この投稿は、2部構成となっているシリーズの第2部です。
第1部では、CFS-Cgroup の帯域幅の制御が関係したスロットリングに関する大きな問題が認識された状況について説明しました。この問題を明らかにするために、問題が発生した環境を再現し、git bisect を使用して、問題が最初に発生したバージョンを特定しました。しかし、このバージョンにはまったく問題がないように見えたので、状況はより複雑になりました。この投稿では、このスロットリングの問題に関する根本原因をどのように突き止めたのか、そしてその解決方法について説明します。

Photo by Jake Givens on Unsplash
多数のスレッドを使用した、複数の CPU のスケジュール
第1部で説明した概念モデルは正確ではありましたが、カーネルのスケジューラの複雑性を完全に表すものではありませんでした。スケジューリングプロセスにあまり詳しくない状態でカーネルについての資料を参照すると、カーネルは使用された時間の合計を追跡しているのだと思われるかもしれませんが、そうではなく、カーネルはまだ利用可能な時間の合計を追跡しているのです。その仕組みは次のとおりです。
カーネルのスケジューラは cfs_bandwidth->quota にあるグローバルなクォータバケットを使用します。スケジューラはこのクォータのスライスを、必要に応じて各コアに割り当てます (cfs_rq->runtime_remaining)。このスライスの長さはデフォルトで5ms に設定されていますが、この値は kernel.sched_cfs_bandwidth_slice_us sysctl tunable を使用して調整できます。
IO でのブロックなど、cgroup 内のすべてのスレッドが特定の CPU で実行不可能になっている場合、そのカーネルがグローバルなバケットに対して返すのは、この余剰クォータの1ms を除くすべてのクォータです。カーネルが1ms を残すのは、これにより多数の高性能なコンピューティングアプリケーションでグローバルバケットのロックの競合が低減されるためです。スケジューラは、期間の終了時に残っているコアローカルのタイムスライスを期限切れにし、グローバルなクォータバケットを補充します。
ともあれ、これがコミット 512ac999 およびカーネル v4.18 以降の状態です。
分かりやすくするために、独自のコアに固定された2つのワーカースレッドがある、マルチスレッドのデーモンの例を挙げます。上のグラフは、cgroup のグローバルなクォータを経時的に示しています。このグラフは0.2 CPU に相関した20ms のクォータで開始されています。中間のグラフは CPU のキューごとに割り当てられたクォータを示し、下のグラフはワーカーが実際にいつ CPU で実行されたのかを示します。

| 時間 | アクション |
| 10ms |
|
| 17ms |
|
この場合、ワーカー1が要求への応答に正確に5ms を使用するというのは極めて非現実的です。その要求で別の長さの処理時間が要求されていたとしたらどうなるでしょうか?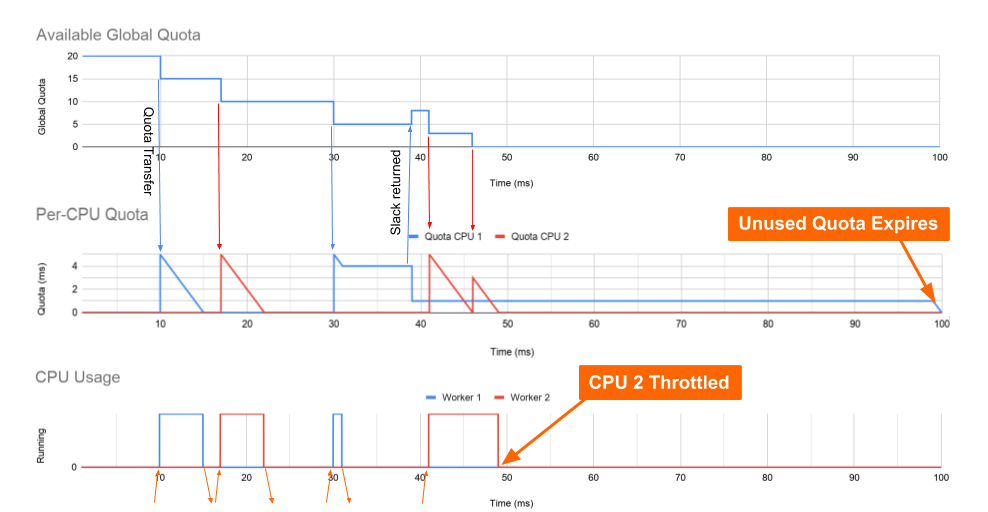
| 時間 | アクション |
| 30ms |
|
| 38ms |
|
| 41ms |
|
| 49ms |
|
2コアのマシンでは1ms の影響はそれほど大きくないかもしれませんが、コア数が多いマシンでは、こうしたミリ秒の積み重ねが大きな影響を与えます。88コア (n) のマシンでは、期間ごとに 87 (n-1) ミリ秒の遅延が発生する可能性があります。この結果、87ms (870ミリコアまたは0.87 CPU) が使用できなくなる可能性があります。このようにして、過剰なスロットリングによってクォータの使用量の低下が発生することが明らかになりました。
8コアや10コアのマシンが大型だと考えられていた当時、この問題が認識されることはほとんどありませんでしたが、コア数の多いマシンが一般的である現在では、この問題が表面化するようになったのです。そのため、同じアプリケーションであっても、コア数が多いマシンで実行した場合の方がスロットリングが増えていたのです。
注意: アプリケーションが100ms のクォータ (1 CPU) のみ保有しており、カーネルが5ms のスライスを使用した場合、クォータがなくなるまでにそのアプリケーションで使用できるコアは20のみになります (100 ms / 5 ms のスライス = 20スライス)。そのため、88という大規模なコアのうち、別の68コアでスケジュール設定されたすべてのスレッドはスロットリングの対象になり、これらのスレッドは実行されるまで、余剰の時間がグローバルバケットに返されるのを待機しなければなりません。
長い待機時間のバグを解消する
では、なぜクロックのずれによるスロットリングの問題を修正するパッチによって、別のスロットリングが発生したのでしょうか。このシリーズの第1部では、問題があるコミットとして512ac999が特定されました。このパッチを確認したところ、以下が確認されました。
- if (cfs_rq->runtime_expires != cfs_b->runtime_expires) { + if (cfs_rq->expires_seq == cfs_b->expires_seq) { /* extend local deadline, drift is bounded above by 2 ticks */ cfs_rq->runtime_expires += TICK_NSEC; } else { /* global deadline is ahead, expiration has passed */ cfs_rq->runtime_remaining = 0; }
このプレパッチコードは、各 CPU の期限切れの時間がグローバルな期限切れの時間と一致した場合 (cfs_rq->runtime_expires != cfs_b->runtime_expires) にのみ、ランタイムを期限切れにしていました。カーネルについての測定を行うことにより、私は自分が使用しているノードでは、この状態がまったくといってよいほど発生しないことに気づきました。そのため、こうした1ミリ秒が期限切れになることはなかったのです。このパッチはこのロジックを、クロック時間ベースから期間シーケンス数へと変更して、カーネルにおける長期の待ち時間というバグを解消していました。
このコードの元々の意図は、期間の終了時に残っていた CPU ローカルの時間をすべて期限切れにすることでした。コミット512ac999はこの問題を修正していたので、クォータは適切に期限切れになっていました。そのため、クォータが期間ごとに厳密に制限されることになったのです。
CFS-Cgroup の帯域幅制御が作成された当初、スーパーコンピュータでの時間共有は重要な機能の1つでした。この厳密な適用は CPU にバインドされたアプリケーションに対して効果的でした。これらのアプリケーションは、期間ごとにすべてのクォータを使用しており、期限切れになるクォータは存在しなかったからです。小さなワーカースレッドが多用される Java の Web アプリケーションでは、これは期間ごとに多数のクォータが期限切れになる (一度に1ms) ということを意味します。
解決策
状況を把握したら、次は問題を修正しなければなりません。問題へ対処するために、いくつかのアプローチが取られました。
最初に実装されたのは「時間の繰り越し」でした。これは、期限切れになったクォータを確保して、次の期間で使用できるようにするものです。この対処は、期間の境界におけるグローバルバケットのロックで thundering herd 問題が発生する原因となりました。私たちは次に、クォータの期限切れを期間ごとに個別に設定できるようにしようとしました。すると、バーストアプリケーションでクォータの消費が増える場合があるという別の問題が発生しました。スレッドが実行できなくなった場合に、余剰のクォータをすべて返すことも試しましたが、多数のロック競合やパフォーマンス上の問題となりました。CFS スケジューラの作者である Ben Segall は、コアローカルの余剰を追跡し、必要な場合にのみ再度呼び出すことを提案しましたが、この解決策には、それ自体にコア数の多いマシンにおけるパフォーマンスの問題がありました。
実は、解決策は最初から提示されていたのです。2014年以降、CFS CPU の帯域幅の制約に関する問題は誰も認識していませんでした。そして期限切れのバグがコミット512ac999で修正されると、多数の人々がスロットリングに関する問題を報告し始めました。
では、この期限切れのロジックを完全に削除すればよいのではないでしょうか。これこそが、最終的にメインラインカーネルに対して再度適用されたソリューションでした。期間ごとにクォータの時間を厳密に制限する代わりに、長期間にわたって平均的な CPU 使用量を厳密に強制することにしました。加えて、アプリケーションがバーストできる量は、CPU キューごとに1ms に制限されました。対策に関するすべての対話と、5つの後続パッチについては、Linux カーネルについてのメーリングリストのアーカイブを参照してください。
これらの変更は、現在5.4以上のメインラインカーネルに適用されており、以下のように、使用可能なカーネルの多くにバックポートされています。
- Linux-stable: 4.14.154+, 4.19.84+, 5.3.9+
- Ubuntu: 4.15.0-67+, 5.3.0-24+
- Redhat Enterprise Linux:
- RHEL 7: 3.10.0-1062.8.1.el7+
- RHEL 8: 4.18.0-147.2.1.el8_1+
- CoreOS: v4.19.84+
結果
この最適なシナリオでは、今回の修正により Indeed アプリケーションの各インスタンスで使用可能な CPU を0.87増やすか、必要な CPU クォータで同じ量を減らすことができます。こうした利点により、アプリケーション密度の増加の制約が解消され、クラスタ全体におけるアプリケーションの応答時間が短縮されます。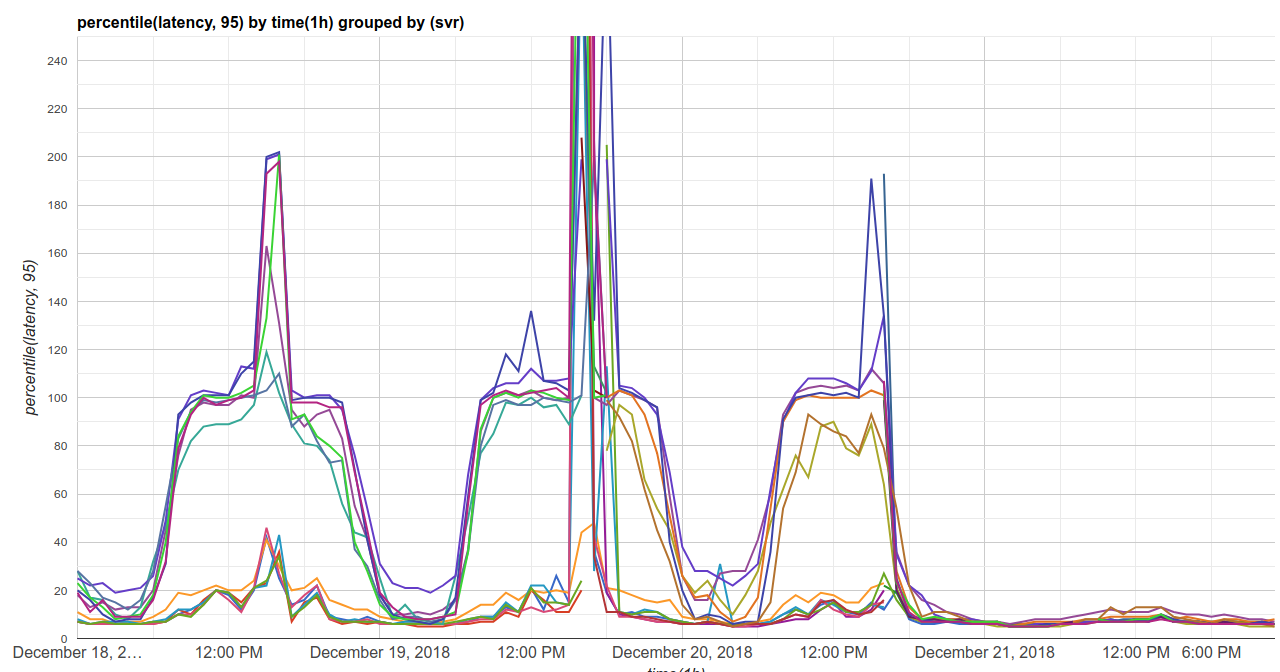
問題の緩和方法
以下は、ご使用のシステムにおいて、CFS-Cgroup 帯域幅の制御によりスロットリングに関する問題が発生するのを防ぐための対策です
- throttled percentage を確認する
- カーネルをアップグレードする
- Kubernetes を使用している場合は CPU クォータをすべて使用して、cgroup でスケジュール設定可能な CPU の数を減らすようにする
- 必要に応じてクォータを増やす
現在進行中のスケジューラの開発
Yandex の Konstantin Khlebnikov は、Linux カーネルのメーリングリストで「バーストバンク」を作成するためのパッチを提案しています。これらの変更は、この投稿で説明したとおり期限切れのロジックが削除されたことから現在は実現可能になっています。バーストに関するこれらのパッチは、より多数のアプリケーションのセットに小さなクォータの制限を設定することができるようにします。このアイデアに興味を持った方は、Linux カーネルのメーリングリストに参加し、サポートをお願いします。
Kubernetes でのカーネルのスケジューラのバグについてさらに詳しく把握するには、GitHub での以下の注目すべき問題をご覧ください。
- CFS クォータが不要なスロットリングの原因になる可能性がある (GH #67577)
- Kubernetes 内から CFS 期間を設定する (GH #51135)
- CPU の設定によって CFS クォータの設定を解除する (GH #70585) (GH #75682)
ご不明な点は、お気軽に @dchiluk 宛てにツイートしてください。