以前の記事で、 Statusのライブラリを使用した、アプリケーションの堅牢なヘルスチェックを行う方法を説明しました。本記事では、
- アプリケーションから主要でない機能を削除
- データセンターのロードバランサから一件のアプリケーションのインスタンスを削除
- DNSレベルでローテーションから全データセンターを削除
と言った作業を行ったことで停止(outage)した際に、アプリケーションを確認しデグレデーションを行う方法を書いていきたいと思います。
アプリケーションの動作状態の確認
Status ライブラリを使用すると、単一の依存性チェックと、システム全体の評価という、二種類のチェックをシステムに対して行うことが可能です。依存性というのは、システムが機能するために必要なシステムやサービスを指します。
単一の依存性チェックの間、DependencyManager は、依存性のIDを取得し、CheckResultに返す評価方法を使用します。
CheckResultは以下を含みます。
- 依存関係の状態
- 依存関係に関する一部の基本的な情報
- 依存関係の状態を評価するのにかかった時間
CheckResultはJavaのenum(列挙型)で、OK, MINOR, MAJOR, OUTAGE などの一つです。OUTAGE のステータスは依存関係が使用できないことを示します。
final CheckResult checkResult = dependencyManager.evaluate("dependencyId");
final CheckStatus status = checkResult.getStatus();
アプリケーションの状態を評価する二つ目のアプローチには、システム全体を見るやり方があります。これは、高いレベルで全体のシステムがどう処理しているかという全体図を見せてくれます。一つのシステムが OUTAGE の状態にある場合、これはあるアプリケーションのインスタンスが使用不可能であることを示します。
final CheckResultSet checkResultSet = dependencyManager.evaluate(); final CheckStatus systemStatus = checkResultSet.getSystemStatus();
システムが正常でない場合には、システムに送ったリクエストを短絡させ、HTTP ステータスコード500 (“Internal Server Error”) を返すのが、多くの場合、最良とされます。下記の例では、Springでインターセプターを使用し、リクエストをキャプチャし、システムの状態を評価し、アプリケーションが停止している場合にはエラーの応答をします。
public class SystemHealthInterceptor extends HandlerInterceptorAdapter {
private final DependencyManager dependencyManager;
@Override
public boolean preHandle(
final HttpServletRequest request,
final HttpServletResponse response,
final Object handler
) throws Exception {
final CheckResultSet checkResultSet = dependencyManager.evaluate();
final CheckStatus systemStatus = checkResultSet.getSystemStatus();
switch (systemStatus) {
case OUTAGE:
response.setStatus(HttpStatus.INTERNAL_SERVER_ERROR.value());
return false;
default:
break;
}
return true;
}
}
依存関係の状態を比較
CheckResultSet と CheckResult は、それぞれ現在のシステムの動作状態や、依存関係の状態を返す方法を持っています。CheckStatus を手に入れさえすれば、結果の比較ができる方法もいくつか出てきます。
isBetterThan() は、現在の状態が与えられた状態よりも良いかどうか判断します。これは他を含まない排他的な比較です。
CheckStatus.OK.isBetterThan(CheckStatus.OK) // evaluates to false CheckStatus.OK.isBetterThan(/* any other CheckStatus */) // evaluates to true
isWorseThan() は、現在の状態が与えられた状態よりも悪いかどうか判断します。この操作も、他を含まない排他的な比較になります。
CheckStatus.OUTAGE.isWorseThan(CheckStatus.OUTAGE) // evaluates to false CheckStatus.OUTAGE.isWorseThan(/* any other CheckStatus */) // evaluates to true
isBetterThan() と isWorseThan() の方法は、評価した依存関係が望ましい状態にあるかを確認できる、優れたツールです。しかし、残念ながらこれらの方法はグレイスフルデグレデーションを行うには、十分なコントロールが利きません。システムは、正常か、停止してしまっているか、のどちらかしかないのです。システムのグレイスフルデグレデーションを、さらにコントロールするために、新たに別の二つの方法が必要となりました。
noBetterThan() は、二つの状態のうち、正常でない方を返します。
CheckStatus.MINOR.noBetterThan(CheckStatus.MAJOR) // returns CheckStatus.MAJOR CheckStatus.MINOR.noBetterThan(CheckStatus.OK) // returns CheckStatus.MINOR
noWorseThan() は二つの状態のうち、正常な方を返します。
CheckStatus.MINOR.noWorseThan(CheckStatus.MAJOR) // returns CheckStatus.MINOR CheckStatus.MINOR.noWorseThan(CheckStatus.OK) // returns CheckStatus.OK
完全にシステム評価をする間、私たちはこれらの方法の組み合わせと、Urgency#downgradeWith() という方法を使用して、アプリケーションの動作状態のグレイスフルデグレデーションを行います。
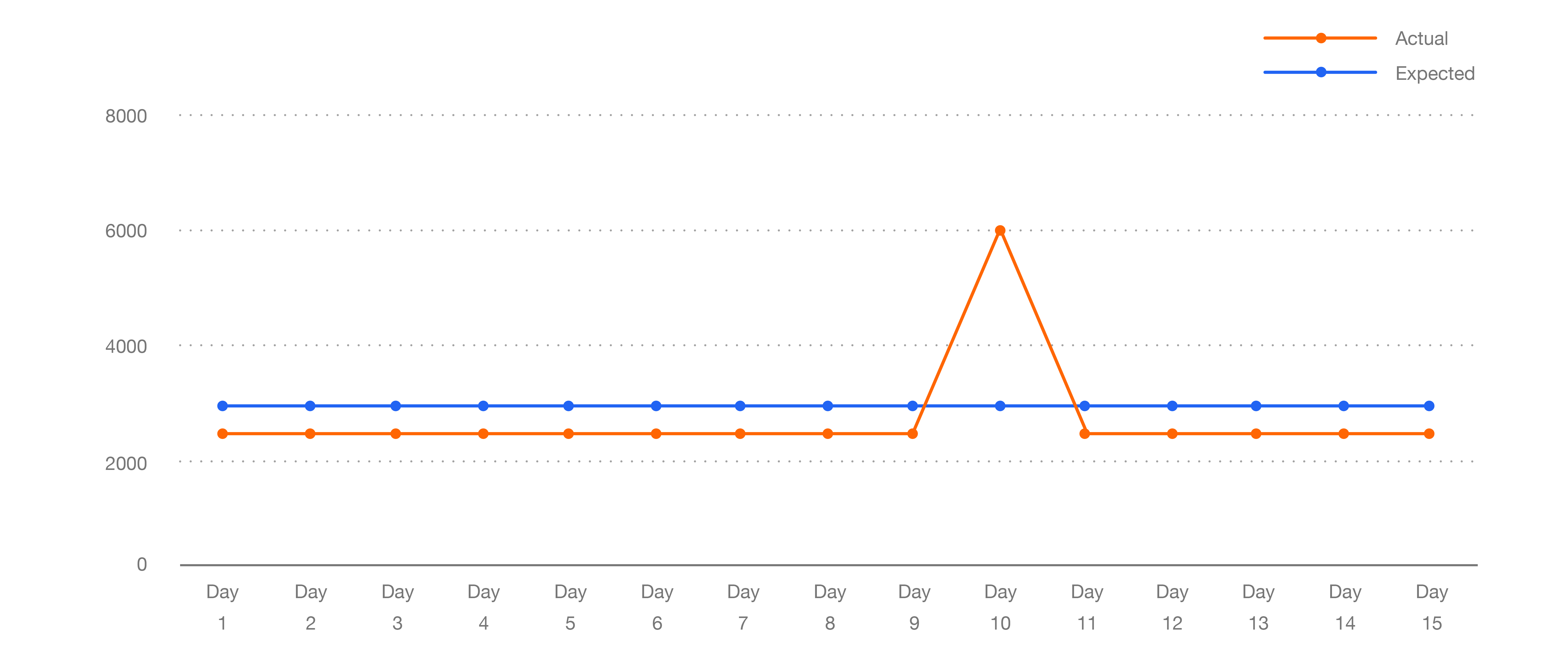
停止した状態を調査できる機能を持つことで、依存関係の状態に基づいて、エンジニアは機能を表示するかどうかを動的に切り替えることが可能です。仮に、企業情報を提供する私たちのサービスがデータベースに到達できなかったとします。このサービスのヘルスチェックの状態はMAJOR か OUTAGE に変更します。私たちの求人検索のプロダクトは検索結果ページの右列にある、企業ページのウィジェットを外します。求職者と企業を結ぶ、核の部分となる機能には影響しません。
|
正常
|
正常でない(グレイスフルデグレデーション後)
|
サービスの動作状態に基づいて機能をコントロールできることだけがStatusの全てではありません。私たちは、フロントエンドのWebアプリケーションのインスタンスへのアクセスをコントロールするのにもStatusを使用しています。インスタンスがリクエストを処理できない場合、再び正常化するまで、ロードバランサからインスタンスを削除します。
インスタンスレベルでのフェイルオーバー
一般的に、本番環境にあるアプリケーションの複数のインスタンスを実行するのが広く推奨されています。これは、万一アプリケーション内の一件のインスタンスが停止した場合にも、リクエストを処理し続けるのを可能にすることで、システムを障害から復旧しやすくします。アプリケーションのこれらインスタンスは一つのマシン内にも、複数のマシンにも、そして複数のデータセンターにも、存在することが可能です。
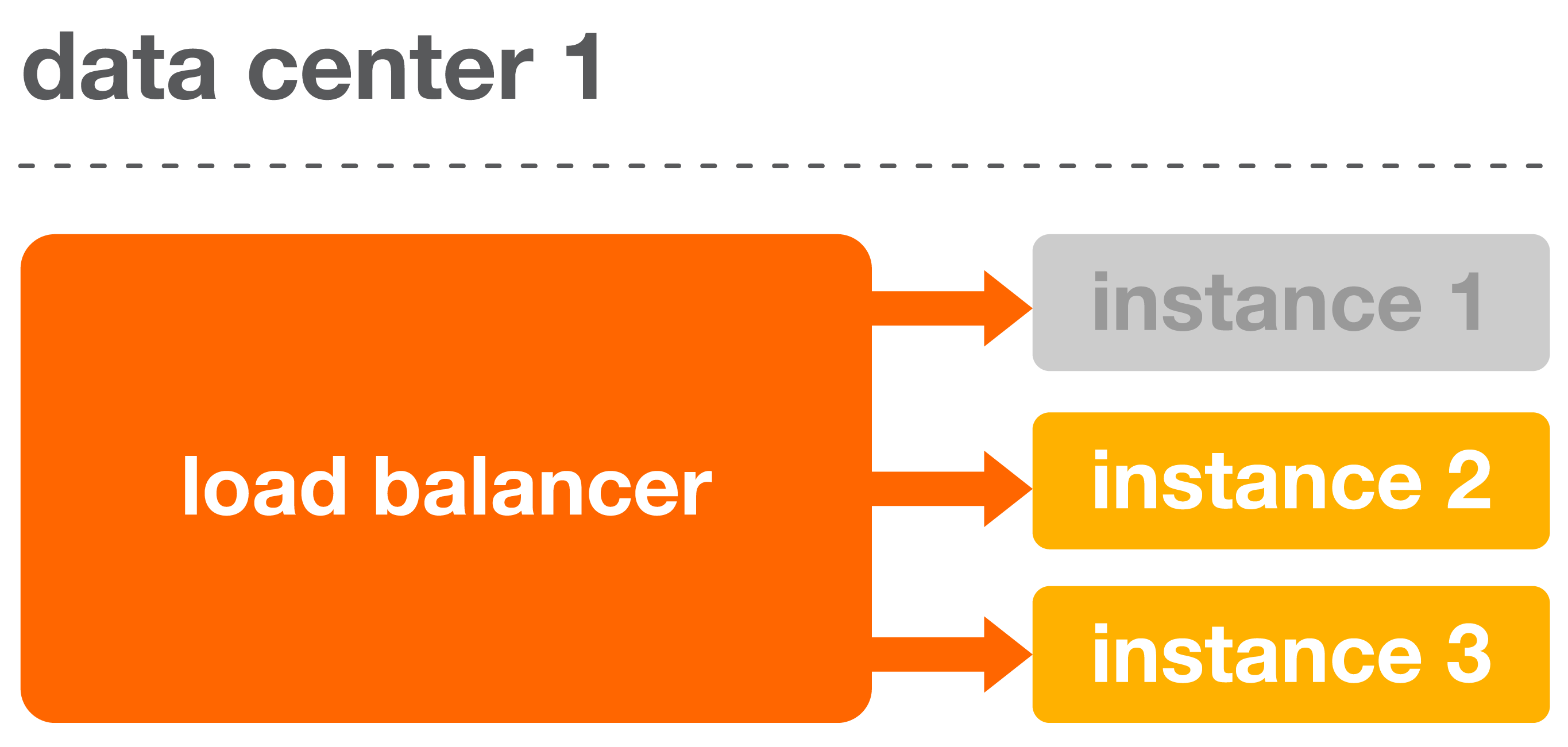
Status ライブラリは、インスタンスが正常でなくなった際に、それを削除するようにロードバランサを設定することができます。下記の、一つのデータセンター内を表した基本例をご覧下さい。
 |
一つのデータセンター内のアプリケーションが全て正常に動作している場合、ロードバランサは、リクエストを均等に分散する。アプリケーションが正常な状態かどうかを判断するために、ロードバランサはリクエストをヘルスチェックのエンドポイントに送り、応答するコードを評価する。 |
| インスタンスが正常でなくなった際には、 ヘルスチェックのエンドポイントは200番台以外のHTTPステータスコードを返し、トラフィックに応答しないように指示する。その後ロードバランサは正常でないインスタンスをローテーションから削除し、リクエストの受信を防ぐ。 |
 |
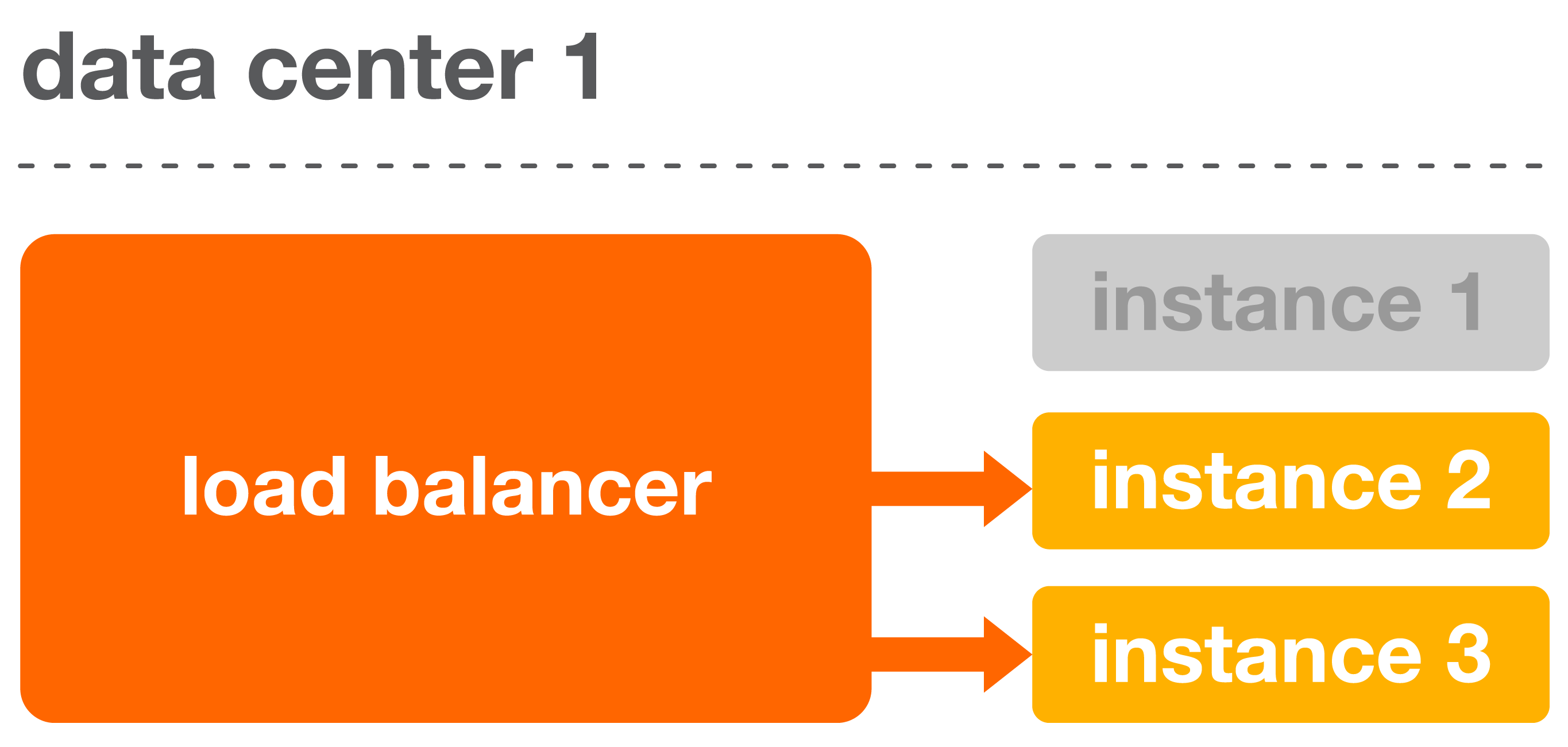 |
インスタンス1がローテーションから削除され、データセンター内の他のインスタンスがインスタンス1のトラフィックに応答を開始する。各データセンター内では、複数のインスタスが停止した場合にも、トラフィックを処理できるように十分なインスタンスを設定している。 |
データセンターレベルでのフェイルオーバー
リクエストがデータセンターにすら送信される前、私たちのドメイン(例:www.indeed.com )はDNSを使用し、IPアドレスを解決します。私たちは、データセンター間で、トラフィックを地理的に分散する、グローバルサーバー・ロードバランサ(GSLB)を使用しています。GSLBがドメインを最も近くで利用可能なデータセンターのIPアドレスに解決し、その後、データセンターのロードバランサは上記で説明したように、トラフィックを転送し、フェイルオーバーさせます。
あるデータセンター全体がリクエストを処理できなくなったら、どうすればいいでしょうか?一件のインスタンスの場合のアプローチと同様に、GSLBは常に各データセンターの状態を(同じヘルスチェックエンドポイントを使用し)確認しています。GSLBが一つのデータセンターがリクエストを処理してないことを検知した場合、別のデータセンターにリクエストをフェイルオーバーさせ、ローテーションから正常でないデータセンターを削除します。繰り返しますが、こうして、停止状態の間ですら、リクエストの処理を確かにすることで、サイトを利用可能の状態に維持できるのです。

一つのデータセンターが正常でいてくれる限り、サイトはリクエストを処理し続けることが出来ます。正常でなくなったデータセンターに当たるユーザーには、この状態は、単にページの読み込みが遅くなったようにしか見えません。理想的でありませんが、処理されないリクエストにくらべれば、遅くてもエクスペリエンスを提供できる方がましでしょう。
最後の想定シナリオは、完全にシステムが停止した場合です。これは全データセンターが正常でなくなり、リクエストを処理できなくなった場合です。エンジニアというのは、こうした最悪の状況は回避しようとします。
Indeedが、完全なシステム停止に陥った場合には、私たちは各データセンターと各インスタンスにトラフィックを転送します。このポリシーは、オープンフェイルとして知られ、システムのグレイスフルデグレデーションを可能にします。各インスタンスは正常でない状態を通知してくるかもしれませんが、アプリケーションが何らかの形で作動する可能性があります。私たちは、どうにか何かが動いてくれる方が、全く動かなくなるよりも、ましだと考えるからです。
Indeedにもあなたにも役立つStatus
Statusライブラリは、Indeedで開発し、実行するシステムにとって、不可欠な部分です。私たちは以下の事にStatusを使用しています。
- 迅速なアプリケーション・インスタンスとデータセンターのフェイルオーバー
- コードが、トラフィックの大きなデータセンターに到達する前にデプロイの失敗を検知
- 失敗するとわかっている作業をするのではなく、リクエストを素早くfailさせることで、アプリケーションの速さを維持
- アプリケーションのサービスリクエストが、正常なインスタンスだけになっていることを確認し、サイトが利用可能であるように維持
Statusを始めるには、こちらのクイックスタートガイドを読み、サンプルを見てみてください。ご質問、ご不明な点は、Indeedの GitHub か Twitter までご連絡ください。