビュードキュメントやマージリクエストです。
10%のパケットロスが生じると、何が起きることを前提にしていますか?
パケットロスが50%の場合はどうですか?
システムクロックは常に単調に増加することを前提にしていますか?
あなたのコンシューマーサービスは、重複したメッセージが決して発生しないことを前提にしていますか?
そのサービスで実際に重複が発生した場合は、何が起こることを前提にしていますか?
こうした前提を明確に述べることは、重要な会話のきっかけになります。あなたが設計に関して前提にしていることに対して、こうしたレビューの参加者も各自の前提を持っているからです。あなたの前提が参加者自身のものと一致していれば、参加者がわざわざ異議を挟むことはないでしょう。
2. たくさん質問をすることを常態化する
システムのモデルの食い違いを明るみに出すために役立つアプローチがもう1つあります。好奇心は、Learn & Adaptの文化を育む大切な特性です。質問をすることで、自分でも気づかなかったような知識の欠陥が表面化することを心配するかもしれませんが、皆がたくさんの質問をすれば、その懸念もなくなります。
質問をすることは、職場の心理的な安全性を高めるためにも役立ちます。同僚が聞いている前で技術的なトピックについて議論するのは、非常に気疲れすることもあるでしょう。誰もが考え方のどこかに誤りを抱えているもので、議論を通じてこうした誤りが表面化することは避けられません。誰かが誤ったことを言った際の反応には、組織の通常のやり方が反映されがちです。もし、「あなたの今の発言にはいくつか問題があるんですが…」などと同僚に指摘すると、萎縮してしまい、今後は前提を共有する気がなくなってしまうかもしれません。明らかな誤りであっても、指摘ではなく質問をするようにしましょう。
考え方をさらに詳しく知るために、「コンパイル時にDeprecationの警告は何か出ましたか?」のようなフォローアップ質問をしましょう。訂正ではなく質問をすることで食い違いを明らかにすれば、問題空間の調査をより生産的に、心理的に安全なやり方で進めることができます。さらに、訂正する側が間違っていても許容される余地ができるので、心理的な安全性はさらに高まります。
3. 直接の関わり合いがなかった職種間で、より緊密に協力することを常態化する
この良い例は、プロダクト/エンジニアリングと、カスタマーサポートやクライアントサクセスなどのクライアント対応の職種です。これらのチームのメンバーに、設計レビューに参加してもらったり、レトロスペクティブやグループ学習レビューに参加してもらったりします。重大な問題が起きていることを組織で一番初めに知るのがクライアントサポートチームであることも珍しくありません。クライアント担当チームが問題を発見してから、プロダクトチームがその問題を認識するまでの時間がきわめて重要です。この遅れを短縮するために必要な作業は、インシデントの発生中にではなく、発生前に行う必要があります。
2019年に起きたインシデントは、クライアントサクセスチームによって最初に発見されました。インシデント分析の面接段階で、プロダクトチームがクライアントサクセスチームと直接どのようなやり取りをしたのか、プロダクトマネージャーに尋ねました。その答えは、この考えを頭から否定するものでした。「問題を把握するのに(カスタマー)フィードバックに頼っているようでは、(このインシデントの)解決策としては不十分だと思います。影響の大きな問題を特定するのに、そのような仕組みでは悠長すぎて役に立ちません。」
このインシデントの修正措置は、自動検出機能を追加することでした。その修正措置は、同じ影響が再び生じたときの検出には役立つでしょうが、クライアント担当チームとの連携や協力の改善に取り組む機会の妨げになっています。将来、影響を及ぼすインシデントが起き、それが既存の検出機能をすり抜けるようなものだった場合は、解決にさらに時間がかかるでしょう。
4. インシデント分析の成果を社内の全員で共有することを常態化する
インシデントの報告書を共有し、それについて議論することは、間違いなく最も重要な事後活動でしょう。複雑性への対処に関するthe SNAFUcatchers Workshopの第1サイクルで発表されたSTELLA reportで、この価値が以下のように強調されています。
ポストモーテム(障害報告書)によって、認識されていない依存関係、容量と需要の間の不一致、コンポーネントの連係に関する調整の誤り、技術面や組織面でのプロセスの脆弱性を指摘できます。また、このような状態を促進してしまう技術面、組織面、経済面、さらには政治面での要因についてより深く洞察するためにもポストモーテムは有効です。
ポストモーテムは、短期間で特定の問題に関する専門知識を集中的にまとめ上げます。ポストモーテムの参加者は、システムの仕組みと、その仕組みが機能しなかった状況について学ぶことができます。ポストモーテムは、それ自体が変化を引き起こすものではなく、注意が払われずに終わったかもしれない関心領域にグループの注目を向けるものです。
文化面での特性
防止と修正の安全策から、Learn & Adaptの安全策に移行するには、組織の業務の進め方を本質的に変える必要があります。あなたの組織がすでに首尾良くクライアントにプロダクトを提供している場合、組織に変更を加えることはリスクを伴い、無謀ですらあるかもしれません。変更から真の利益を得ようとするなら、変更は慎重に、漸進的に行わなければならず、継続的なモニタリングが必要です。
「セーフティカルチャー」という考え方には問題があるものの、組織がうまく不測の事態に備え、複雑さに対処し、インシデントから学ぶ能力と、企業文化には関連があります。企業文化とは、Westrum氏の定義(2004年)によれば、「…the organisation’s pattern of response to the problems and opportunities it encounters」です。組織の中で共有され、奨励される一連の行動や信条、アクションは、この「様式」(pattern)の形成に影響を与えます。文化規範によっては、インシデントの発生後に一連のフォローアップ行動が要求され、失敗の「責任を取る」ことが義務付けられているかもしれません。
私自身の組織内の文化規範を振り返ってみると、いくつかのトレードオフを正しく判断したことが、このLearn & Adaptに向けたシフトを醸成し、促進するために有効だったことがわかりました。
義務よりも機会
組織が責任や責務をどのように扱うかは、文化規範の一面です。甚大なインシデントの後、故障や不具合が起きたと見なされたシステムの部分にはたくさんの注目が集まります。個人やチームを特定して後始末を担当させ、復旧と予防の活動で責任感を見せてもらうのが、大きな損失が生じた場合によくある対応です。
義務と捉えるか、機会と捉えるかで、人々のタスクに取り組む姿勢は変わります。機会は勝ち取るものですが、義務は課されるものです(明示、暗黙を問わず)。タスクを魅力的な、明確に定義された、すぐ実行に移せるものにすることで、機会として強調するのがリーダーシップの役割です。
機会の魅力を高める方法の1つは、インセンティブの仕組みを変えることです。ソフトウェアインフラストラクチャエンジニアのRyn Daniels氏は、回復力のある文化を作り上げるためのレバレッジポイントを以下のように説明しています。
職場の精神的な安全性にはたくさんの要素が関わってきますが、学習を促し、相手を責めない文化を醸成する方法の1つは、組織内のインセンティブの仕組みを見直すことです。
インシデントの責任を負わせて後始末をするよう求める代わりに、その機会を皆が選びたくなるほど魅力的にすることを目指しましょう。Ryn氏は、以下の戦略を提案しています。
昇進に必要なスキルに、コミュニティへの貢献、ポストモーテムの進行、インシデントの報告書作成などが含まれている場合は、それも学習に重点を置いた活動に人々が参加したくなるインセンティブになります。組織内で見返りがあって奨励される行動は、その組織の文化に多大な影響を及ぼします。
義務を課す代わりに機会を作り出すことで、より充実した結果が得られるだけでなく、精神的な安全性も高まります。
厳格さよりも柔軟さ
意思決定、新技術の採用、アクセス権限、業務遂行中に許される行動について厳格な制約を設けると、回復力の源が弱体化し、適応の機会が損なわれることがあります。これらの制約は、過去に起きた重大なサービス障害によって、かさぶたのように時間をかけて蓄積していきます。
厳格な制約は、法的なリスク、セキュリティリスク、財務面でのリスクを回避するためには役立ちますが、柔軟性を抑え付けてしまいます。柔軟性が高ければ、従業員に好奇心を持つ余裕が生まれ、ほかの職種への関心が高まります。データベース管理者が頼まれもせずにセキュリティチームの手助けをしたら、組織はどのように反応するでしょうか?データサイエンティストが、自分の作業やプロダクトに関係ないコードレビューに参加したとしたら?「自分の持ち場に留まりなさい」という指示は、厳格さに偏った文化規範を象徴するものであり、人々の不安感や過去に起きた障害、必要な作業量が処理能力を超えることへの恐れなどが反映されているのかもしれません。
この柔軟性を高めておけば、インシデントの最中に意外なところから専門知識を発揮する人物が現れた場合に、計り知れない見返りが得られます。
スピードよりもアジリティ
Indeed でエンジニアリングにおいて重視される優先事項の1つは速さ、つまりアイデアからデリバリーまでの開発サイクルの短縮です。ソフトウェアのデリバリーにおいてスピードは重要ですが、予想外の問題に適応するためにスピードだけでは不十分です。「船の旋回」は、組織の規模やスピードが増すほど、素早い方向転換が困難になることを浮き彫りにする一般的なたとえです。
方針を変えるべきタイミングの見極めや、回収することができないコストを許容し、受け入れるという点において、アジリティは役に立つ特性です。インシデントの最中にアジリティが発揮されれば、診断の際に認識の固着を認め、そこから脱却できるかもしれません。インシデントの発生後は、アジリティのあるグローバル組織なら、現場の当事者が学んで共有した情報を聞き入れて、重要性の低いプロジェクトから引き抜いたリソースを迅速に採用できるでしょう。アジリティは、Learn & Adaptの安全性アプローチを推進するために必要な側面です(ただし、それだけでは不十分です)。
疑いよりも信頼
信頼は、学習して適応する企業文化を実現するために不可欠です。信頼は、私たちがコンテキストの助けを借りずに他者の行動を見たときの解釈に影響を与えます。信頼があれば、他者が誠実に行動していることを前提に考えることができます。インシデント発生後に、全容がわかった状態で考えると、同僚に対して思わず怒りや嫌悪感を抱いてしまうものです。信頼とは、同僚たちも大きな難題に直面したのだろうと考えて許すことです。信頼が形成されていない環境でインシデントが発生すると、恐れ、裁き、制裁、厳罰、非難など、一般的に否定をベースに物事が進められます。
方針転換を実現する
私自身の組織にこれらの新しいアプローチを導入する過程で、インシデント分析に関わることが本来やるべき業務の妨げになると、抵抗に遭うことがときどきあります。そういう人たちには、これこそが本来やるべき仕事なのだと繰り返し伝えています。エンジニアリングは知識労働であり、継続的な学習が必要です。
インシデント分析に取り組むことで学習が進んで職務遂行能力が高まるだけでなく、インシデント分析は知識創造の1つの形でもあります。組織理論家のRalph D. Stacey氏による以下の文章は、単にインシデントレポートをファイリングするだけでは新しい知識にはならない、という深い気づきにつながりました。
主流となっている観点から見れば、知識は個人の頭の中にたいてい暗黙の形で保存されているもので、個人の頭から取り出されて何らかの成果物に明確な知識として記録されたとき、初めて組織の資産になることができると考えられています。
以下のように、インシデント報告書は実際に利用されるまでは組織の知識とはなりません。
知識は対話の行為から生まれ、会話の方法が変わるにつれて関係のあり方が変化したときに、新しい知識が創出されます。この意味で、知識を保存することはできません。
よく練り上げられたインシデント報告書についてグループで集まって議論するとき、知識は創出されます。その知識が常態化された行動によって幅広く伝達され、補強されたとき、知識は創出されます。
インシデントはシステムが正常に稼働している限り必然的に起こるので、完全に防止することはできません。Learn & Adaptの安全策を推進する文化要素を備えた組織は、インシデントの望ましい面を受容できます。インシデントの結果として新しいつながりが生まれ、新鮮な視点による取り組みが可能になり、リスクが明らかになり、新しいトレーニング資料が作成されます。
インシデントが避けるべきもの、忌まわしいもの、破壊的なものであると考える組織に属しているなら、レトロスペクティブのプロセス以外にも目を向け、変革する必要があるかもしれません。小さなことから始め、Learn & Adaptを育む行動を体現し、辛抱強く待ちましょう。やがて、苗が芽吹いてきます。
筆者紹介
Alex Elmanは、Indeed のSite Reliability Engineering(SRE)チームの創立メンバーで、過去9年間にわたり、複雑さを増しつづけるシステムの拡張に対応できるよう Indeed を支援しています。Alexは、インシデントからの学習、カオスエンジニアリング、フォールトトレラント設計パターンに重点的に取り組む、Resilience Engineeringチームのチームリーダーです。
参考資料
- Allspaw, J. (2020). How learning is different than fixing. (Adaptive Capacity Labs blog.) (video). Accessed Oct. 20, 2020.
- Daniels, R. (2019). Crafting a Resilient Culture: Or, How to Survive an Accidental Mid-Day Production Incident. (InfoQ: DevOps.). Accessed Dec 28, 2020.
- Elman, A. (2019). Improving Incident Retrospectives at Indeed. (Learning from Incidents in Software blog.). Accessed Oct. 20, 2020.
- Elman, A. (2020). Are We Getting Better Yet? Progress Toward Safer Operations. In USENIX Association SREcon Conference, USA.
- Schemmel, M. (2019). Obligation vs Opportunity. (Internal Indeed Engineering blog.) Unavailable. Accessed Oct. 20, 2020.
- Spadaccini, A. (2016). Being On-Call. In Site Reliability Engineering: How Google Runs Production Systems. Sebastopol, CA, USA: O’Reilly Media, Inc. First Edition, ch. 11, pp. 125-132.
- Stacey, R. D. (2001). Mainstream Thinking about Knowledge Creation in Organizations. In Complex Responsive Processes in Organizations: Learning and knowledge creation. London, England, UK: Routledge.
- Westrum, R. (2004). A typology of organisational cultures. In Quality & Safety in Health Care, 13, ii22-ii27. 10.1136/qshc.2003.009522
- Woods, D. D. (2002). Steering the Reverberations of Technology Change on Fields of Practice: Laws that Govern Cognitive Work. In Proceedings of the Twenty-Fourth Annual Conference of the Cognitive Science Society. pp.14-16 10.4324/9781315782379-10.
- Woods, D. D. (2017). STELLA: Report from the SNAFUcatchers Workshop on Coping With Complexity. Columbus, OH: The Ohio State University.