ホリスティックなユーザーエクスペリエンス (UX, User Experience) への再設計のための A/B テストには、困難が伴います。Indeed で UX を次のように変更しようとした時、 学んだことがあります。
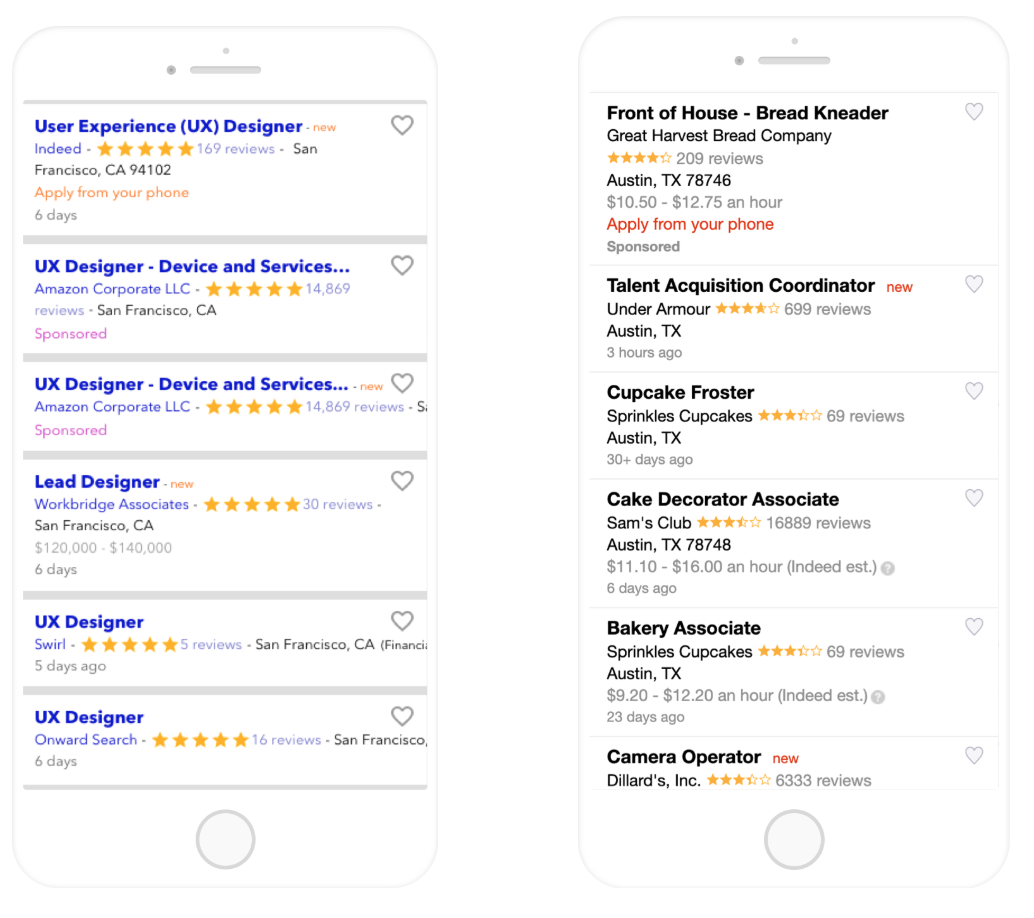
Indeed のモバイル版の検索結果ページ (SERP) 2017年中頃 (左)、2018年中頃 (右)
道のりは平坦ではありませんでした。見栄えの良いデザインの構想に数ヶ月費やし、さらに数ヶ月費やして、すべての変更を同時にテストしました。たくさんの指標が変動 (ほとんどが下降) し、どの UI の変更がどのような効果をもたらしたのかを把握できず、大混乱でした。
そこで、手法を変更することにしました。2018年の中頃、「できるだけ多くの UI 要素を科学的にテストし、Indeed の求人検索エクスペリエンスの原則を解明する」という目標を掲げ、複数のチームからメンバーを集め、Job Search UI (JSUI) Lab を立ち上げました。過去12か月間だけでも、52回以上のテストを行い、テストしたグループの数は502を数えました。以来、得られた知見を活かして、デスクトップとモバイルの両方のブラウザで求人検索 UX の改良を重ねています。
この記事で、2018 Indeed Engineering Innovation Award (社内の革新的なプロジェクトに授与される賞) を2018年に受賞した、JSUI Lab の、A/B テストをスピードアップする方法をいくつかご紹介します。UX の改善に関心がある方や、新しい機能を試したいという方は、これからご紹介する方法を A/B テストに取り入れてみてください。
#1: 十分なバックログを用意する
次のテストが決まらず、時間を無駄にしてしまうのは好ましいことではありません。開発者にとって、優先度の高い A/B テストのバックログが健全な量であれば、A/B テストはスムーズに進められます。
JSUI Lab では、四半期の最初の月に、チームのメンバー全員を集めてテストについてのブレインストーミングを行いながらバックログを作成します。現在のモバイル版とデスクトップ版の UX をピックアップし、各要素がどのように機能するか検証するのです。出て来た疑問やアイデアを、付箋に書き留めていきます。最終的に40個以上のアイデアが生まれ、求職者の問題点を解決できそうか、最小限の労力で設計システムを改善できるか、といった観点からテストの優先順位をつけました。バックログのテストをすべて実行することはできないかもしれませんが、少なくともやるべきテストが見つからない、という心配はなくなります。
#2: あらかじめ仮説を明記しておく
製品の開発に追われていると、A/B テストに対して自らが立てた仮説を事前に記載しておく時間が取れないことがあります。もちろん、仮説を書く作業を省くことで、テストの前に10~30分位は時間を節約できるかもしれませんが、数十件もの指標を検討し、次に何をすべきか決定する時、つまりテストが終了した時に痛い目を見ることになるでしょう。
ある指標は上昇し、別の指標は下降することで混乱が生じるだけではありません。たくさんの指標を考えれば考えるほど、おそらく誤検出 (第一種の過誤) も出てくることでしょう。「この UI 要素をオレンジから黄色に変えたら、求職者が採用担当者から連絡をもらえる確率にどう影響するだろうか」といった、テストの影響を受けない指標を考えてしまっている自分に気づくかもしれません。
こうならないためには、テストを行うことで変化が見られると思われる指標を3〜4個選び、各指標の検出力分析を行い、テストの仮説を記載しておきましょう。
#3: UI 要素を一つずつテストする
これには賛成できない、とおっしゃる方もいるでしょう。UI 要素を一つずつテストしたら、ホリスティックな UX への再設計に時間がかかり過ぎてしまうと思うかもしれません。しかし、UI 要素を一つずつテストしていくことで、実際には、より妥当な結論を導けました。それはなぜでしょうか? より明確に、因果関係を立証できたからです。
その結果、テストから得たすべての知見を、パフォーマンスアップにつながると確信できる一つの大きなテストに活かすことができました。ホリスティックな UX への再設計のためのテストを最初に行った時のように、指標が多過ぎて手に負えなくなるということはなく、2018年に Indeed が獲得した最も多くのユーザーエンゲージメントの一つとなったのです。かかった時間は、最初にテストした時の半分以下でした。
UI 要素を一つずつテストすることで、データに基づいて設計ビジョンを再現でき、ホリスティックな UX のためのテストを成功させることができました。
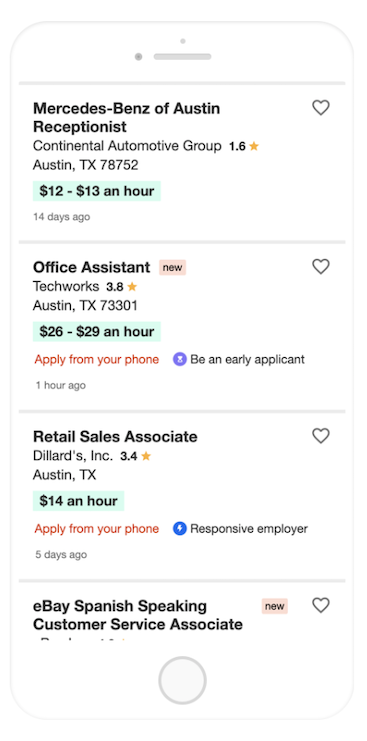
2019年中頃のモバイル版の Indeed の検索結果
では、これらのテストは、実際にはどのように行われていたのでしょうか。以下は、テストグループの例です。違いは、フォントサイズやスペースなど、わずかなものであることがわかると思います。

#4: 多変量テストを考慮する
多変量テスト (または「要因テスト」) では、A/B テストの各要因について、考えられるすべての組み合わせをテストするので、A/B/C/D/E/… テストのようになります。各要因を一つずつテストしていたら見逃してしまっていたかもしれない組み合わせを見つけられるのが、多変量テストの利点です。
この利点は、JSUI Lab の例からもわかります。UX のリサーチを通じて、求職者が求人の詳細を見るときに、本当に知りたいのは給与であることがわかりました。そこで、2018年に、検索結果に給与を次のように表示しました。
色、フォントサイズ、太字によって視覚的に目立たせることで、検索結果に対する求職者のエンゲージメントが上昇するかどうかを確かめたかったのです。4種類のフォントサイズ、4種類のカラーバリエーション、太字かそうでないかの2種類を用意しました。4 x 4 x 2で合計32グループです。
多変量テストにより、UI 要素ごとに結論を出すスピードを速めることはできますが、欠点がないわけではありません。最初に、統計的検出力のトレードオフ、あるいは特定の効果が存在する場合にそれを検出する可能性 (第二種の過誤) を考慮する必要があります。統計的検出力が不十分だと、テストの効果があったとしても、それを検出できないというリスクが生じるのです。
検出力の計算は閉形式であり、プロダクトチームは、α レベルと β レベルの選択、サンプルサイズ (n)、処理による効果量 (p1) のうち、どれを優先するか決めなければなりません。Indeed では、2億2千万人以上の月間ユニークユーザー数が強みです。あなたのチームのトラフィックはこれより少ないかもしれません。そのため、確実に検出したい効果の大きさによっては、十分な統計的検出力を得るためにテスト期間を長めに設定したり、グループへの割り当てを増やしたり、一部のグループは除外したり、第一種の過誤の増加を考慮しなければならないかもしれません。
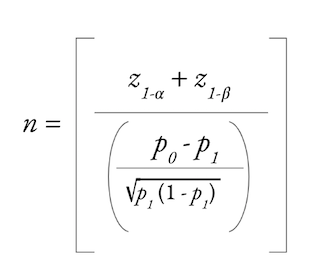
2つの比率の検出力テストである閉形式の計算
典型的な A/B テストの場合、通常は t 検定による比較的単純な分析です。多変量テストでは、多変量回帰モデルを使用して、特定の変数の効果とその交互作用を調べることができるでしょう。単純化した回帰方程式がこちらです。
![]()
さらに、私たちが行ったテストのうち一つの回帰方程式の例はこちらです (求人カードのフォントサイズとスペースを修正したもの)。

多変量テストに関するもう一つの注意事項は、すぐに実行不可能になる場合があるという点です。2つのレベルを持つ10個の要因がある場合、2の10乗の多変量テストを行うことになり、テストグループは1,024個にもなります。このような場合、一部実施要因テストの実施の方が、意味があるかもしれません。
多変量テストでは、おもしろい組み合わせが表れることがあります。前述の給与の例で、給与のパターンを16ポイント、緑、太字のフォントにしたとき、Indeed の UX Design チームはあまりいい顔をしませんでした。私たちは、このパターンを「ハルク」という愛称で呼びました。アクセシビリティを考慮して、パターンを実行できないことがあるかもしれません。JSUI Lab では、統計的厳密さと引き換えにユーザーエクスペリエンスが一時的に低下しても良しとするか、ケースバイケースで判断しています。
#5: CSS および JavaScript の変更を別々にデプロイする
従来のデプロイサイクルでは、新しい機能をすばやくテストするには不都合なこともあります。Indeed では CrashTest というツールを開発し、デプロイサイクルを回避できるようにしました。CrashTest は、メインコードベースの「フック」に投入される CSS や JavaScript ファイルのコードベースに依存しています。CrashTest のフックのインストールは標準的なデプロイの通りですが、フックが設定されると、新しい CSS や JavaScript の処理を投入でき、数分後には変更によるプロダクトへの影響を確認できます。
JSUI Lab では、Design Technologist のクリスティーナが、数十個のグループ用の CSS や JavaScript の処理を担当しています。CrashTest があれば、クリスティーナは機能を作成し、QA はコーリーに頼めます。Indeed の オープンソーステスト管理プラットフォーム、Proctor を使えば、その日のうちにテストを開始させることができます。従来のデプロイサイクルで動いていれば、クリスティーナの作業の成果が求職者の目に触れるまでにもう数日を要し、A/B テストの結果が出るまでさらに長い時間がかかったでしょう。
#6: 民主的な A/B テストプラットフォームを持つ
テストの成果を把握するために、ログとテーブルを隅々までチェックするのは、賢い時間の使い方とは言えません。それより、チームで使える A/B テストプラットフォームを構築するか、購入することを検討しましょう。データを重視する Indeed には、TestStats という社内ツールがあります。このツールは、各テストグループが主要な指標に対してどのような効果があったか、テストが既定の効果量から有意義な結論を導き出せるだけの統計検出力を備えているかを教えてくれます。テスト結果を他の人と共有したり、議論したりするのに便利なツールです。
#7: クロストレーニングで全員のスキルをレベルアップする
JSUI Lab は、全員が平等にチームの決定に貢献することで、チームがより上手く機能すると確信しています。チームメートは、Product Manager、UX Designer、QA Engineer、Data Scientist、Program Manager、Design Technologist です。各自がユニークなバックグラウンドを持ち、それをチームに還元しています。日常業務の中で自分のスキルをお互いに教え合うことで、共通する言葉で会話ができるようになるため、A/B テストがスピードアップします。
たとえば、私は Product Scientist で、A/B テストのトレーニングを行いました。結果として、毎回私が直接指示しなくても、 JSUI Lab の全員がテストの設計を判断できるようになってきています。UX Designer のケイティは、Product Manager の CJ やケヴィンがテストを行う際の手順をそばで見ながら覚えました。今では、ケイティは自分でテストを行っています。このようなクロストレーニングは、チームにおける「バス因子」を減らすだけでなく、チームメートが自分の専門分野をマスターし、知識への自信を深める方法として非常に優れているのです。
さあ、テストを始めましょう!
紹介した7つのヒントのうちのどれか一つ、あるいは全部を取り入れれば、A/B テストのスピードがアップするでしょう。JSUI Lab は、こうした簡単な手順を社内の他のチームにシェアし始めています。皆さんの会社でも幅広く応用できると思います。ぜひお試しください。
A/B テストの方法論に関して熱意をお持ちの方は、Indeed で一緒に働きませんか?