私は大学で初めて受けた機械学習の授業で、レコメンダシステムを構築しました。ソーシャルミュージックサイトのデータセットを使って、ユーザーがアーティストを気に入るかどうか予測するモデルを作成したのです。最初の実験では、データセットの99%に対して正しいレーティングを与えたので、私は高揚しました。間違いはたった1%だったのです。
自信満々で教授に結果を報告しましたが、そこで自分が機械学習の天才ではないことを思い知らされたのです。私が犯した失敗は、「base rate fallacy (基準率の無視)」と呼ばれるものでした。私が使用したデータセットは、極端なクラス不均衡を示していました。言い換えると、ユーザーとアーティストの組み合わせのうちの99%が、ユーザーが好んでいないアーティストだったのです。世界中には無数のミュージシャンがいて、おそらく誰も、その半数も知らないでしょう。そもそも気に入るかどうか以前の問題です。

注意していないと、クラス不均衡は、ミスリーディングな評価指標につながる問題を引き起こします。大学生だった私は、真正面からこの問題にぶち当たりました。正解率だけでは、何も知ることができないのも同然です。ある自明な予測モデルが「すべてのユーザーはどのアーティストも気に入らない」という予測をした場合、正解率は99%に達するかもしれませんが、そこには何の価値もありません。正解率を指標にした場合、すべてのエラーは同程度のコストを伴うという前提になりますが、実際はそうでないことが多いのです。
医療を例に挙げて考えてみましょう。腫瘍を見て、誤って悪性だと診断し、さらに精密なスクリーニングを行った場合、この誤診の代償は、患者の不安と医療従事者の時間です。反対に、良性だと診断した腫瘍が実際は悪性だった場合、患者は命を失ってしまうかもしれません。
クラスの分布を検証する
不均衡の問題に関して、正解率以上に考えるべき指標は数多くあります。まずは、クラスの分布を知ることが最初の関門です。プラーティ、バティスタ、シルバの3人は、経験則からあることに気づきました。それは、データセットに占める少数派クラスの割合が10%以上の場合、クラス不均衡がパフォーマンスを著しく損なうわけではないということです。データセットにこれ以上の不均衡がある場合は、特別な注意を払う必要があります。
まずは、きわめて単純なモデルから始めることをお勧めします。最も頻度の高いクラスを選びましょう。scikit-learn が DummyClassifier で実装しています。私が音楽のレコメンダプロジェクトを作成した時にこれを行っていれば、自分のモデルが実際には何も学んでいないことにすぐ気づいたでしょう。
コストを評価する
検出漏れや誤検出の正確なコストを計算できれば理想的です。モデルを評価する際、これらのコストに検出漏れと誤検出の割合を掛け合わせれば、モデルの誤分類コストを表す数値が得られるはずです。あいにく、これらのコストは現実世界では未知であることが多いです。誤検出の割合を改善すれば、たいてい真陽性率に害を及ぼします。
このトレードオフは、ROC 曲線を使って可視化できます。たいていの分類器は、各クラスに対する確率を出力することが可能です。閾値 (例: 50%) を一つ固定すれば、閾値を超える確率を持つデータ点が、すべて正のクラスに属すると考えることができます。確率の低いものから高いものまで閾値を変化させると、異なる真陽性率と誤検出率を持つ分類基準が得られるでしょう。誤検出率を X 軸とし、真陽性率を Y 軸として、ROC 曲線が求められます。
たとえば、私は KEEL の yeast3 データセットで分類器をトレーニングし、ROC 曲線を作成しました。
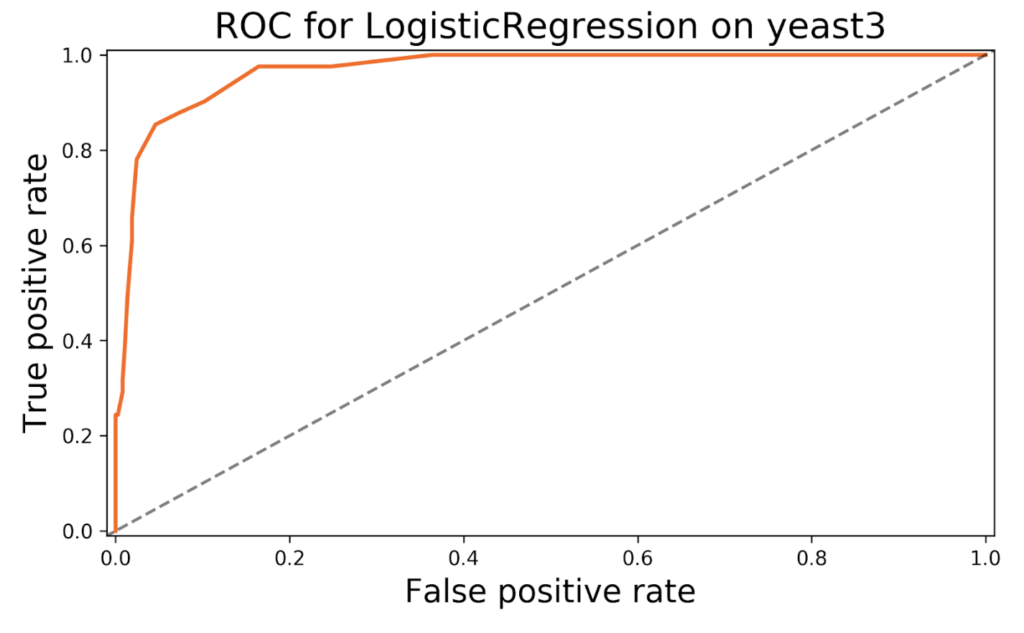
ROC 曲線を描くためのコードを自分で記述することも可能ですが、Yellowbrick ライブラリにはこの機能が組み込まれています (さらに、scikit-learn モデルとも互換性があります)。これらの曲線は、モデルの閾値をどこに設定すべきかの参考になるでしょう。さらに、この曲線より下の部分の面積を使って、複数のモデルを比較することもできます (良い指標とはならない場合もありますが)。
次に機械学習の問題に取り組む時は、目的変数の分布について考えてみてください。クラス不均衡の問題を解決する最初の大きな一歩は、問題を認識することです。より適切な指標を用い、可視化することで、不均衡の問題について、より明確な議論ができるようになります。
クラス不均衡についての詳細
ODSC West では、クラス不均衡が生じる原因について、より深く掘り下げてお話するつもりです。このエラーに対処する方法についても、色々と探ってみたいと思います。それでは10月にお会いしましょう!