[Editor’s note: This post is the second installment of a two-part piece accompanying our first @IndeedEng talk. Slides and video are available.]
The number of job searches on Indeed grew at an extremely rapid rate during our first 6 years. We made multiple improvements to our document serving architecture to keep pace with that growing load.
A core focus at Indeed is to keep jobs as “fresh” as possible. We measure job freshness as the time from when our systems find a job posting on the web to when that data is searchable on our site. Providing comprehensive job data in as close to real-time as possible is one way we create the best job search experience for our users. In 6 years, the amount of data that we needed to process to reach that goal had drastically changed.
By late 2011, we were aggregating 41 million new jobs from around the world each month. We were serving up to 850 million job documents each day, at a peak rate of 14,000 documents/second. Our document serving system consisted of a replicated, file system-based document store (“docstore”), accessed via a remote Boxcar service (“docservice”). This system worked well for over two years but was straining under the continued growth. Updating the docstore with fresh job data took about 12 hours of every day. Delays or interruptions in replication made it difficult to catch up with the stream of job updates. To continue to provide the most recent jobs to jobseekers, we needed to make it faster.
In our first docstore implementation, we wrote raw job data to disk in segment files, each containing the data for some set of jobs. We wrote these files in job ID order to easily be able to find data for a single job based on its ID. When a job was updated, we wrote the new version back into the same segment file.
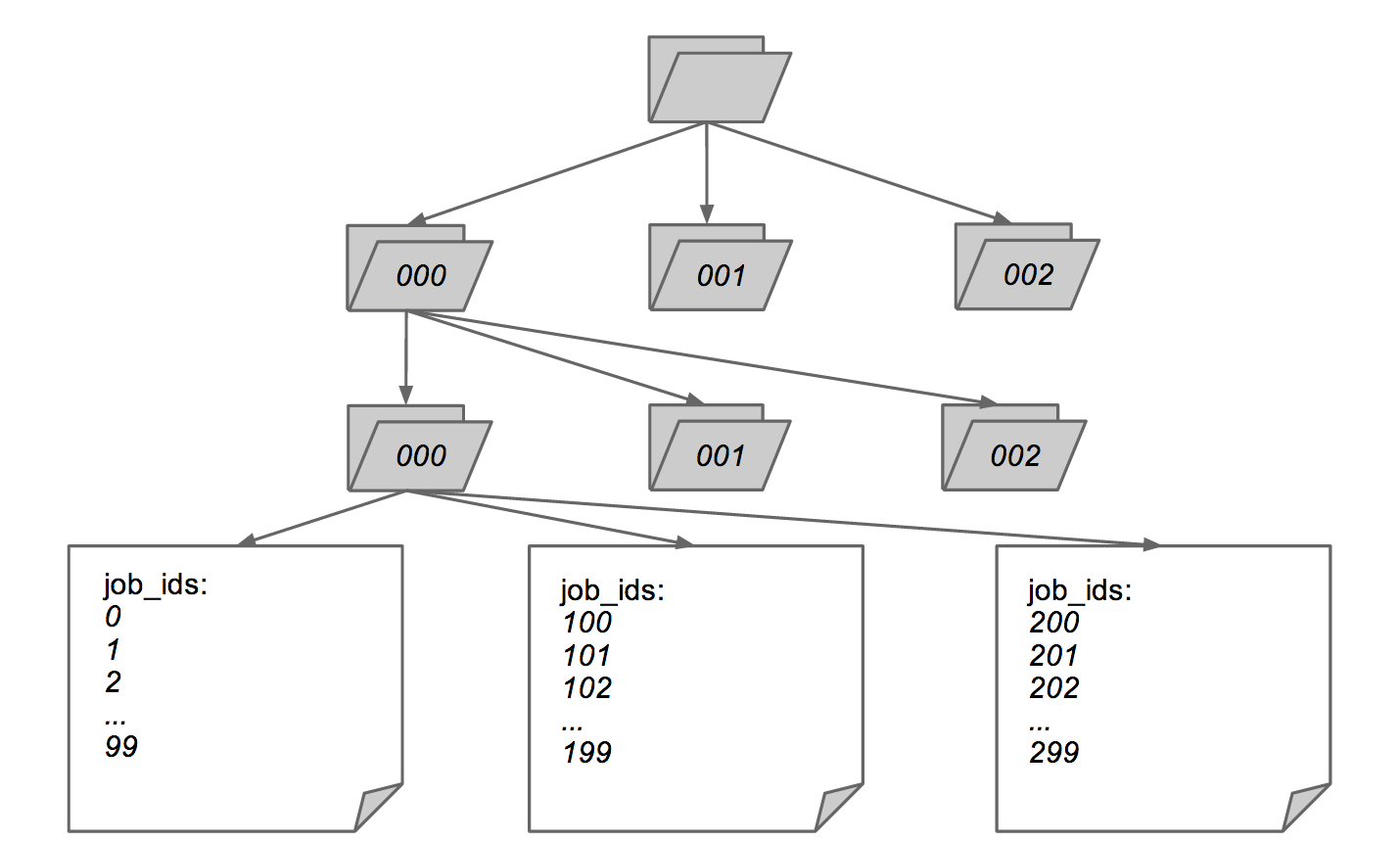
Figure 1: docstore v1 segment file organization
Indeed sites serve thousands of searches per second for jobseekers from many countries. The selection of jobs returned by those searches is uncorrelated to the job ID. From the perspective of the docstore, they are effectively random accesses. Even for a single search, the results are hardly ever ordered by job ID and are not even likely to have jobs with close IDs. Similarly, writes to the docstore do not happen in strict job ID order, because updates to existing jobs are mixed in with additions of new jobs. The job ID order structure of the docstore led to essentially random disk writes and reads.
Scaling random reads is a well-understood problem. To keep reads fast under load, you can add servers and/or do more aggressive caching. Scaling writes is a much more challenging problem, but one that we had to solve in order to achieve better performance than docstore v1.
Consider the physical capabilities of a single magnetic hard disk. A basic commodity disk spinning at 7200 rpm has an average 30MB/second sequential write throughput. An lzo-compressed job entry contains about 1KB of data. Therefore, in theory, we should be able to write about 30,000 jobs/second.
| Disk Seek | 10ms |
| Sequential Disk Bandwidth | 30 MB/second |
| Average Job Size, LZO-compressed | 1 KB |
| Job Throughput, Sequential | 30,000 jobs/second |
| Job Throughput, Random | 100 jobs/second |
| Disk Bandwidth, Jobs Random | 100 KB/second |
Figure 2: disk I/O numbers
However, we were nowhere close to this ideal rate. To do a job update, we had to first locate the existing file on disk, read the whole file, decompress it, update it, re-compress it, and write the whole file back to disk. This resulted in at least two disk seeks, one to read and one to write. Our drives averaged about 10ms per seek. By writing randomly, we limited our maximum throughput to be about 50 jobs/second, and we averaged about 37.5 updates/second. Docstore v1 was only achieving about 0.125% of optimal write throughput.
When our throughput was even lower, our docstore builders fell behind. When throughput fell to 20 job updates/second, the approximate rate at which job updates were coming in, we saw replication delays, and we no longer had the freshest jobs available on our site.
We realized that because our job data accesses were essentially random, there was no benefit to writing jobs in any particular order. Since our bottleneck was write throughput, we decided to write job data in the most efficient way possible for the disk: sequentially as the updates came in. By writing the jobs to an append-only structure, the disk would avoid seeks before writes, which had the potential to allow us to write 300 times more jobs per second.
New Storage Scheme
To write our job data to disk, we created a new filesystem scheme we called the docstore queue. The new docstore updater process works similarly to the docstore v1 updater in that it writes segment files to disk, each containing the raw data for some set of jobs. The difference is, instead of putting the job data in a specific location on disk, it writes each job sequentially. The resulting segment files are copied using rsync to the docservice machines, where job data is then loaded into Memcached. In the case of a Memcached miss, job lookups fall back directly to the segment files on disk.
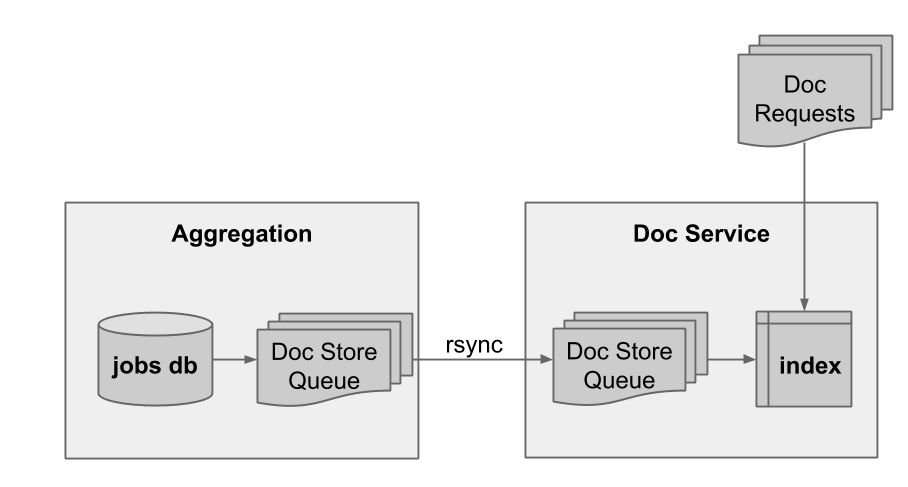
Figure 3: docstore queue
Each segment file is immutable once written. An update to an existing job writes the entire updated job contents to the current segment file. Once the current segment file reaches a certain size, it is closed, made available for slaving by downstream consumers and a new current segment file is created. Readers ignore older copies in the docstore queue. Since we average 1.5 updates per job, the extra storage is only an additional 50%. We don’t bother to garbage collect the obsolete data.
A segment file consists of a series of blocks. At the start of each block is a table of offsets that tells you where in the file to find a specific job. Given a file number, address, and index within the block, any job can be loaded in constant time.
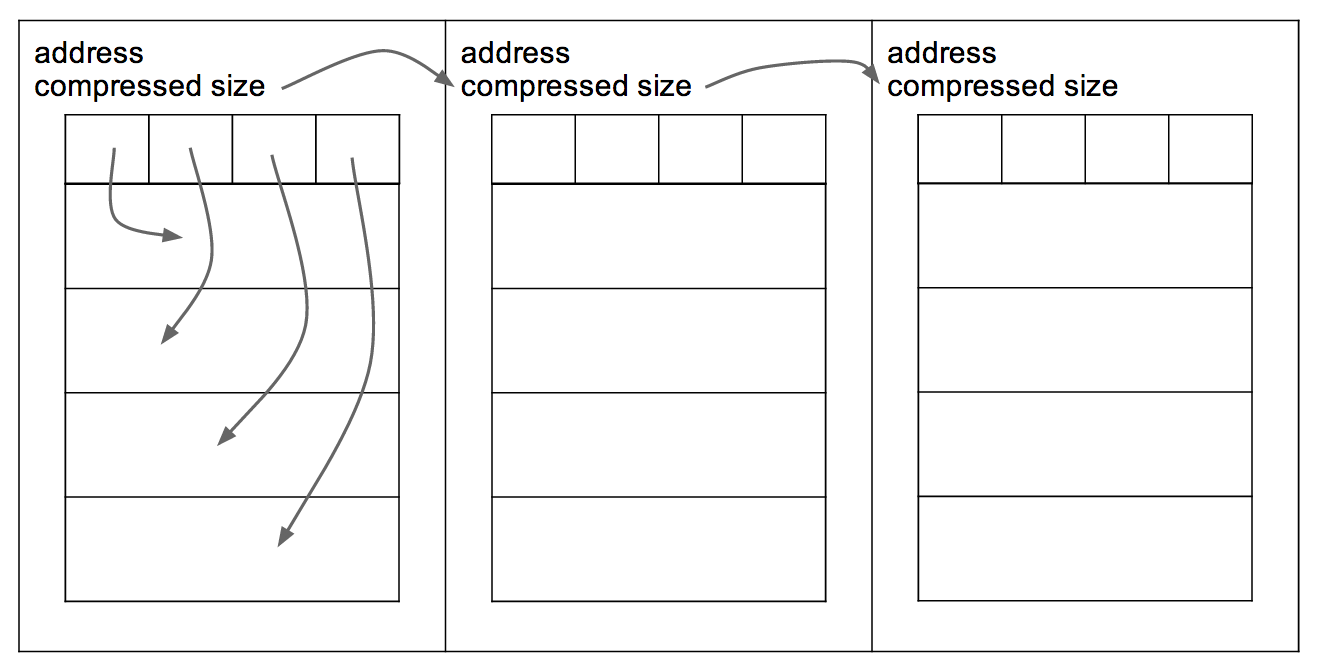
Figure 4: segment file structure
Ordering updates sequentially helps us scale writes, but we have introduced a new problem. We no longer have an easy way to look up data for an arbitrary job in this unordered docstore queue. To provide this mapping from job ID to docstore queue address, we must construct an index. This index is much smaller than the underlying data store, but we run into the same problem keeping an ordered index on disk — the disk seeks required to make updates to existing entries would be too slow. To scale index updates at the same rate as docstore updates, we must also write the index sequentially.
Alternatives for indexing the docstore queue
The obvious solution for storing this index using only sequential I/O is to not store the index on disk at all, but to write a transaction log to disk as each job update is processed. This log would be written sequentially so that all transactions could be replayed on a restart in order to rebuild the in-memory index. The docservice would keep the mapping of job ID to docstore address in memory for quick lookup. This solution does not scale because it would require storing a map of tens of millions of entries and exceed the memory constraints on our machines.
A simple optimization to the in-memory solution would be to keep a limited-size index in memory. When the in-memory index reaches its size limit, the docservice can flush it to disk. When the docservice needs to retrieve the contents of a job, it first checks the in-memory index. If that index doesn’t have the job data, then the docservice uses the on-disk index. This prevents the docservice from consuming all available system memory. However, at some point, the in-memory index will fill up again and will need to be flushed to disk a second time. We already have an index on disk so we need a way to integrate this new data with the existing data.
One strategy is to merge the in-memory index with the on-disk index and then write out a new on-disk index. Using a sorted B-tree, we could accomplish this with a simple merge algorithm. Each time the in-memory index reaches its size limit, the entire contents of the on-disk index would be rewritten. That means that every time a batch of n jobs gets written, it rewrites all existing jobs too, so the number of writes is O(n2).
If each batch contains 100,000 jobs, we will have performed 1 million job writes for an index of 400,000 jobs. By the 100th flush, the numbers would be 505 million job writes for an index of 10 million jobs. Merging the indexes every time a new batch is flushed to disk would not scale because we would eventually spend all our time merging.
Another strategy for subsequent flushes of the in-memory index is to write more indexes instead of merging. Each time the in-memory index fills up, we could just write it to disk independently of any other index. When the docservice performs a lookup, it first looks in the in-memory index. If the job data is not there, it looks in the first on-disk index, then the second, and so on, until it finds the job or has searched all on-disk indexes.
Each index is a B-tree, so the lookup to see if an element is present is O(log(n)) in the size of the index. We can consider this a constant factor due the capped index size. The number of indexes will grow over time, so reading a specific job is O(m) where m is the number of indexes on disk. While this approach scales writes, it does so at the expense of reads.
But here’s what really happened
We implemented an index using a log-structured merge tree (LSM-tree). This is a hierarchical key/value store that minimizes reads and writes. LSM-tree indexes have an in-memory index and a series of on-disk indexes, searched newest-first as described in the second strategy above. The primary advantage of the LSM-tree approach is its strategy for deciding when to merge on-disk indexes. LSM-tree only merges indexes of similar size, which means that it does not merge indexes on every flush of the in-memory index. This significantly reduces the number of writes to disk while also constraining the number of reads.
When writing a full in-memory index to disk, we must determine which on-disk indexes will be merged with the in-memory index to produce a new on-disk index. This set of indexes is called the compaction set. The compaction set is empty when the most recent on-disk index is larger than the in-memory index. The compaction set can contain multiple indexes, and it occasionally will contain all indexes on disk.
newIndex = new DiskIndex()
newIndex.add(memoryIndex)
while newIndex.size >= diskIndexes.first.size
newIndex.merge(diskIndexes.removeFirst())
newIndex.write()
diskIndexes.addFirst(newIndex)
Figure 5: compaction heuristic
Let’s walk through this algorithm in action. We start with an empty in-memory index and no indexes on disk. As updates stream in, the initial in-memory index fills up, and we write it to disk. When the in-memory index fills up again, the in-memory index is the same size as the sole on-disk index.
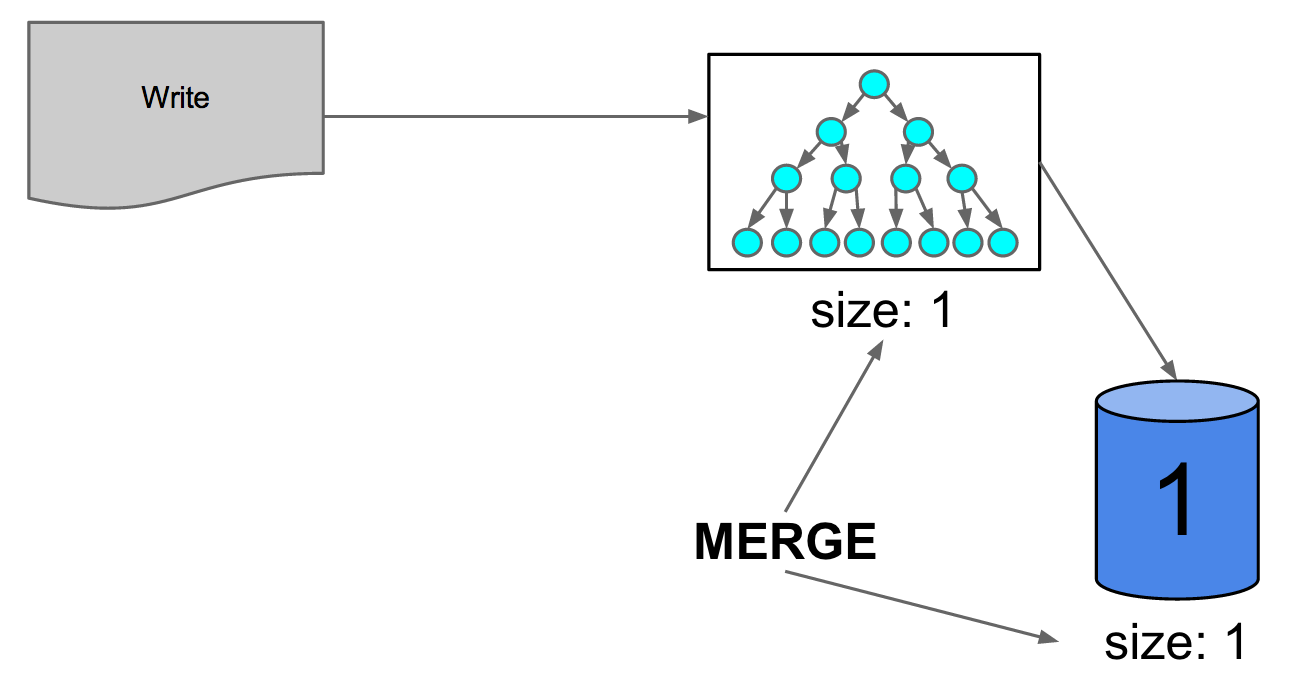
Figure 6: in-memory and on-disk index are equal size, triggering merge
We merge the in-memory index and the on-disk index into a single on-disk index containing the jobs from both.
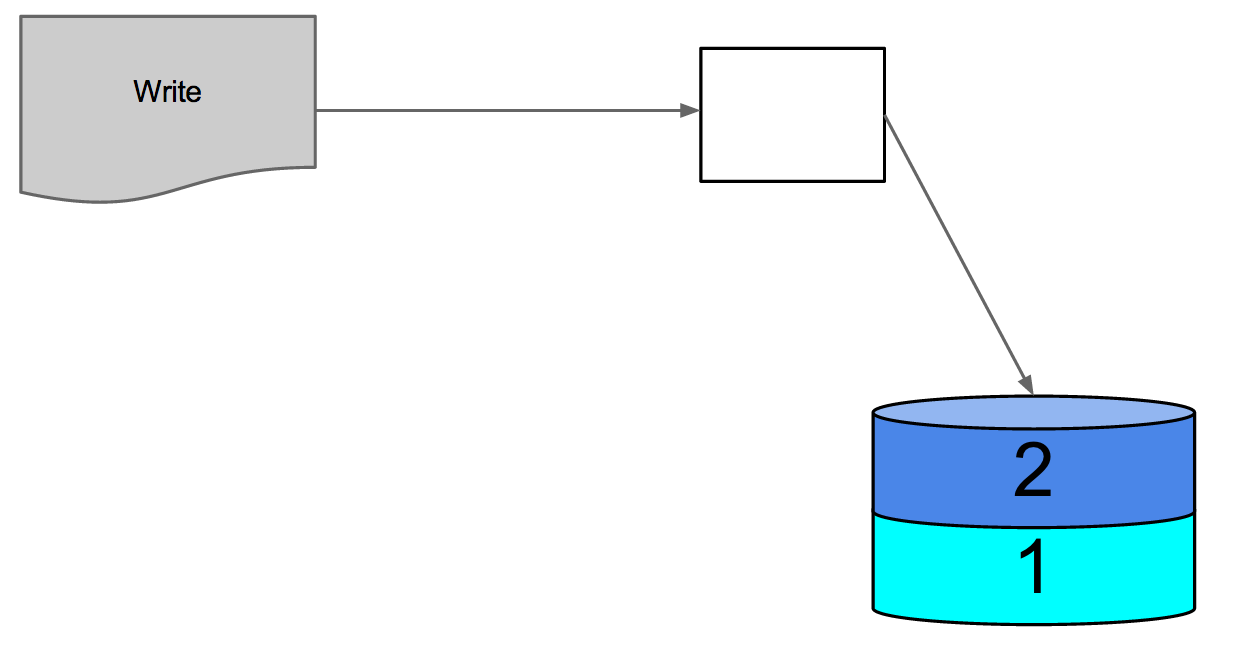
Figure 7: single on-disk index
When the in-memory index fills a third time, it is smaller than the on-disk index, which contains two batches of jobs, so we write it out as a new index.
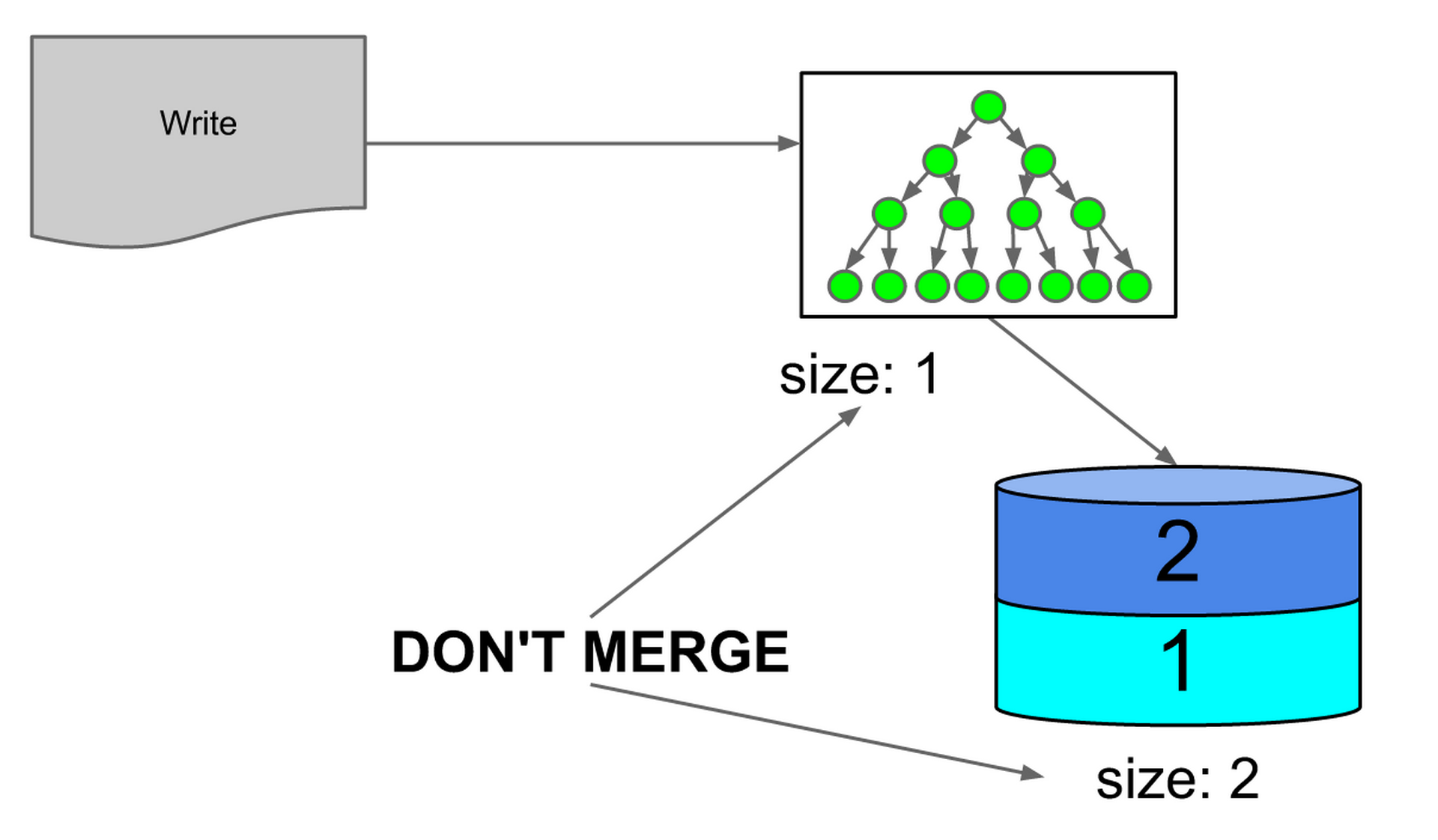
Figure 8: on-disk index is larger than in memory, so no merge
That leaves two on-disk disk indexes, the new one half the size of the older one.
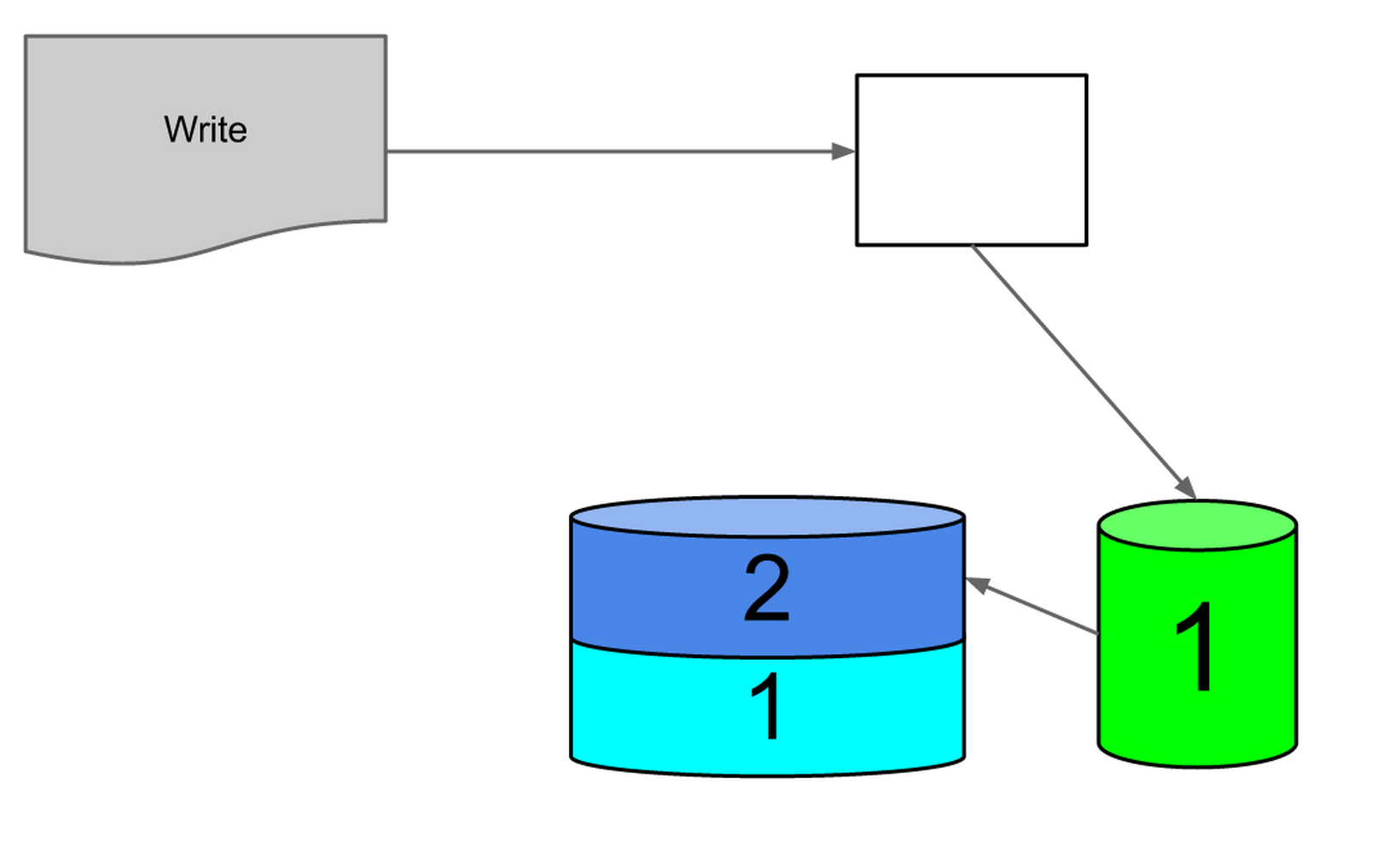
Figure 9: two on-disk indexes
The next time the in memory index fills up, it will be the same size as the first on disk index, so they will be merged.
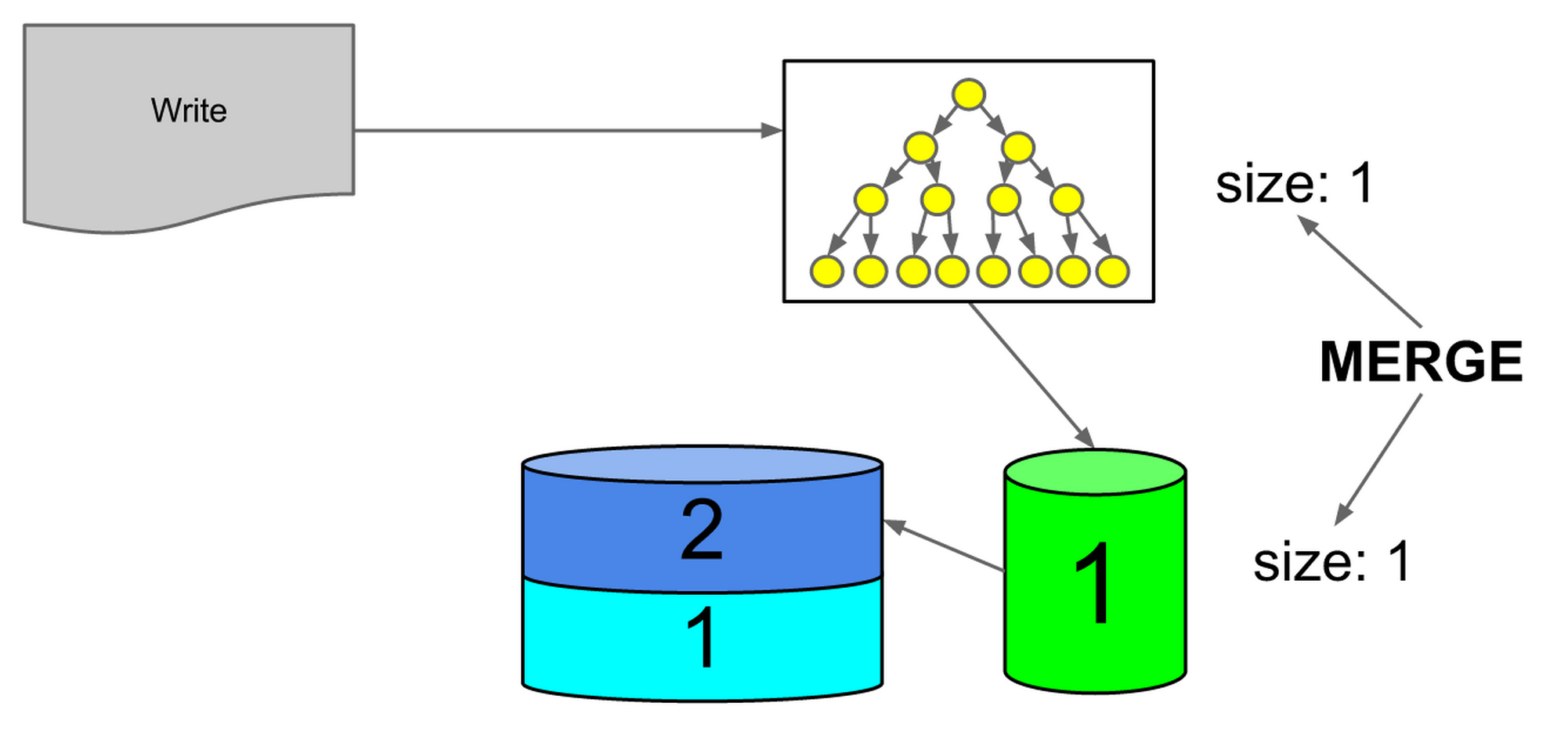
Figure 10: first on-disk index and in-memory index are same size, triggering merge
The result of that merge would be of size two. The second on disk index is size two, so we will also add that index to the compaction set.
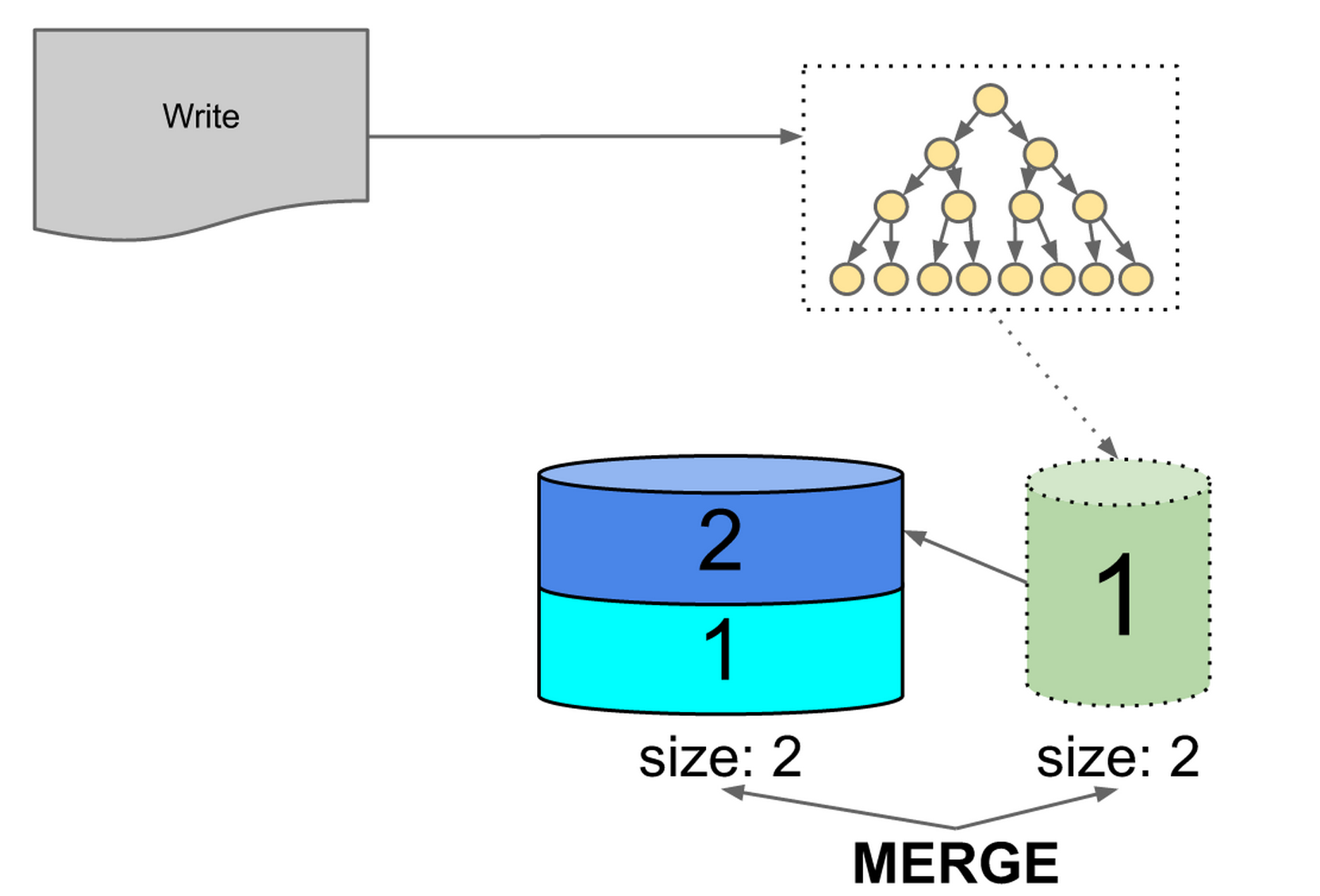
Figure 11: resulting index would be same size as 2nd on-disk index, triggering merge
The result of this compaction is now one, large, on-disk index. The first batch of jobs locations in the record log will have been written 3 times, the second batch 2 times, the third batch 2 times, and the fourth batch once.
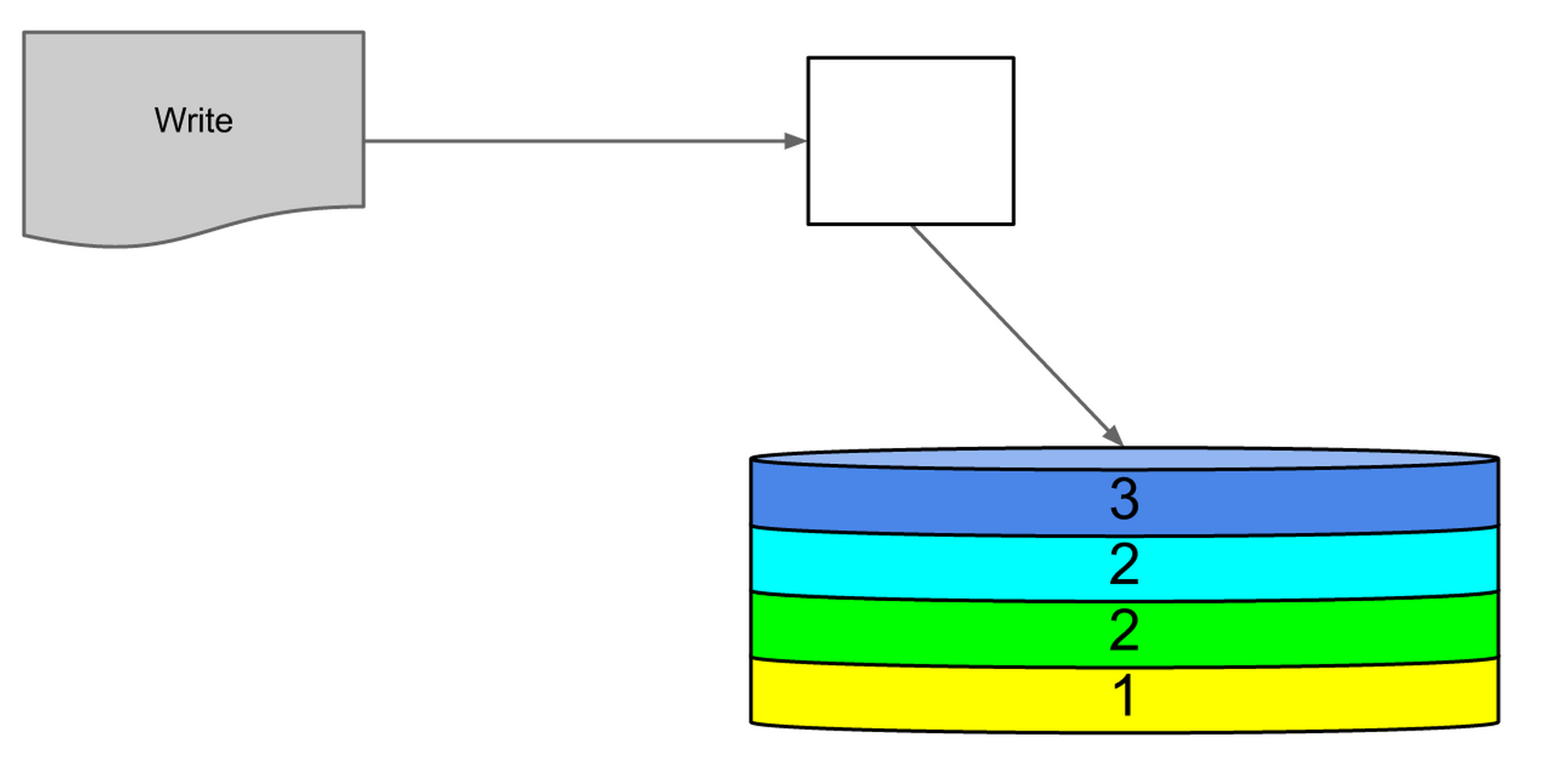
Figure 12: one complete on-disk index
Let’s look at the results of the LSM Tree approach compared to the “always merge” and “always write” approaches we discussed above for when the in-memory index fills up. If each batch contains 100,000 jobs, the LSM Tree will have done 800,000 job writes for an index of 400,000 jobs. The “always merge” approach would have done 1 million. But by the 100th flush, we will have only done 15.2 million job writes for an index of 10 million jobs and have only 3 on-disk indexes. The “always write” approach would have 100 on-disk indexes at this point, and the “always merge” would have done 505 million job writes!
As the number of jobs grows, the total number of job writes required approaches O(n*log(n)) where n is the number of jobs. The maximum number of on-disk indexes present at any time grows very slowly, being reduced to as few as one index when the compaction merge occurs.
This method of index building uses only sequential I/O, because the entire on-disk index is always written at once. Merging the indexes is simple, because they are already sorted. This method minimizes write volume, while keeping a bound on the lookup time.
There is still one problem with this solution. There are O(log(i)) indexes (where i is the number of job batches processed), and it takes log(j) time to do a lookup in each one (where j is the number of jobs in the index). The number of reads required to find a job in this data structure is O(log(i) * log(j)), which could be worse in practice than our previous docstore. We needed lookups to be as fast as the existing docstore implementation before we could use it as a replacement in production.
Optimizing Reads with Bloom Filters
If we knew which index contained the job entry we are looking for, we could eliminate the log(i) factor and read an O(log(j)) lookup time. To achieve this desired lookup time, we added a Bloom filter on top of each index.
A Bloom filter is a type of set. Its contains function is slightly different than other Set implementations in that it is probabilistic rather than definite. It may return a false positive, but it never returns a false negative. When a “no” is returned for one of our LSM tree’s indexes, it is guaranteed that the key does not exist in that index, and thus we can skip the O(log(j)) lookup. In a Bloom filter, a “yes” is actually a “maybe”, so we must check the corresponding index, but the key is not guaranteed to be present. Our particular Bloom filter implementation is tuned for a false positive rate of about 2%.
Bloom filters are relatively small compared to the index — our implementation is about 5% of the total index size. They also provide constant time lookup for a key. When the Bloom filter returns false for a jobid, we skip the O(log(j)) lookup into the underlying index. A maybe means we still have to check the index, which may not have the actual data. Given our false positive rate of 2%, the use of Bloom filters ensures that we look in a single index 98% of the time.
One limitation of the Bloom filter in our usage is that they must be kept in memory to be useful. Paging in the filter from disk to do a lookup ends up being more expensive than checking the index directly. Even though our Bloom filters are small compared to the index, they are too big to be held entirely in memory.
To address this limitation, we optimize how we load the Bloom filters to keep the memory utilization constrained. We want to keep the Bloom filter pages in memory that are most likely to say “no” to a given contains request, since “no” is the only useful answer. If a page is not in memory, instead of loading it, we assume that it would return “maybe” for all keys.
We determine the “usefulness” of a given page based on the number of requests for the page in the last t seconds multiplied by the probability of a “no” returned by that page. See figure 13 below.
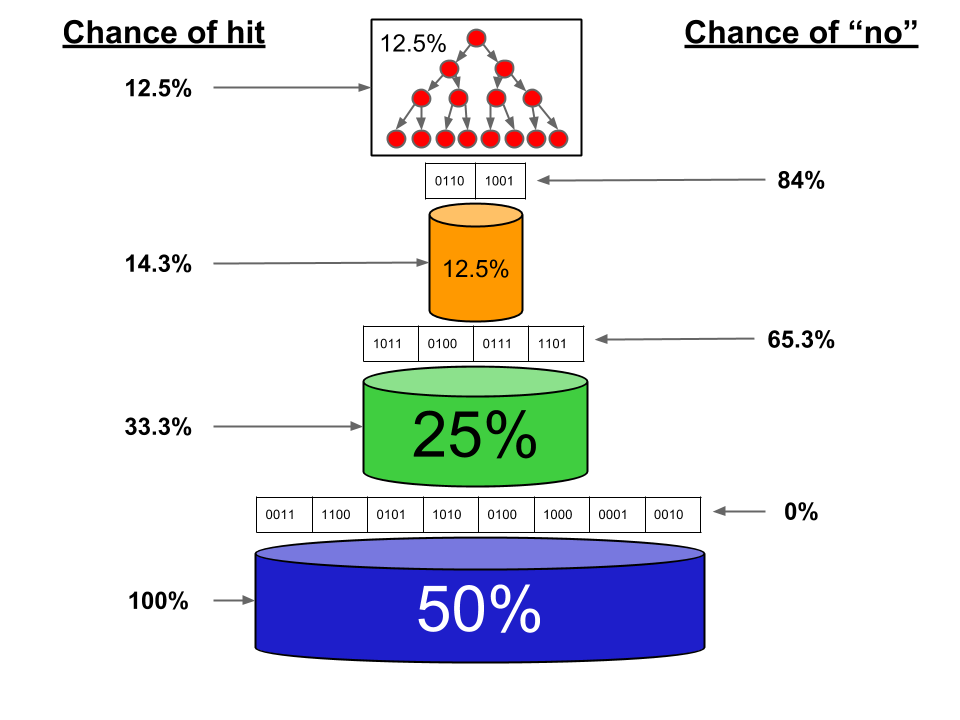
Figure 13: probability Bloom filter says no and whether the job is in index
In this example, the in-memory index contains 12.5% of the jobs, the newest on-disk index contains 12.5%, the next on-disk index contains 25%, and the oldest index contains 50%. We assume that the requested job ID exists in one of the indexes. If the in-memory index doesn’t contain the job, then there’s a 14.3% chance that the newest on-disk index contains it. If not, a 33% chance the 2nd on-disk index contains it. If the job is not contained in the first three indexes, then there is a 100% chance it is in the oldest index. Having a Bloom filter on the oldest index is not useful in this case, because we know the key exists.
Since job data access is not evenly distributed across the entire index, we also keep a count of actual accesses per page because there tend to be hotspots. For example, newer jobs tend to be accessed more than older ones. We can multiply the access counts by the usefulness to determine which pages to keep in memory at all times.
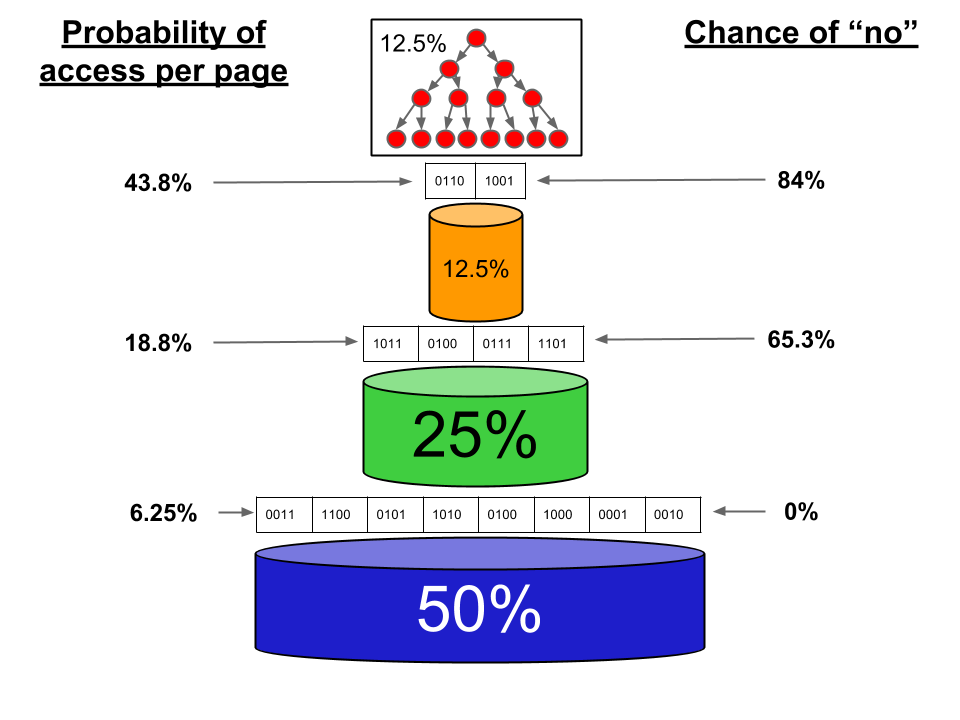
Figure 14: usefulness of each page of Bloom filter
Index Durability
Our new solution meets our write throughput requirement, while keeping reads fast without exploding memory utilization. We have one more requirement: the index must be durable. We have to be able to recover from a system failure at any time without losing any data.
To meet that requirement, we added a write-ahead log for the in-memory index. By writing sequentially to an on-disk log file prior to adding data to the in-memory index, we can easily restore its state at any time. When a docservice instance comes back online, it can replay the write-ahead log to rebuild the in-memory index and continue processing new updates to the docstore queue, with no data loss.
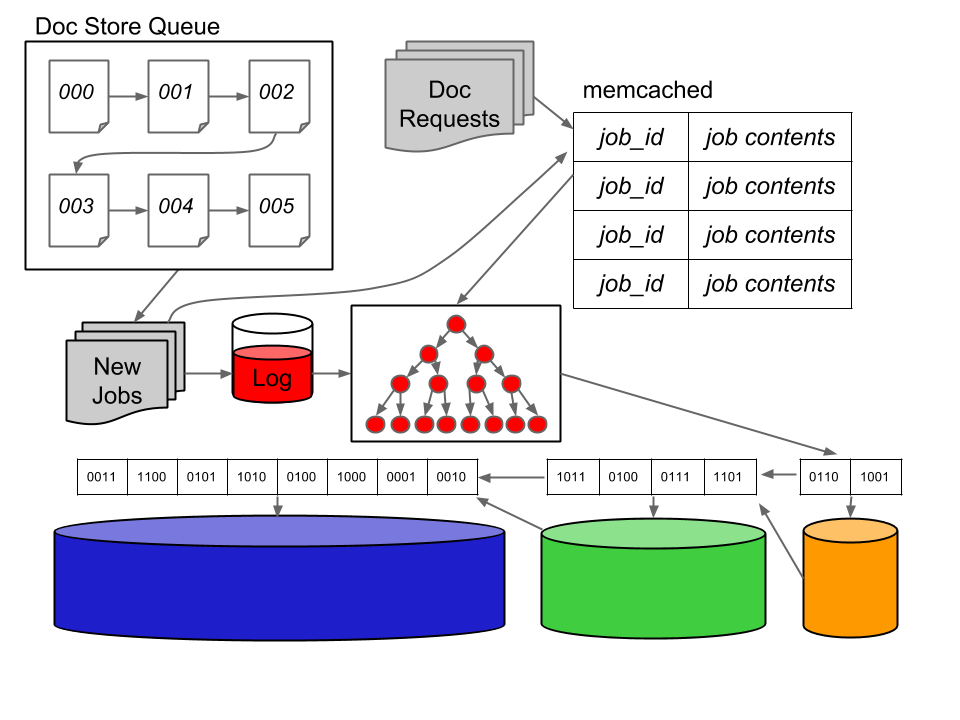
Figure 15: complete document serving system
Benchmarks
Around the same time that we were deploying docstore v2, Google announced the release of LevelDB, which is their own LSM tree implementation. Since we had already written ours, there were no plans to take advantage of their work. We did, however, want to see how our code stacked up against Google’s. We also compared our LSM tree to Kyoto Cabinet, a commonly used B-tree implementation, to show the benefit of sequential disk writes and efficient I/O benefits.
For our benchmark, we performed 10,000,000 writes with an 8-byte random key and a 96-byte value. We first wrote all keys in random order. Then, we read all keys in random order. The results were as follows.
| Implementation | Random Writes (seconds) | Random Reads (seconds) |
| Indeed LSM-tree | 272 | 46 |
| Google LevelDB | 375 | 80 |
| Kyoto Cabinet B-tree | 375 | 183 |
Our implementation was the fastest, but the B-tree implementation wasn’t as far behind as we expected. 10 million entries of 100 bytes each is still less than 1 GB, meaning that the entire index fit in memory. We ran the benchmark again, but this time limited the available memory to 512 MB. The results make the benefits of our techniques more apparent.
| Implementation | Random Writes |
| Indeed LSM-tree | 454 seconds |
| Google LevelDB | 464 seconds |
| Kyoto Cabinet B-tree | 50 hours |
The B-tree implementation took 400x longer than the LSM-tree implementations, primarily because it is constantly re-writing the data on disk as new keys come in.
It scales
Docstore v2 has been in production now for over one year. Docstore v1 took 12 hours to build one day of job updates in 2011. Docstore v2 takes only 5 minutes to process a whole day’s data, even though the number of job updates we process in a day has grown significantly since 2011. It takes an average of 9 minutes from the time we discover a new job somewhere on the internet to having it live and retrievable in docservice.
In July of 2013, we aggregated over 79 million job updates and served over 1 billion documents every day, with peaks of 22,000 documents/second. At that scale, our document serving is still extremely fast.
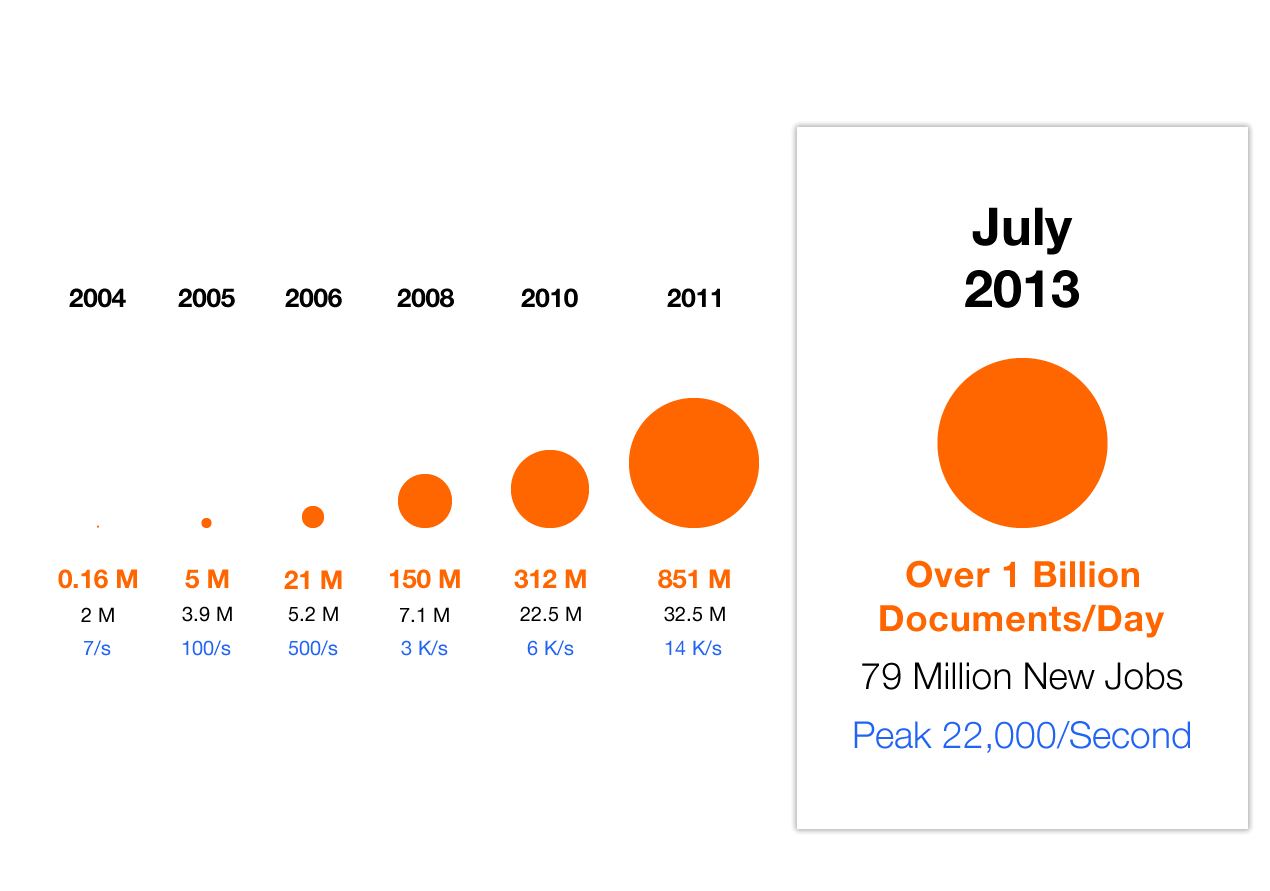
Figure 16: growth of document serving over time
Our docstore queue is currently 60GB in size and contains every job that indeed has ever known about. The LSM tree that tells us exactly where to find any job in the queue is 23GB. The Bloom filter that tells us whether a job is likely present in a given index is 1.6GB.
Job reads from docservice take on average 5ms and the set of jobs is kept current throughout the day by the constant stream of updates coming through the docstore queue with no performance impact on the reads.
We have also been able to use the same infrastructure that builds the docstore queue for some of our other systems. We now use a similar queue and LSM tree index in resume, company pages, job recommendations, and several other backend data artifacts that we use to determine the most relevant jobs to show for a search. Each use case is slightly different, but the underlying benefits of scalable reads and writes over very large data sets is common to all.
If you like to solve these kinds of interesting problems at scale, take a look at some of our career opportunities.