Indeed は速さを好みます。
既に発表された研究 ( これやこれ ) のように、私たちが内部で持つ数値データも、速さの効能を立証しています。
速いサイトは、イライラも無駄な時間も少なく、求職者は目的を果たしやすくなる―これには納得がいきますよね。
けれど、アプリケーションの処理時間はこの話の一部でしかなく、多くの場合、最も重要な遅れではありません。
ブラウザからリクエストを取得し、データを再度返すこと、つまりネットワーク遅延が時間を食う最大の原因です。
ネットワーク遅延を最小限にするには?
コンテンツを圧縮し、非同期でデータを読み込めるように、エンジニアは様々なコツやライブラリを使用します。
とは言え、ある時点から物理法則が忍び寄り、単純にデータセンターとユーザーの通信をより速くする必要が出てきます。
単一のデータセンターでプロダクトを実行していて、物理的な近さが有益なこともあります。この場合、移動 (引っ越し) は選択肢にはありません。おそらく、キャッシュ化を行うか、静的資源に CDN を使用します。
物理的な所在地にそこまで縛られない場合、または Indeed のように複数のデータセンターを運用している場合、データセンターを移すことが鍵かもしれません。
だけど、どうやって選べばいいのでしょうか?
シンプルな選び方としては以下のようなものがあります。
口コミ
良い値段だし、そのデータセンターの他の顧客にも聞いたら、満足しているようだ。データセンターが提供するインターネット会社のリストも対象範囲は広いみたいだし、多分自社ユーザーにもぴったりだろう…
運が良ければの話です。
地理
東海岸には沢山アメリカ人ユーザーがいる。近くに(例えば NY 辺りに)データセンターがあれば、東海岸の作業が速くなるに違いない…
がっかりする準備はいいですか。
上記は、データセンターを選ぶ理由として、ひどいというわけではありません。
しかし、インターネット上の経路は地理に基づかず、ネットワークの相互接続部分、企業戦略、そして値段などに基づきます。
物理的に、データセンターが顧客サイトのユーザーのどんなに近くだとしても、もしユーザーの ISP が自社で所有する施設への専用ファイバーを持っていて、ニュージャージー経由でニューヨークに接続する方がその ISP にとって安いのであれば、おそらくそうするでしょう。
インターネットの「配管」は、必ずしも私たちの想像するようには接続されていないのです。
Indeed の取り組み
2012年の10月、Indeed は同じような苦境に立たされました。
米国中に点在してデータセンターを所有していましたが、西海岸の施設はほぼ一杯になっており、予想される私たちの成長スピードでは、かなり厳しい状況になるとプロバイダに警告されていました。
Ops チームは、データセンターの代替を積極的に考えていましたが、西海岸のユーザーに遅れが発生することは望ましくありませんでした。
そうして数か所のデータセンター内に、テストサーバーを設定しました。テストサーバーに、できるだけ多くの場所から ping を送り、その結果を元々のデータセンターの ping にかかる時間と比較しました。
これは、ひどいアプローチではなかったものの、速さを追求する求職者のエクスペリエンスを模倣したものではありませんでした。
その間、他の部署でもこの問題について考えていました。
そうして、エンジニアリング・マネージャーとの廊下での何気ないやりとりから、今日私たちが使用しているメソッドに雪だるま式に発展しました。
本物のユーザーリクエストを使用して、可能性のある新しいロケーションをテストすることが重要でした。
なんにせよ、ユーザがどのようにデータセンターを感じるかということについて、同じユーザを使うことに勝る手段はありません。
数度に亘る議論の末、そして、開発 (Dev) と運用 (Ops) の仕事の末、フルーツテストを私たちは生み出しました。
これは、フルーツを基にしたテストサーバーのホスト名にちなんで名付けられました。
このテクニックを使用して、提案されていた新しいデータセンターは、ほとんどの西海岸の求職者のレスポンスタイムから平均し 30ms 削れると私たちは予想しました。
全てのフットプリントを新しい施設に移行した後、私たちはこの数字が正しかったことを確認しました。
その仕組み
まず、使用できる可能性のありそうなデータセンターが、対象になるかを調査しました。
スペースやコストのせいで不適切な環境に対して、テストを実行するのは無意味です。
そのハードルをクリアした後には、軽量な Linux のシステムと Web サーバーを設定します。
この Web サーバーは、 lemon.indeed.com のように、フルーツにちなんだ名前を持つ仮想ホストを一つもっています。
その仮想ホストが 0.js、1.js、というように最大 9.js まで名付けられた 10 件の静的な JavaScript ファイルを配信できるように設定します。
サーバーが準備でき次第、 Proctor 内にテスト・マトリックスを設定します。 Proctor は自社開発したオープンソースの A/B テスト・フレームワークです。
各テストバケットに、フルーツとパーセンテージを割り当てます。それからサイトへの各リクエストは、パーセンテージに基づいてランダムにテストバケットの一つに割り当てられます。
各フルーツは、 (新規、既存のどちらにせよ) テスト中のデータセンターに対応します。
テスト・マトリックスを本番環境にパブリッシュしたら、ここからは楽しい工程が待っています!
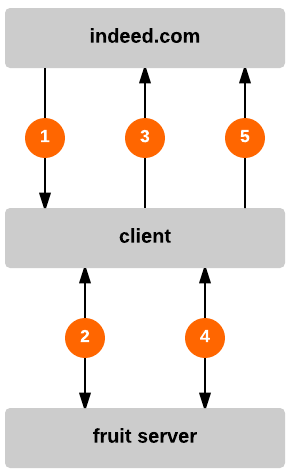
図 1:フルーツテストのリクエスト、応答、ログ
|
図例
|
テストバケット内のリクエストは JavaScriptを受信します。その JavaScript は、ブラウザに対して、タイマーを開始し、選択したフルーツのサイトから 0.js のファイルを読み込むように指示します。このファイルは空のコメントと dcDNSCallback の関数を呼び出す指示を含みます。 lemon.indeed.com では “l” を渡して、テストフルーツを示します。
/*
*/
dcDnsCallback("l");
その後、dcDnsCallback が以前のタイマーを停止し、 indeed.com にリクエストを送信します。
これは、測定したリクエストのレイテンシをログします。
dcDnsCallback の関数は2つの目的があります。
ユーザーのシステムは DNS キャッシュの中にフルーツのホスト名の IP アドレスをおそらく持たないので、 DNS 解決と、一回のリクエストの応答にどれくらいの時間がかかるのか、わかるのです。
それから、このセッション内でのそのフルーツホストへの後続のリクエストは、 DNS の解決にほとんど時間がかからないので、応答時間を計った結果がより正確になります。
dcDnsCallback の呼び出し後、テストは9個の静的な JavaScript ファイルをランダムに選び、同じ手順 (タイマーを開始、ファイルを取得、ファイル内で関数の実行) を繰り返します。これらのファイルは以下のような内容になっています。
/*
3firaei1udgihufif5ly7zbsqyz59ghisb13u1j26tkffr7h67ppywg12lfkg7ortt5t3xoq5
*/
dcPingCallback("l");
これら 9件のファイル (1.js から 9.js) は基本的に、 0.js と同じですが、 dcPingCallback の関数を代わりに呼び出し、全体の応答の長さを定義済みのサイズに調整するコメントを含みます。
1.js は最小で、たったの 26B ですが、 9.js は重く、 50KB もあります。
異なるサイズのファイルを持つ事で、レイテンシが低いけれど、利用可能な帯域幅が限定されるため、大きなファイルには不釣り合いに時間を食うデータセンターを調査しやすくなりました。
また、これは帯域幅が充分広いため、処理という観点では、処理開始時の TCP 接続の確立に一番時間がかかるようなデータセンターを識別してくれます。
dcPingCallback の関数が実行されるとすぐに、タイマーは止められ、フルーツ、 JavaScript のファイル名、読み込みにかかった時間の情報は、 Indeed に送られ、ログされます。
これらのリクエストは、表示されたブラウザのページの末尾におかれ、ユーザー・エクスペリエンスにおいて、テストの影響を最小限にするため、非同期で実行されます。
indeed.com において、ログを取るエンドポイントはこのデータを受信し、ソースの IP アドレスとユーザーが見ているサイトを記録します。
それから、 Logrepo と Indeed で呼んでいる (ええ、謎な名前ですよね) 特別な形式になったログストアに、その情報を書き込みます。Logrepo のログを集めた後、 Imhotep を使用しインデックスを作ります。これはクエリや、グラフ作成を楽にしてくれます。
テストの性質により、私たちはフルーツテストを数週間実行し、本物の求職者から何十万、果ては何百万とサンプルを集め、情報に基づいた意思決定を行えるようにします。
テストが終了したら、 Proctor のテストをオフにし、フルーツテストのサーバーをシャットダウンしてしまうだけで終わりです!他にインフラ的な変更は不要です。
このアプローチの良い点は、他のタイプのテストにも柔軟なところです。
もちろん、新規のデータセンターの所在地をテストする際に主に使用しますが、もしこのアプローチを重要な部分に煮詰めると (まさにフルーツジャムと一緒!)、テストのすることといえば、決められた量のデータのセットを、ランダムなユーザーのサンプルからダウンロードし、かかった時間を教えてくれることです。
この結果を解釈するのは、テストのデザイナー次第です。
データセンターのテストをする他にも、2つの異なるキャッシュ技術をテストしたり、異なるバージョンのウェブや、アプリのサーバーの性能の違いをテストしたり、または、 Anycast/BGP IP の地理的な分散 (過去に実施済) を調べることができます。
サンプルのサイズが、統計的に充分多様であれば、有効な比較が可能ですし、最適な人々、つまりユーザーの視点から、それを得ることが出来るのです。
いいけど、なんでフルーツテスト?
現行の、それから今後使用する可能性のあるデータセンターの所在地を表す、ユニークな名前を考えた際、私たちが考えたのは以下の様な名前でした。
- 運用 (Operations) チームが簡単に識別できること
- ユーザーには曖昧で、かつ、あまりミステリアスすぎないこと
- ビジネス上で意味をもたないこと
アルファベットの文字に対して異なるフルーツを考えるのは非常に簡単だったので、デザインをする中でプレースホルダとしてフルーツを使用しました。そして、デザインを進めていくにつれ愛着が湧き、結果採用した、というわけです。
チケットを開いて、ナツメ、マルメロ (筆者のお気に入り)、エルダーベリーのテストを有効にするのは、味のある作業です!
で、その後は?
データを山ほど集めたところで、がんがんグラフにしていきます!
そんなわけで、フルーツテストのシリーズ第二弾に続きます。
