(編集者より: この記事は、 Indeed が提供する、 A/B テストのオープンソース・フレームワークである Proctor についての連載シリーズの第 2 回となります。)
Indeed における Proctor
前回の記事では、 Proctor が提供する機能やツールについて説明した。
Proctor は Indeed が提供するオープンソースの A/B テスト・フレームワークである。
今回は補足として、 Proctor がどのように Indeed の開発プロセスに取り入れられているかを更に詳しく書いていく。
カスタマイズされた Proctor Web アプリ
Proctor Web アプリの Indeed 内部でのデプロイは、 Atlassian JIRA 、 Subversion 、 Git 、そして Jenkins を取り入れている。
課題の関連づけや、様々なサニティ・チェック (正常に動作するかの確認) 、課題管理の自動化に、私たちは JIRA を使用している。
変更履歴の管理に使用するのは、 Subversion。
(これまでの経緯から Subversion を使用しているけれど、 Git も選択肢の 1 つだ。)
テスト・マトリックスのビルドには Jenkins を使用している。
Prcotor Web アプリは内部管理用のデータストアと統合され、どのアプリケーションで、どのバージョンのテストが使用されているかを表示してくれるのだ。
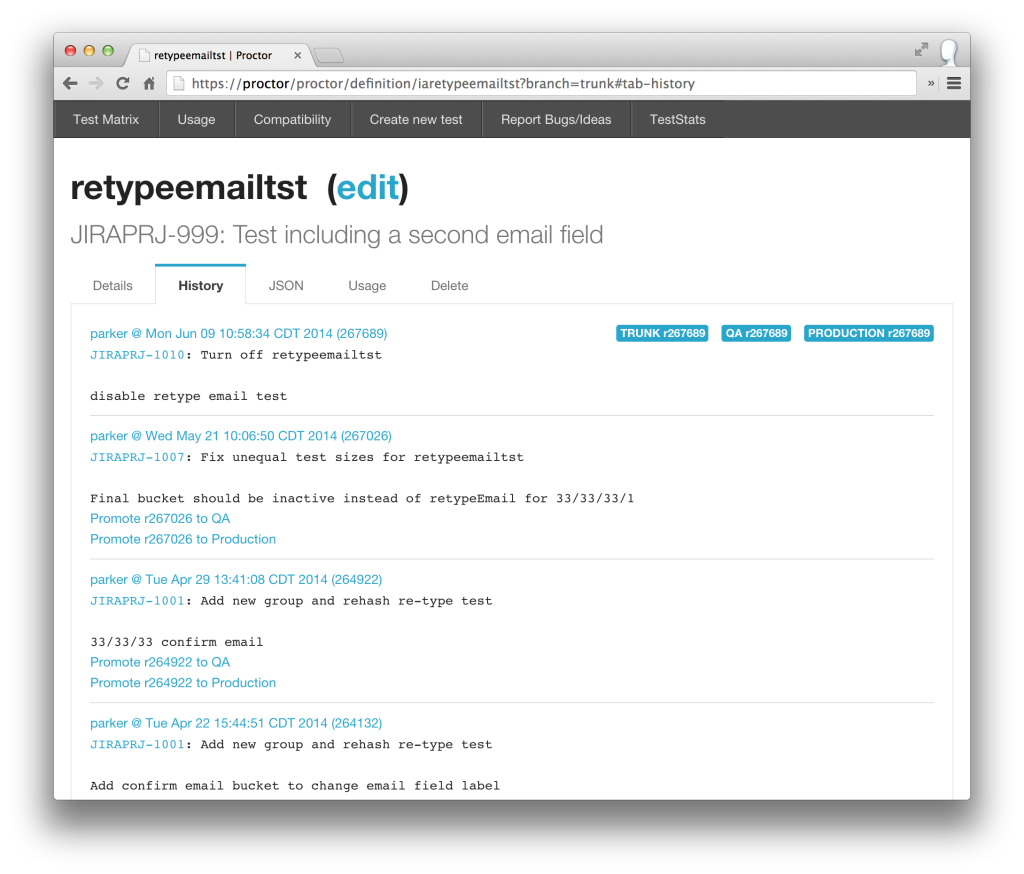
図 1 : アプリ内のテスト定義変更履歴のスクリーンショット
JIRA による課題管理
Indeed では、テスト定義への変更を含む全課題を、 JIRA で管理している。
新規テストのリクエストや既存テストへの変更は、 JIRA 内でカスタムの課題タイプとして表示される。これは ProTest と呼ばれている(Proctor Test の略)。
ProTest の課題は、テストが属するアプリケーション用の JIRA プロジェクトの中で管理されている。また、 ProTest の課題は、 Proctor Web アプリのデプロイに結び付けられたカスタムのワークフローを使用している。
アサインされた ProTest の課題を承認すると、課題を承認した人(オーナー)が Proctor Web アプリを使用して、テスト定義を変更する。
変更を保存すると、課題のオーナーは ProTest の課題のキーを提供する必要がある。 Proctor のテスト定義レポジトリにコミットする前に、 Web アプリはまず、その ProTest の課題が存在して、有効な状態である(例: クローズされていない等)ことを確認するのだ。
その後、コミットのメッセージ内のキーを参照しながら、 Web アプリは変更を(ログイン中のユーザーに代わって)コミットする。
課題のオーナーが ProTest の課題に対する変更を全て実行した後、JIRA のワークフローは通常以下の通りになる。
- 課題のオーナーが課題を解決し、ステータスは QA Ready ( QA に回す準備が完了) になる。
- リリース・マネージャーは Proctor Web アプリを使用して、 QA に新しい定義を渡す。Web アプリは、課題のステータスを In QA(QA 実行中) に進める。
- QA アナリストは QA 環境で予想されるテストの挙動を検証し、その後 Production Ready (本番に回す準備が完了) にステータスを進める。
- リリース・マネージャーは Proctor Web アプリを使用して新しい定義を本番環境に進ませる。そうすると、テスト変更は1、2分の間に世界中に配信され、有効となる。Web アプリは、課題のステータスを In Production (本番実行中) に進める。
- QA アナリストは本番環境で予想されるテストの挙動を検証し、課題のステータスを Pending Closure (クローズ待ち) に進める。
- 課題のオーナーは、課題を「解決」し、全作業が完了し、本番に移行したことを反映する。
有効なテストグループのサイズを調整するだけならば、 Proctor Web アプリはこのプロセスをスキップし、自動的に変更を本番へプッシュする。
QA チームがテストへの修正を検証するのは、これらの修正が、予期せぬ挙動や、他のテストとの連携に不具合を引き起こすことがあるからだ。
テスト定義内のルールは、デプロイ可能なコードの形になっており、正確さを常に保つ必要がある。
検証のステップは、修正が本番で有効になる前に最後にもう一度、予期せぬ影響を未然に防ぐ機会を、 QA アナリストに与えてくれるのだ。
以下のルールの場合は、米国とカナダ国内の英語ユーザーのみを対象にテストを利用可能にしようとしているものだ。
(lang=='en' && country=='US') || country=='CA'
ただし、括弧が誤った場所にあるため、カナダ国内のフランス語を使用するユーザーにも、彼らにはまだ対応していない挙動が見えてしまう。開発者は、自分の望むグループに自身を強制的に割り当てている場合、このバグを見落としてしまっている可能性がある。
QA 中にバグをすぐに見つけることができれば、期待される挙動が本番へ到達しなかったことに気づくまでの時間を無駄にせずに済むのだ。
テスト定義ファイル
テスト定義は proctor-data と呼ばれる単一の共有プロジェクト・レポジトリに保存される。プロジェクトは 1 つのテスト定義に対して、 1 件のファイルを含んでいる。
test-definitions/<testName>/definition.json
ほとんどの場合、テストの修正は Proctor Web アプリ 経由で行われる。
これをうけて、定義ファイル内の JSON への変更を行い、(ログイン中のユーザーに代わって)これらの変更を、バージョンを管理するレポジトリに、コミットするのだ。
定義ファイルは proctor-data 内で qa と production の2つのブランチに複製される。テスト定義の修正が QA に送られると、全てのテスト定義ファイルは qa ブランチにコピーされ、コミットされる。(単一のリビジョンに関連する diff を適用または「チェリーピック」するのではない。)
同様に、テスト定義の修正が本番に送られると、全ファイルは production ブランチにコピーされ、コミットされる。 1 つのテスト定義に対して、 1 件のファイルが存在するので、このシンプルなアプローチは、マージのコンフリクトを避け、どのトランク・リビジョンの差分をチェリーピックするか決定せずとも、 JSON 定義の整合性を保っている。
テスト・マトリックス― ビルドとデプロイ
Proctor はテスト定義ファイルのセットを単一のマトリックス・ファイルにまとめることができるビルダーを含んでいる。
同時に、テスト定義が内部で一貫していて、未定義のバケット値を参照せず、アロケーションの合計が 1.0 になることを、このビルダーは保証してくれる。
また、これは Java から直接呼び出すことも可能なほか、 Ant タスクや Maven プラグインを介し呼び出すことも可能だ。
Indeedでは、 proctor-data プロジェクト内にある Ant を呼び出す Jenkins のジョブを使用して、 1 つのマトリックス・ファイルをビルドしている。 Maven を使用したビルドの例は、 GitHub から利用可能だ。
テスト変更がトランクにコミットされる度に、継続的インテグレーション (CI) ツールである Jenkins のジョブが、テスト・マトリックスをビルドしている。
そのマトリックス・ファイルは、 CI 環境のアプリケーションとサービスに利用可能だ。
リリース・マネージャーがテスト変更を QA に送ると、 QA 専用の Jenkins のジョブが qa ブランチを使用してテスト・マトリックスをビルドする。
生成されたマトリックス・ファイルは、その後で全 QA サーバーにパブリッシュされる。マトリックスをコンシュームするサービスとアプリケーションはそれを定期的にリロードする。
これに相当する本番用 Jenkins ジョブは、 production ブランチにおける新規の変更を処理する。
アプリケーション内の Proctor
各プロジェクトの Proctor 仕様の JSON ファイルは各プロジェクトのソースコードと一緒に通常のパスに保存されている(例:src/main/resources/proctor)。
ビルドの際には、コード・ジェネレータを( Maven プラグイン または Ant タスク を経由して)呼び出し、コードを生成する。続いて、プロジェクトのソースコードと一緒にそのコードはビルドされる。
一般的に新しいテストをローンチする際には、テスト・マトリックスを、それに依存するアプリケーションコードより先にデプロイする。
しかし、もしアプリケーションコードが先にデプロイされると、 Proctor はフォールバックし、テストを無効なものとして扱う。これは、もし、無効なバケットの値を -1 にマップするという慣例にしたがっている場合の話である。
テスト仕様内で fallbackValue を望ましいバケット値に設定することで、フォールバックの挙動が変更可能になる。
テストグループとコントロールグループが予期せぬサイズに変わらないことを保証するために、私たちは、ログをとっていない無効なグループにフォールバックすることを慣例としているのだ。
仮に、月曜から木曜に実行されるテストに対し、グループ 0 (コントロール) と 1 (テスト) があるとして、グループ 0 にフォールバックが設定されているとする。
もし、このテスト・マトリックスが火曜の 2 pm から 5 pm の間、何らかの変更の結果、壊れていたとすると、月曜から木曜までの全期間におけるメトリクスの合計が、コントロールグループの結果をゆがませてしまうのだ。
もし、フォールバックが -1 (無効) に設定されていれば、コントロールおよびテストグループに対するゆがみは発生することはない。
テストに新規バケットを追加する際、通常以下のような一連のアクションを実行している。
- 新規バケットにアロケーションを持たないテスト・マトリックスをデプロイ。
- 新規バケットの存在を認識しているアプリケーションコードをデプロイ。
- そのバケットに対するアロケーションを持つマトリックスを再度デプロイ。
もし、新規バケットのアロケーションを持つマトリックスがデプロイされ、アプリケーションがその存在を認識していない場合、 Proctor は全てのケースでフォールバック値を使用し、問題が起きても、安全な範囲におさまるようにしてくれる。
Proctor をこういう風に作った理由は、ある場合において、一定期間にわたって不明なバケットを適用させる命令をアプリケーションにくださないようにするためである。これが、分析をゆがませる可能性があるからだ。
また、マトリックスから全テストを削除する際にも、同じような注意を払っている。
テストグループに「所属していないか」ではなく、
「所属しているか」をテストする
Proctor のコード生成は、テストグループへの所属を調べるための、使いやすいメソッドを提供してくれる。
そしてこれらのメソッドは、テストグループに 「所属していないどうか」 をテストするよりも、 「所属しているかどうか」 をテストするために、いつも使用したほうが良いということが解ってきた。
「所属していない」 ということに基づいた条件付きのコードを書いた場合、予期せぬ状況でその条件付きの挙動が生じるおそれがあるのだ。
例えば、仮に [50% control, 50% test] のスプリットが存在するとして、コード内には条件付き表現 !groups.isControl() があるとする。これは groups.isTest() と同等だ。
そして、テストのフットプリントを減らすため、比較用に同サイズのコントロールグループは残しつつ、テストのスプリットを [25% control, 50% inactive, 25% test] に変更するとする。
すると、条件の表現が groups.isTest() || groups.IsInactive() に等しくなる。
このロジックはおそらく、コントロールグループと無効のグループでは同じ挙動を維持する、という最初の目的とは違っているだろう。
この例でいうと、もし最初から groups.isTest() を使用していれば、予期せぬ挙動を紛れ込ませてしまうことを防げたはずである
バケット・アロケーションの進化
テスト・バケットにユーザーを割り当てることが、彼らに対するサイトの挙動に影響を与えることを、私たちはよく知っている。
テストがどんどん進化していくのに、Proctor だけでは、連続したページビューや、サイトへのビジットに対して、一貫したユーザー体験を保証することはできないのである。
そしてアロケーションを増減させる際には、ユーザーへの影響を慎重に考える必要がある。
通常の場合、一度ユーザーが特定のバケットに割り当てられたら、そこに紐づく挙動を、テスト期間中継続してユーザーに見えるようにしたい、と私たちは考える。
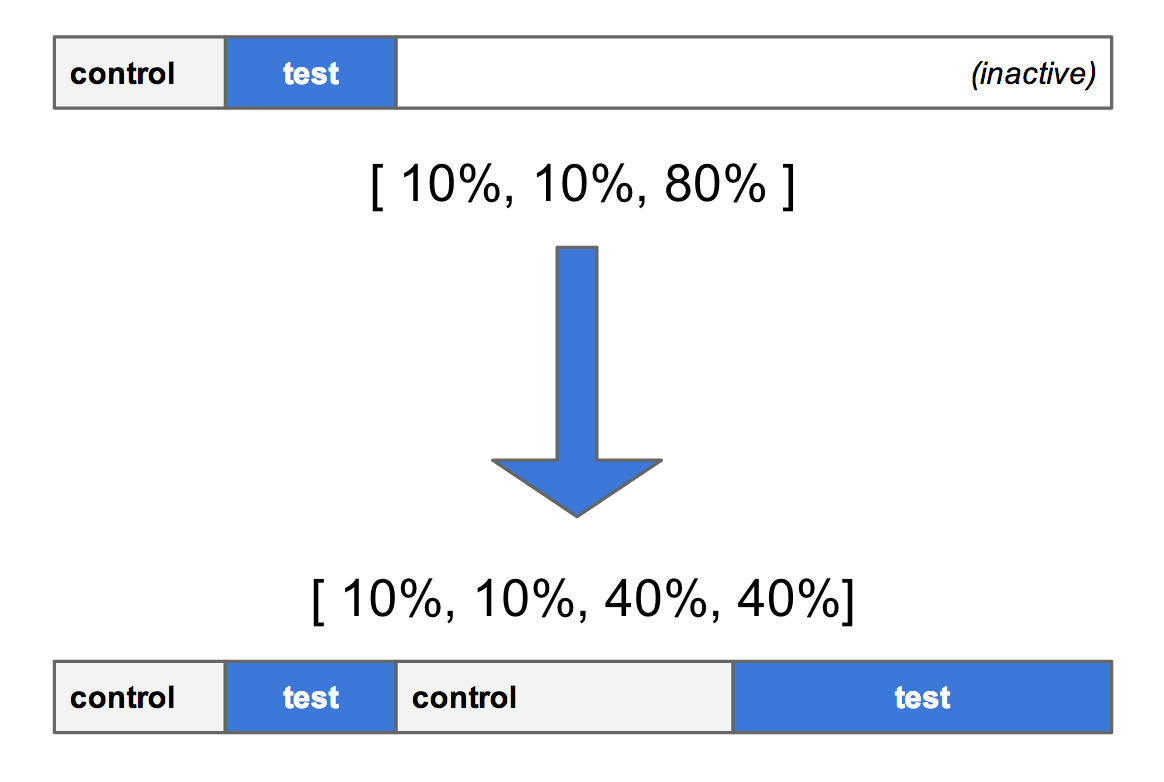
もしアロケーションが [10% control, 10% test, 80% inactive] で開始した場合、 [50% control, 50% test] に引き上げると、最初にテスト・バケットにいたユーザーがコントロール・バケットに移動してしまうので、これは避けたいと思うだろう。
バケットを安定して大きくしていくのに、 2 つの戦略が使われている。
「スプリット・バケット」 と呼ばれる戦略 (図 2) では、無効の範囲から 40% の塊を 2 つ取り出して、 10/10 から 50/50 に移行し、既存のバケットのために新規範囲を追加する。
その方法で出来た JSON が図 3 である。
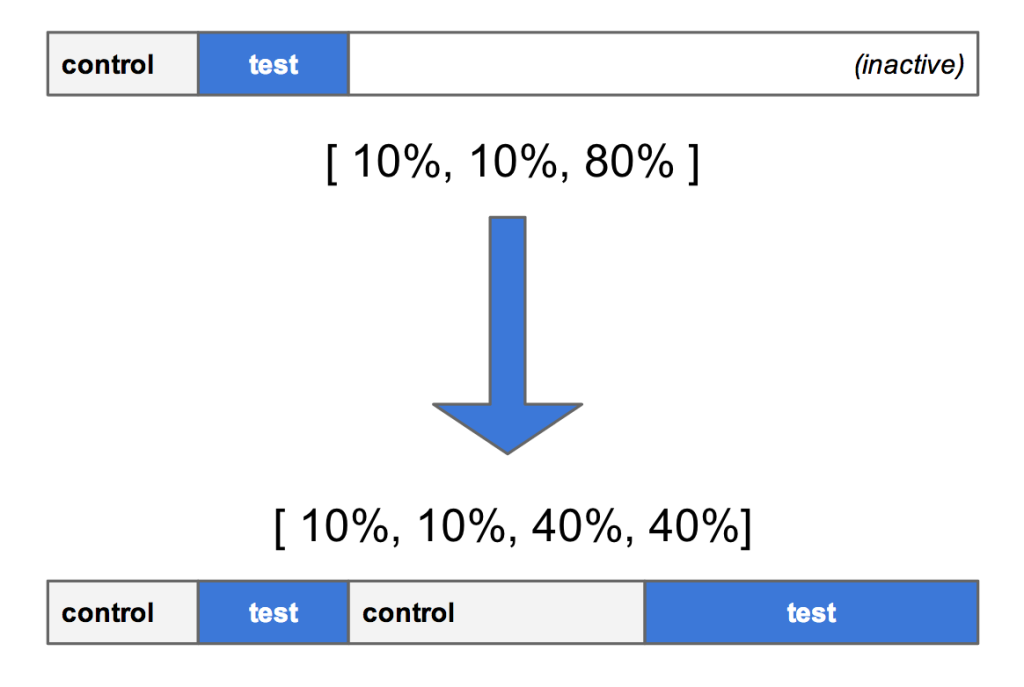
図 2 : 複数の範囲にバケットをスプリットし、コントロール/テストを拡大
"allocations": [
{
"ranges": [
{
"length": 0.1,
"bucketValue": 0
},
{
"length": 0.1,
"bucketValue": 1
},
{
"length": 0.4,
"bucketValue": 0
},
{
"length": 0.4,
"bucketValue": 1
}
]
}
]
図 3 : 「スプリット・バケット」 戦略のためのJSON。 0 がコントロールで 1 がテスト。
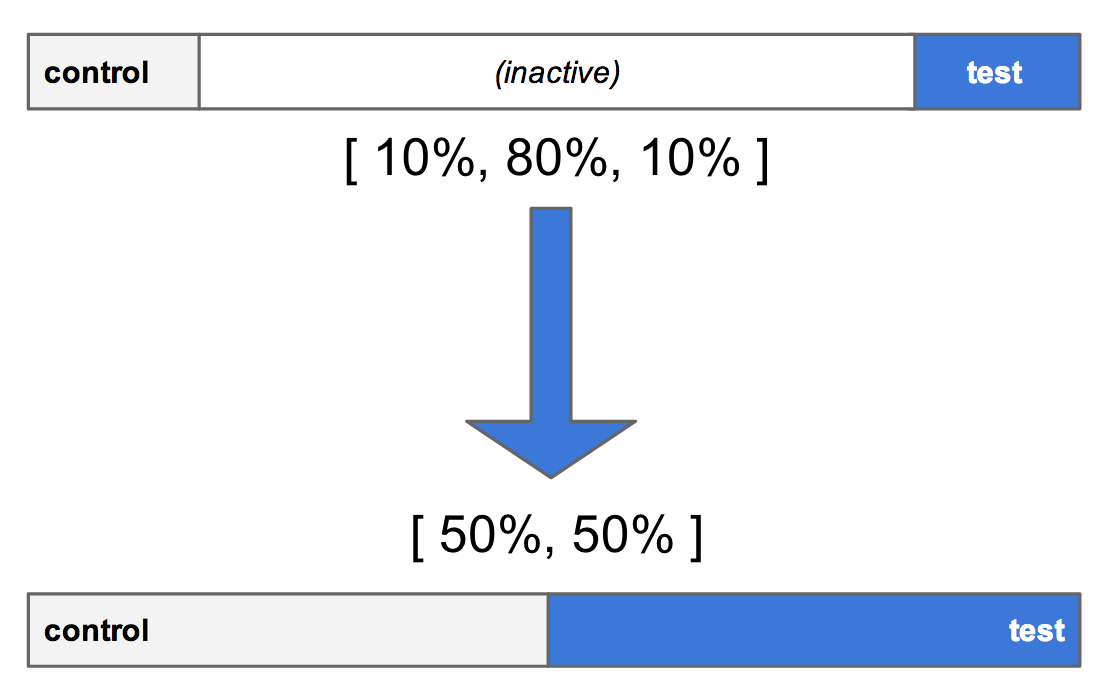
また、 「room to grow (ゆとり) 」 戦略では、バケット間に十分な無効のスペースを残すことで、図 4 のように、既存の範囲のサイズ調整ができる。
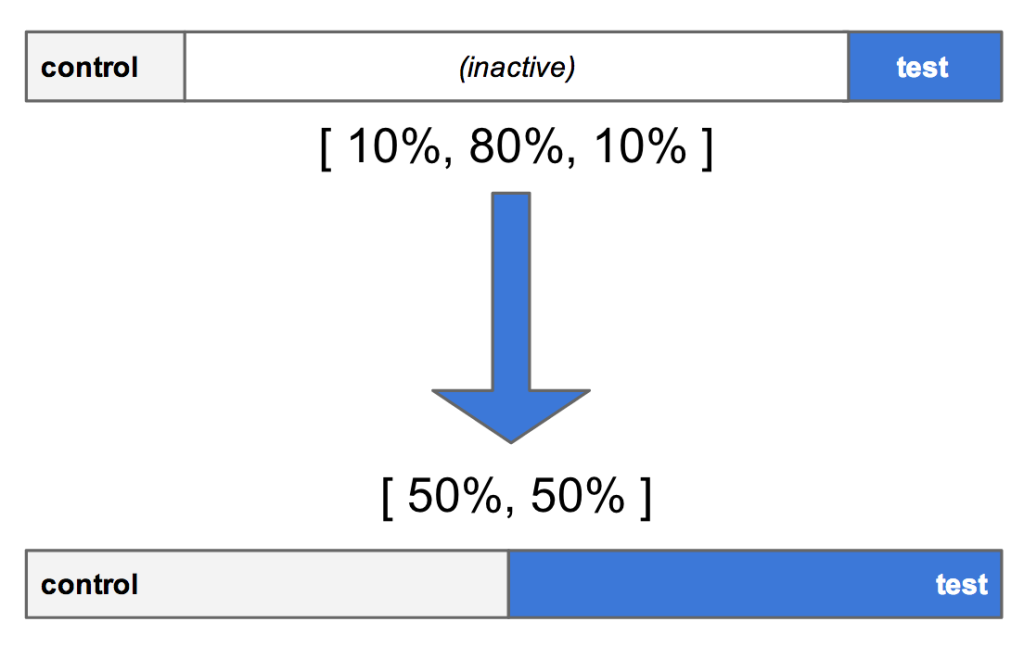
図 4 : 中間の無効部分に範囲の長さを更新し、コントロールとテストを拡大している
この 「ゆとり」 戦略を出来る限り使用することで、 JSON と Proctor Web アプリ両方に、より読みやすいテスト定義がもたらされるのだ。
便利なヘルパー・ユーティリティ
Proctor は Web アプリケーションのデプロイメントにおいて、 Proctor との作業をしやすくする、下記のようなユーティリティを提供している。
- Spring controller下記の3種類のビューを提供;
① 現在のリクエストのグループ
② 現在のテスト・マトリックスの要約版
③ アプリケーションのテスト仕様で定義されているテストだけを含むJSONのテスト・マトリックス
私たちは、特別な権限を持った IP アドレスにのみ、本番環境でこれらのユーティリティにアクセスできるように許可しており、ユーザーの皆さんにも同様の設定を推奨したい。
あなたの会社でもきっと役立つ
Proctor は Indeed でのプロダクト開発における、データ・ドリブンなアプローチにとって必要不可欠なものとなった。
現在本番には、 100 件以上のテストと 300 件以上のテストのバリエーションが存在している。
Proctor のご利用を始めるには、クイックスタートガイドを是非ご覧いただきたい。
ソースコードを読み込んでみたい方、またはご自身の拡張を貢献してくださる方は、 GitHub のページへどうぞ。