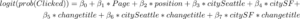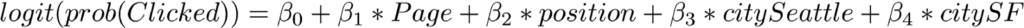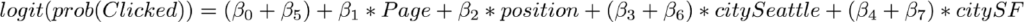データ分析について特集している本シリーズの前回の記事では、私たちは「データサイエンティストなんてものはない」という主張をしました。代わりに、「データサイエンティスト」という呼び方は、いくつもの特定の職種を指すようになってきています。なので、異なるスキルや職務に加え、データサイエンティストとは、どんな人々を指し、どのようなバックグラウンドを持つ人たちなのかを知りたい、と私たちは考えました。
本記事では、私たちが、現役のデータサイエンティストの履歴書のデータを詳しく調査する中で、データサイエンティストが、さまざまな研究分野、学歴と職歴を持つことを発見したこと、そして、データサイエンティスト、アナリスト、エンジニア、ソフトウェアエンジニア、そして機械学習エンジニアの職種間の類似点と異なる点について、このデータから読み取れることを掘り下げたいと思います。
データサイエンティストとは何者か?
もしあなたが、身の回りのデータサイエンティストに、データ分析の前には何をしていたか尋ねるなら、おそらく各々が違う答えをくれるでしょう。彼らの多くは、天体物理学から動物学まで幅広い分野の修士号や博士号を持っています。一方で、近年大学が開講した新しいデータ分析の大学院プログラム出身の人たちもいます。そして、ソフトウェアエンジニアリングやデータ解析などの技術職出身の人たちもいます。
Indeed では、we help people get jobs を理念としています。これを実現する一つの方法に、採用企業のニーズにマッチする人材が見つけやすいように、求職者が履歴書を登録できるようにしています。そんな私たちの持つデータセットは、何万もの現職そして元データサイエンティストによって登録された履歴書も含んでいます。この履歴書データを利用して、データサイエンティストがどこからやってくるのか洞察を得ることができるのです。
学歴は重要?
最終学歴
まず、「データサイエンティスト」や関連分野¹ の職に就いている人々の最終学歴について着目しました。

前回の記事の中で発見した特徴的な役割の一部を反映しているので、データエンジニア、データアナリスト、ソフトウェアエンジニア、機械学習エンジニア、そしてデータサイエンティストの職種を選びました。²
データサイエンティスト
わたしたちが調べた職種のなかで、データサイエンティストの教育レベルの平均は最も高いことがわかりました。
- データサイエンティストは、その他の職種よりも博士号を持つ人が多い。しかし、彼らの 20% のみが博士号取得者であるように、データサイエンティストになるのに博士号は必須ではない。
- データサイエンティストの 75% が上級学位(修士号または博士号)を取得。
- 高卒または短大卒は、データサイエンティストの 5% 未満。
機械学習/データ/ソフトウェアエンジニア
ソフトウェア/データエンジニアは、大学院卒よりも四大卒が多く、機械学習エンジニアは上級学位取得者である傾向が強いことがわかりました。
- 機械学習エンジニアの教育レベルは、データサイエンティストと同じような割合であったが、博士号取得者の割合は、両職種を比較すると 30% 程度少ない傾向にあった。この結果は、Stitch Data による同様の調査とおおむね一致している。
- エンジニアリングに特化した職種は、一定数の修士号取得者も含みつつ学士号が多数を占め、博士号保持者は 5% 未満。
- データエンジニアの 4 人に 1 人が、高卒または短大卒である。
データアナリスト
データアナリストの最終学歴の割合は、データサイエンティストとは全く異なっており、むしろソフトウェアエンジニアの学歴 ³ に近似していることがわかりました。
- データサイエンティストの博士号取得者の割合はデータアナリストと比べると、ほぼ 10 倍となり、修士号取得者の割合は 2 倍程度となっている。
- 後述するように、この傾向は、ソフトウェアエンジニアがデータ分析へと転向するパターンが一因となっている可能性がある。
- これは、採用企業がデータサイエンティストを上級職経験者として見なしており、博士号が関連職種として扱われていることを示唆する。もしくは、修士号や博士号の研究過程で各人が受ける研修が、調査が基本となるデータサイエンスの仕事への下地を作り上げているのかもしれない。
研究分野
職種ごとに研究分野の割合を調べたところ、いくつか興味をそそる結果がありました。
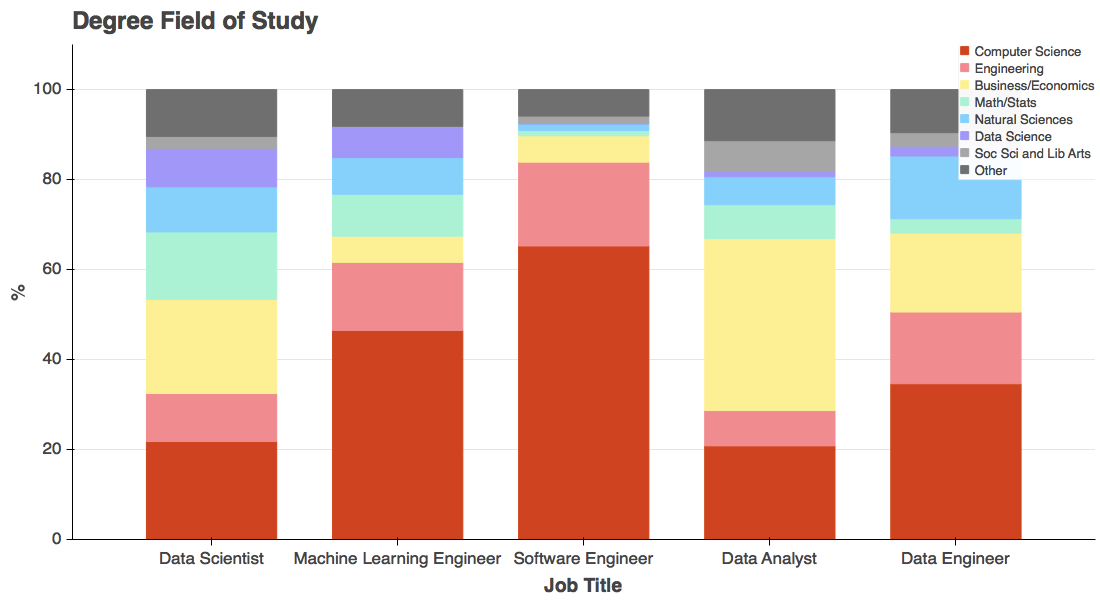
「データサイエンティスト」という職種には、調べたその他の職種よりも、最も多様な専攻分野を内包しており、多数を占めるものはありませんでした。各職種のジニ不純度を計算することで、この多様性を定量化することができます。
ジニ不純度 (大きくなればなるほど、研究分野が多様であることを示します。)
- データサイエンティスト— 85%
- 機械学習エンジニア — 73%
- ソフトウェアエンジニア— 53%
- データアナリスト — 78%
- データエンジニア— 79%
データサイエンティスト
データサイエンティストは、私たちが調査した職種の中で、明らかに最も多様な専攻分野を含み、ソフトウェアエンジニアの教育バックグランドは最も多様性が小さいことがわかりました。社会学専攻はデータサイエンス人口の中ではどちらかというと少数ですが、それでもデータサイエンティストの 5% を占めています。また、データサイエンス専攻は、それよりもやや大きな割合で、データサイエンティストの 9% を占めています。これは、各大学のデータサイエンスのプログラムが新しいことを鑑みると、やや驚く結果と言えるでしょう。
機械学習エンジニア
私たちの持つデータによると、データサイエンティストと機械学習エンジニアでははっきりと違いを示しました。機械学習エンジニアの 60% が、コンピューターサイエンスやエンジニアリングを専攻しており、「データサイエンティスト」という職種の人と比べると、これらの専攻をする傾向はほぼ 2 倍だと言うことがわかりました。また、私たちのサンプル内の「機械学習エンジニア」という職種には、社会学専攻だった人はほとんど存在しませんでした。
ソフトウェアエンジニア
ソフトウェアエンジニアは、当然とも言えますが、コンピューターサイエンスやエンジニアリング専攻に、より大きく集中しています。機械学習エンジニアは、ソフトウェアエンジニアとデータサイエンティストの融合だとも言われます。私たちのデータは、この主張を裏付けているようです。
データアナリスト
データサイエンティストと同じように、データアナリストも教育の上で様々なバックグラウンドを持つようです。ビジネス、経済学、社会学の専攻が多く、数学、統計、自然科学専攻が少ないという点は、データサイエンティストとは異なります。また特筆すべき点は、データサイエンス専攻の学位を持つ人は、データアナリストよりも、データサイエンティストに多くみられるという点でしょう。
データエンジニア
データエンジニアの専攻分野の割合は、データサイエンティストと機械学習エンジニアの中間のようなものを示しています。しかし、前項で書いたように、データエンジニアには、最終学歴が高校であるという人も少なくありません!
データサイエンティストの前職とは?
驚くことではありませんが、多くの人(サンプルのおよそ 25%)が、前職も現職と同じ職種だったことがわかりました。
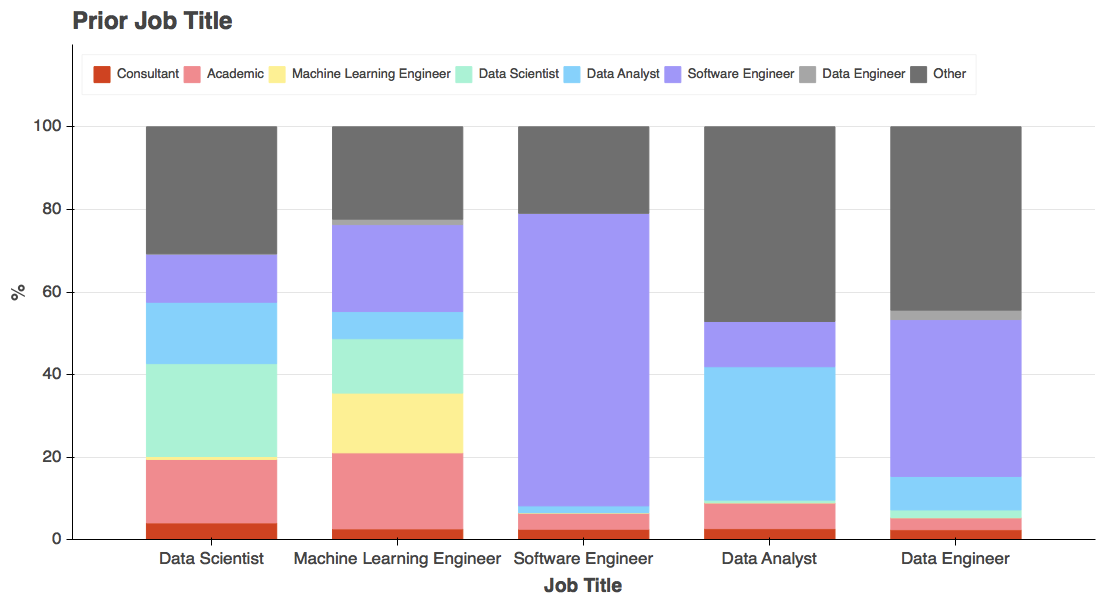
これは、ソフトウェアエンジニアの中では特に顕著で、前職でもソフトウェアエンジニアの職種についていた割合が 71% と、この傾向が非常に高いことが分かりました。これはおそらくソフトウェアエンジニアリングの分野が、最近まで職種として存在しなかったデータサイエンスとは違い、相対的に成熟していることが要因と考えられます。
ここでいう「学術」とは、大学に雇用されているか、学術的な環境の中で研究者として勤めていたことを指しています。特に大学院生は、このようなポジションについていた傾向にあり、大学院卒の人材が多く存在する分野 ( データサイエンス、機械学習エンジニア、データアナリスト) のほとんどは、こうした学術界からの転向を最も多く含んでいます。
おそらく、もっと興味深い質問は、「違う分野で働いていたデータサイエンティストの前職は何だったのか?」でしょう。
![]()
ここで、興味深いパターンが見えてきます。データサイエンティスト、機械学習エンジニアそしてソフトウェアエンジニアは、卒業後すぐに就職する傾向にあるのです。「その他」とされている前職は、ケータリング、チューター、店員など、卒業までの間に行う仕事などで、関連性がありません。
多くの職種は、データサイエンティストや機械学習エンジニアに転向していますが、データサイエンティストと機械学習エンジニアによる他の職種への転向はほとんど見られません。これにはおそらく、相対的な分野の大きさ、そして「データサイエンティスト」と「機械学習エンジニア」の職種がまだ初期にあること、さらには近年、こうした職種の人気が伸びていることなどが要因としてあげられるでしょう。一方、こうした傾向は、個人が職種を転向したりキャリアパスを前進する様子を表す、興味深い現象を観測しているのだとも思います。
以下の弦グラフは、各職種間での主な転向を表しています。弦の色が転職する前の元の職種を表しています。
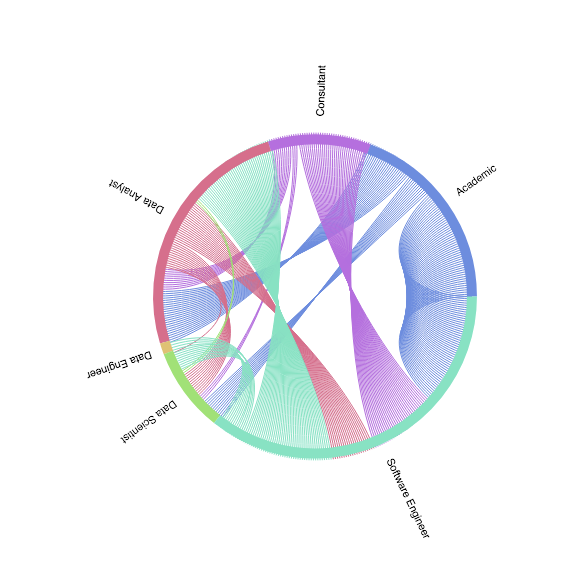
ソフトウェアエンジニアは全体の中で大きな割合を占めています。そこから多くの人はアナリストへ転向し、また一方ではポンッとデータサイエンスへ移っています。
データサイエンスには、学術系、アナリスト、そしてソフトウェアエンジニアから同程度流入してきています。ソフトウェアエンジニア、最もデータアナリストに転向する傾向がありますが、これはデータサイエンティストの職種の数よりもデータアナリストの職種の数のほうがより大きいことに一因しています。
現状では、データサイエンスからの転向する人は非常に少ないことがわかります。また、この傾向が将来的に変わっていくかは不明です。ここで重要なことはデータサイエンスの分野が、様々なバックグラウンドを持つ人からなり、そしてソフトウェアエンジニアがデータサイエンティストになったり、データアナリストがデータサイエンティストになるのは比較的一般的だということです。これは、ソフトウェアエンジニアリングの職種から転向を考えている人に、実現可能な道として提示できるかもしれません。
データエンジニアリングへの転向は、ほぼ独占的にソフトウェアエンジニアリングからの流入となっています。⁴
結論
データサイエンティストはどこから来るのか、というのは色々なところからだと言うのがわかりました。分野を主に占めるのは、修士号ならびに博士号取得者ですが、学士号取得者も充分多く、職種の 26% を占めています。今のところ、データサイエンス業界で顕著な出身専攻分野はありません。むしろ、ソフトウェアエンジニア等と比較すると、データサイエンティストのバックグランドは多様です。さらに、多くの人が、ソフトウェアエンジニアリングからデータ分析などの他の技術職からデータサイエンスへと転向しているのがわかりました。
機械学習エンジニアの学歴は、データサイエンティストと似ていますが、エンジニアリングのバックグラウンドが比重を占める傾向があり、ソフトウェアエンジニアリングから流入してくる傾向が大きいことがわかりました。データエンジニアリングの専攻分野も、やはりエンジニアリングに集中していますが、他の職種と比べた時に学位レベルは低い傾向が見られました。
データサイエンス職を探している方へのアドバイス
大学院は、現状もデータサイエンティストが業界参入するにあたって最も有力な方法でしょう。データサイエンスの学位は、ますます存在感を高め、業界に参入するうえで当たり前のものになってきているようです。現在修士課程にいる方は、きっと身の回りの誰かしらがデータサイエンスの業界で働いているのではないでしょうか。彼らに連絡をとって、どのように就職活動を行ったのか話を聞いてみることをおすすめします。
ソフトウェアエンジニアとデータアナリストによるデータサイエンス職への転向は、ごく普通に行われており、こうした流入層はデータサイエンティストの一定数を占めています。今後転職を検討する方も、こうしたルートを考慮しておくべきでしょう。
データサイエンティストを採用する企業へのアドバイス
ゼネラリストのデータサイエンティストを採用中の場合、業種や学位が想定するものと違うから選考しない、というのは避けましょう。データサイエンティストは学歴もバックグラウンドも様々です。また多くの場合、なにがしかの上級学位を取得していますが、だからといって特定の専攻分野出身者が多いわけでもありません。
学術界からデータサイエティスト経験者や科学者を採用するのに苦戦している場合、ソフトウェアエンジニアリングやデータアナリストの職種からの採用を検討してはどうでしょうか。こうした転向はデータサイエンス業界では非常に一般的なものです。
また、別の記事でお伝えする予定ですが、採用している職種についてしっかりと把握することが大切です。データサイエンティストが必要だけれどエンジニアリング的な職務が多い場合には、「機械学習エンジニア」という職種名への変更を検討しましょう。もし、ビジネス中心の職歴を持つデータサイエンティストの採用を考えている場合、アナリストの採用を視野にいれましょう。データベースやインフラのスキルに特化した人材が必要であれば、データエンジニアの採用を検討し、その際学歴はあまり重要視しないでください。
最後に、ゼネラリストのデータサイエンティストがチームに必要だと考えている場合、色々なバックグラウンドの中から採用を行ってください。Indeed のデータサイエンスとプロダクトサイエンスのチームは、天文学、社会学、生物学、数学、経済学そして経営学など様々な分野から集まっています。人口統計学的な属性においても、そして専攻分野においても、多様性のあるデータサイエンスチームを持つことは、素晴らしい仕事をするうえで不可欠です。⁶ ⁷
脚注
¹ 「データサイエンティスト」と履歴書に書いている求職者の履歴書を調べており、ここでは確かにバイアスがあることに注意されたい。これは、この業種で数年経験している可能性のある個人を対象に調査しており、より最近の傾向を如実に表しているものとは言えない可能性がある。
² 各職種名については、関連する職種名もバケットを作成した。例えば、「シニアデータサイエンティスト」はデータサイエンティストのカテゴリ内に存在し、「C++ プログラマー」は、ソフトウェアエンジニアのカテゴリに存在する。
³ Paula Leonova 氏による本記事は、データサイエンスとデータアナリストの違いについて、良質でデータに基づく議論が展開されている。
⁴ 職種のヒエラルキーなどを示唆する意図はないことを、ここで必ず明確にしておきたい。多くのソフトウェアエンジニアの職務は、一般的なデータサイエンティストの職務よりもずっと上級レベルである。ここでは単に、最近姿を現しつつある転職パターンに言及している。
⁵ Stitch は、データエンジニアリングの職務の解説を分かりやすくまとめている。この中で、ソフトウェアエンジニアリングとの重なる部分について言及がある。
⁶ 職場における多様性の重要さについては、以下の記事も参照されたい。https://press.princeton.edu/titles/8757.html, https://www.mckinsey.com/business-functions/organization/our-insights/why-diversity-matters
http://www.chabris.com/Woolley2010a.pdf
⁷「専攻分野の多様性」について、さらに大きな多様性についての議論とまとめることは、筆者の意図するところではない。全ての次元において多様性は、素晴らしい仕事を成し遂げ、より良い社会を作るためには不可欠であり、専攻分野を重点的にとりあげるだけでは、現在米国の技術職者間において多様性が圧倒的に欠如している問題を改善できない、と筆者は強く信じている。Stitch による記事は、データサイエンス業界も、多様性を様々な視点から見ても、エンジニアリング職と状況はあまり変わらないと指摘している。